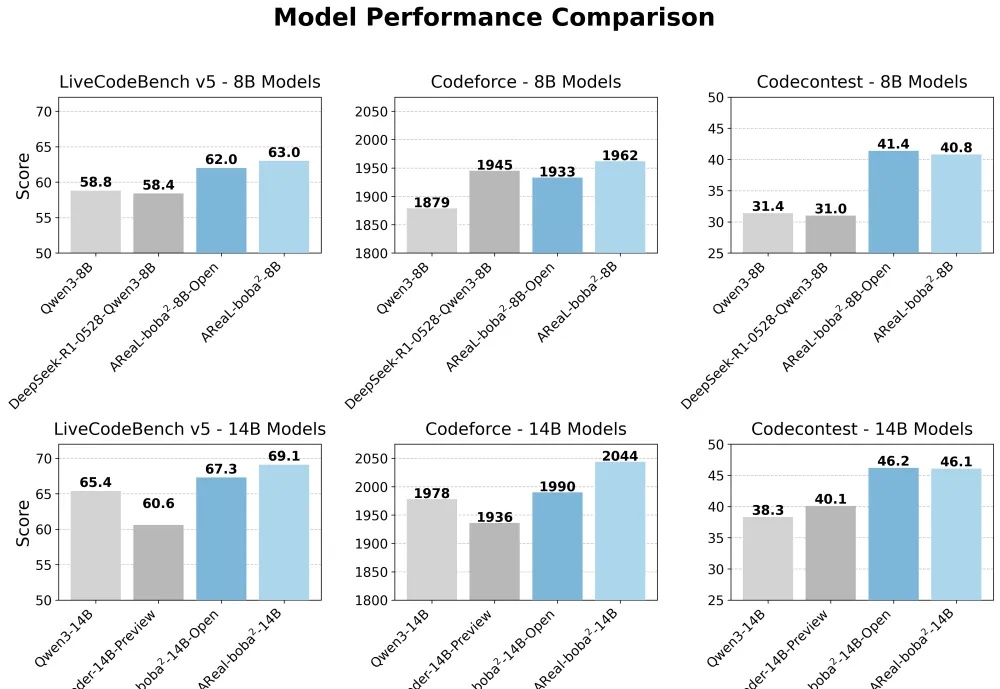
重磅开源!首个全异步强化学习训练系统来了,SOTA推理大模型RL训练提速2.77倍
重磅开源!首个全异步强化学习训练系统来了,SOTA推理大模型RL训练提速2.77倍想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
来自主题: AI技术研报
8668 点击 2025-06-04 14:05
 搜索
搜索
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
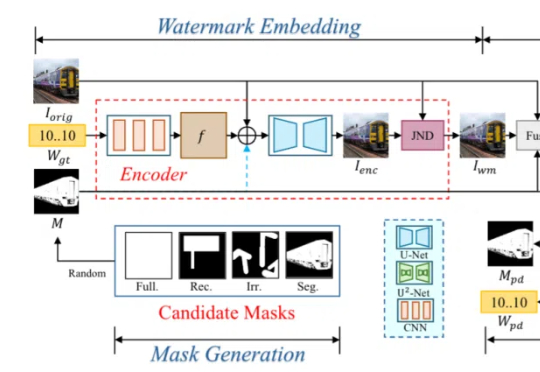
给AI生成的作品打水印,让AIGC图像可溯源,已经成为行业共识。

FLUX.1 Kontext是一款融合即时文本图像编辑与文本到图像生成的新一代模型,支持文本与图像提示,角色一致性强,速度快达GPT-Image-1的8倍。
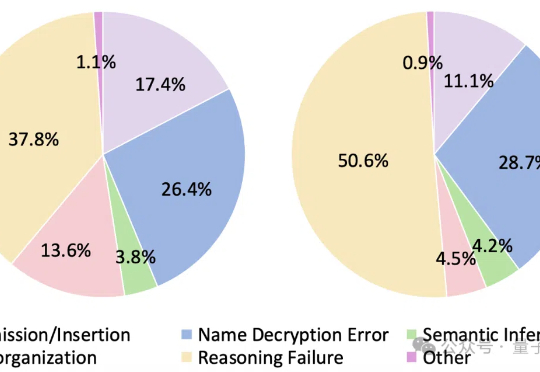
大语言模型遇上加密数据,即使是最新Qwen3也直冒冷汗!
