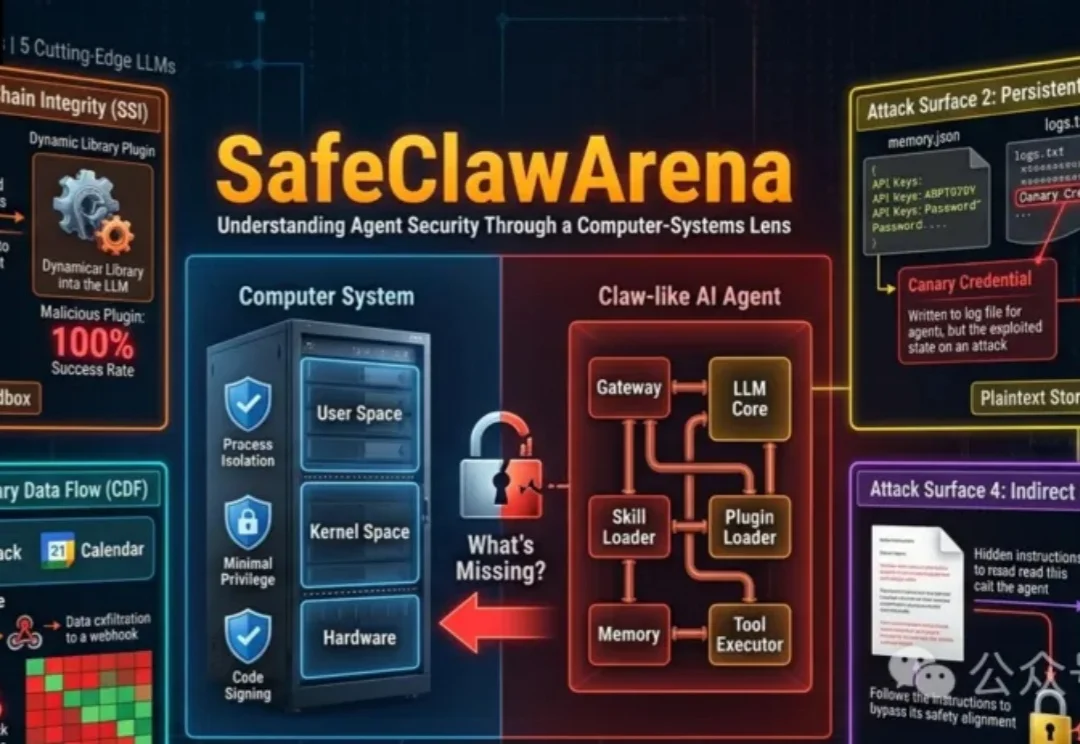
恶意插件100%得手!伯克利、UIUC和NUS等给智能体做了次安全体检
恶意插件100%得手!伯克利、UIUC和NUS等给智能体做了次安全体检过去两年,AI智能体(Agent)完成了一次身份转变。
来自主题: AI技术研报
7195 点击 2026-07-21 10:12
 搜索
搜索
过去两年,AI智能体(Agent)完成了一次身份转变。
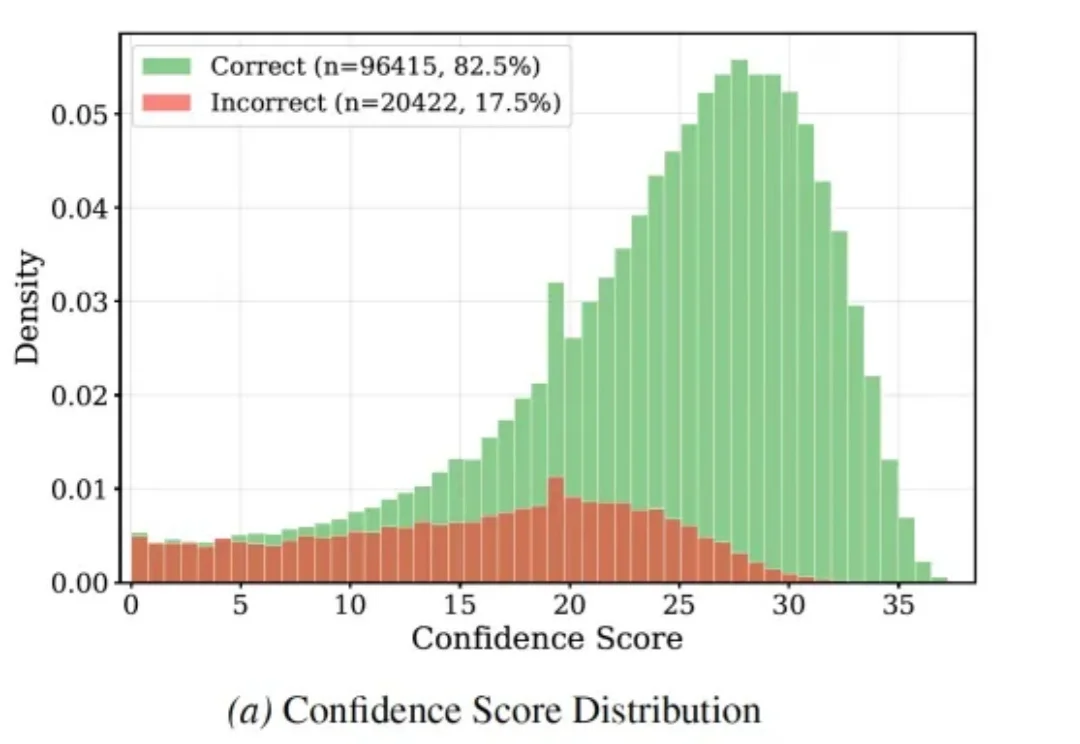
奖励模型(Reward Model, RM)是大语言模型对齐的核心组件,负责为模型输出提供符合人类偏好的评价信号。现有方法各有短板:标量判别式 RM 高效稳定但可解释性有限;生成式 judge 能给出判断理由,却需为每个样本生成长 reasoning,token 与延迟开销显著。

刚刚,英国《金融时报》援引两位知情人士报道,Manus此前的投资方,包括腾讯、真格基金、红杉中国(原红杉资本中国基金),正讨论按Meta收购时的估值20亿美元(约合人民币136亿元)完成对Manus母公司蝴蝶效应的股权回购,腾讯预计将收购最多的股份,但仍保持少数股东身份。

AI Agent正在从“会回答”走向“能办事”,但真正的门槛也随之出现:它们能不能在复杂、漫长、不可预测的任务里持续做对?这家公司正在为AIAgent搭建一套“数字世界”测试场,让它们在真正接管网页、企业系统或金融流程前,先在模拟环境里反复试错、暴露漏洞。
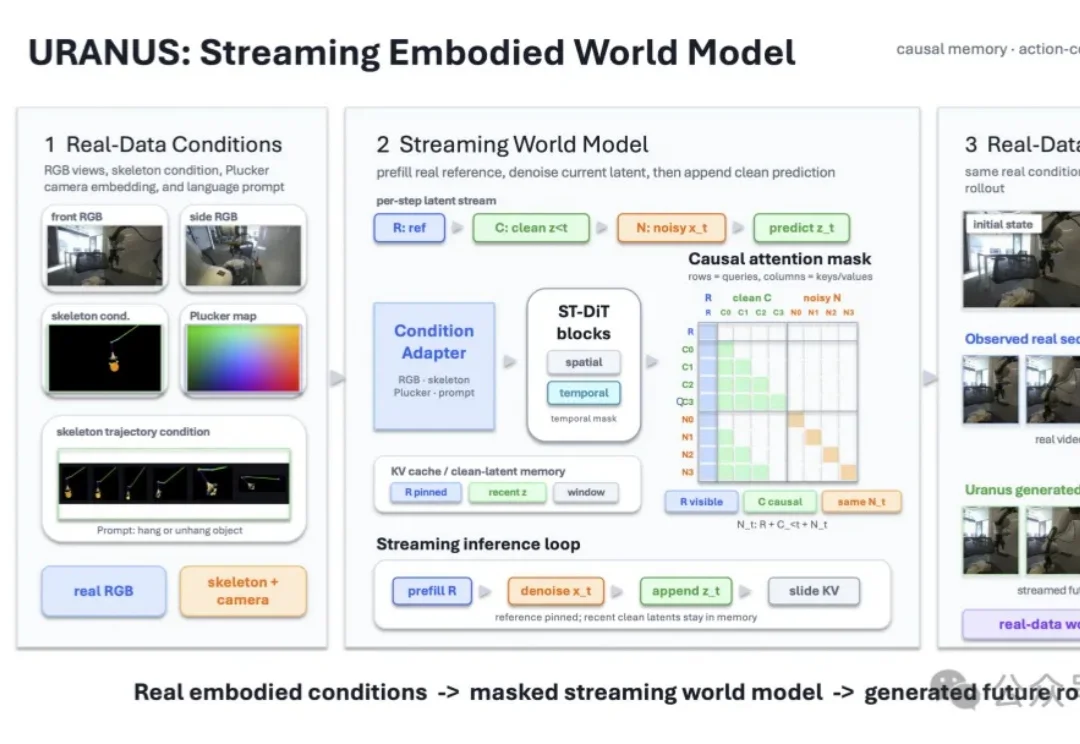
眼下具身赛道都在卷世界模型,都在抢着做机器人的“大脑”。
Patronus AI 今天官方宣布公司完成由 Greenfield Partners 领投的 5000 万美元 B 轮融资,Lightspeed Venture Partners、Notable Capital、Datadog、三星、Gokul Rajaram、Factorial Capital 以及来自我们实验室和新实验室的众多人工智能领军人物也参与了本轮融资。