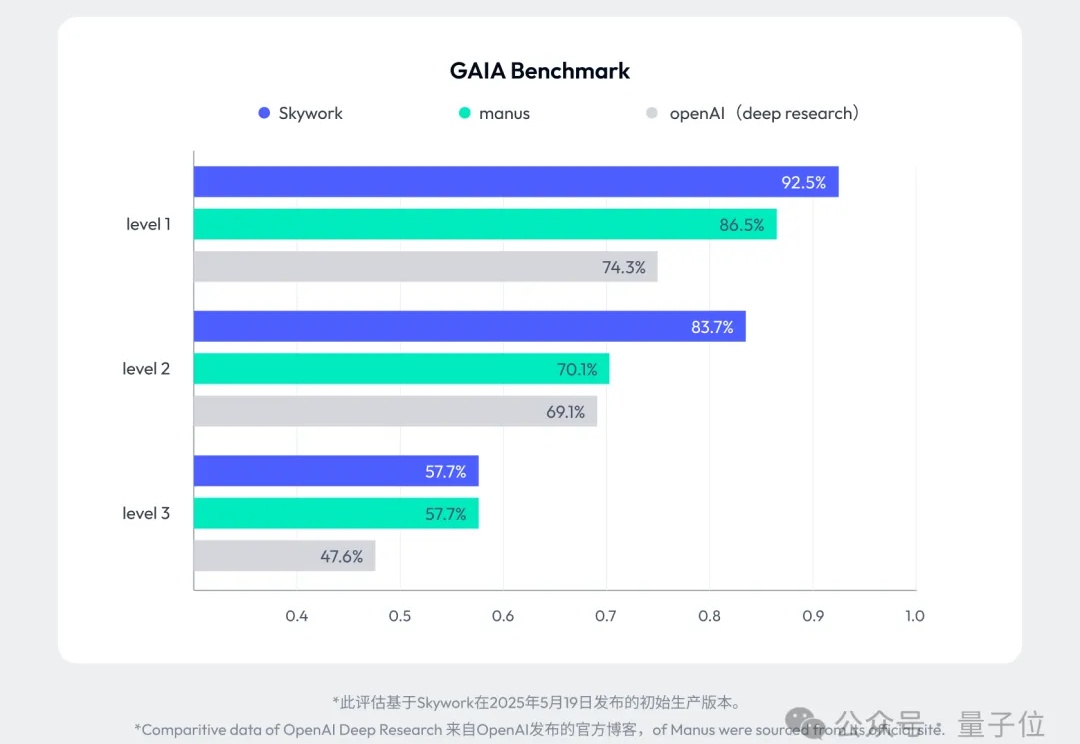
左超Manus,右跨Genspark,GAIA榜单上又一家中国公司登顶!
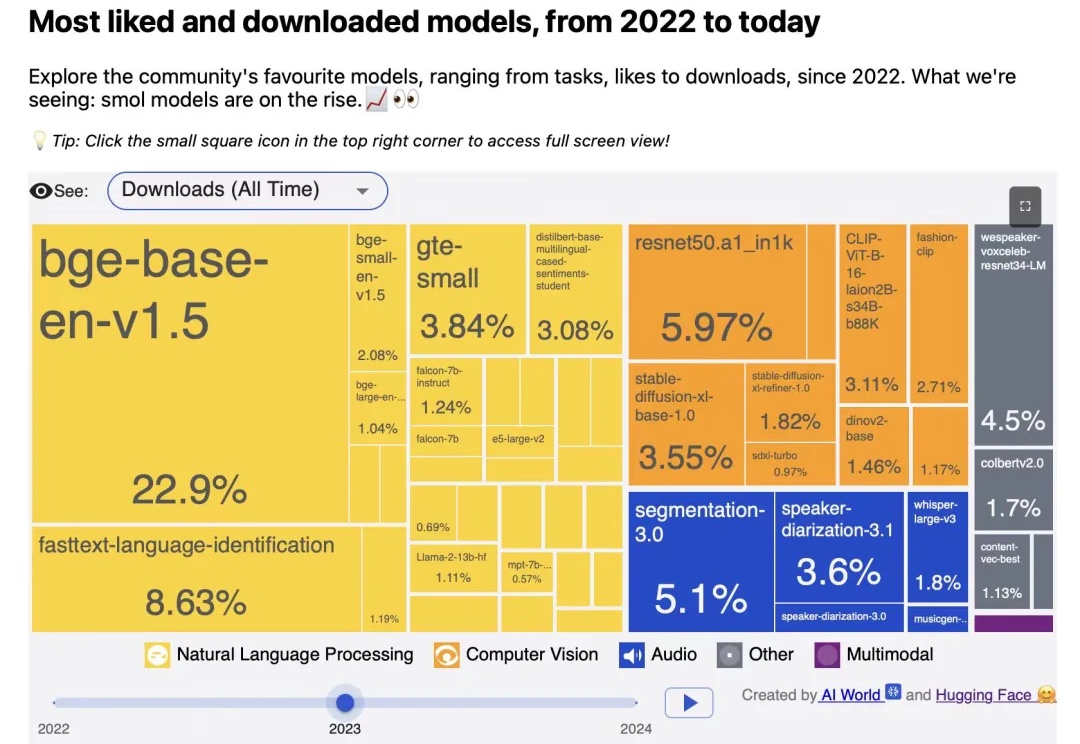
检索增强技术在代码及多模态场景中的发挥着重要作用,而向量模型是检索增强体系中的重要组成部分。