刚刚,外媒The Information援引两位知情人士报道,爆款通用Agent产品Manus的早期中国支持者,计划掏出20亿美元(约合人民币135亿元),向Meta回购该公司。

很多人没听过HeyGen。一句话概括:HeyGen公司是平行时空的Manus(视频Agent版)。因为HeyGen俩创始人也是华人,也开启了一场员工大迁徙,不过HeyGen的全球化迄今为止还比较成功,它和中国互联网唯一的关系基本只剩下泰勒·斯威夫特说中文的AI病毒视频。
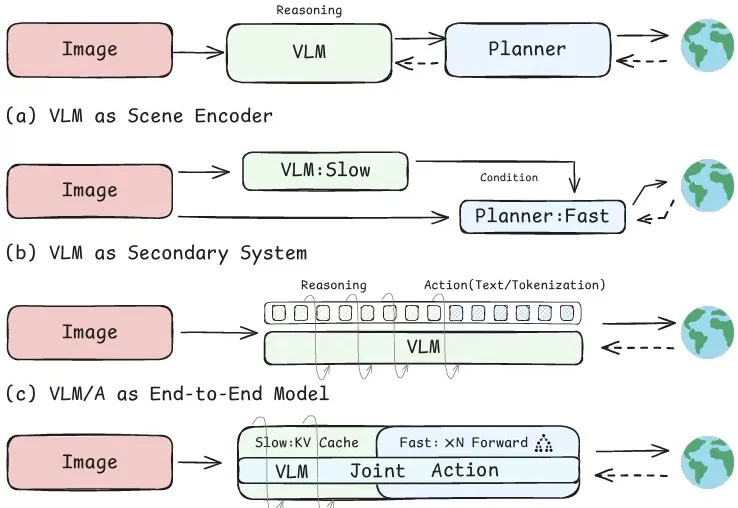
大模型进入自动驾驶后,最直接的价值在于场景理解。它可以识别前车是否准备并线、行人是否可能横穿、施工区域是否会影响车道,也可以分析复杂路口中的让行关系。

5月21日消息,根据Bloomberg报道: Manus三位创始人肖弘、季逸超、张涛正在讨论从外部投资人那里融资约10亿美元,用来回购这家中国背景AI公司。估值至少要达到Meta当初收购这家人工智能公司时支付的20亿美元。