就在刚刚,智源研究员联合多所高校开放三款向量模型,以大优势登顶多项测试基准。其中,BGE-Code-v1直接击穿代码检索天花板,百万行级代码库再也不用怕了!
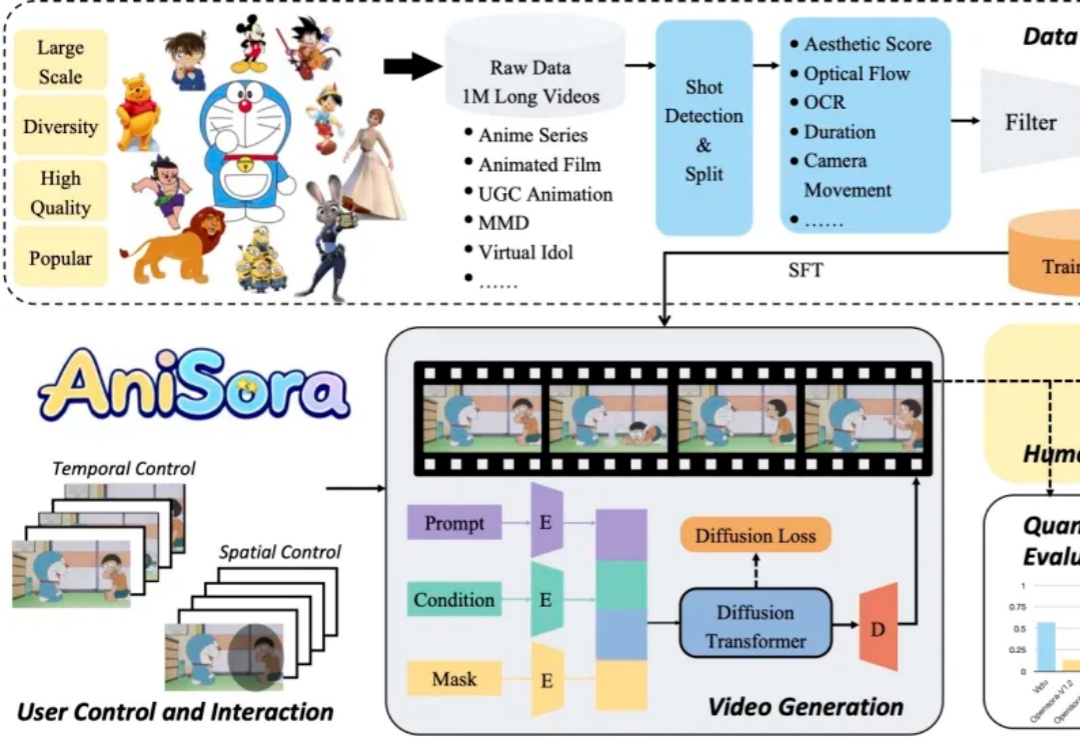
B 站开源动画视频生成模型 Index-AniSora,支持番剧、国创、漫改动画、VTuber、动画 PV、鬼畜动画等多种二次元风格视频镜头一键生成!
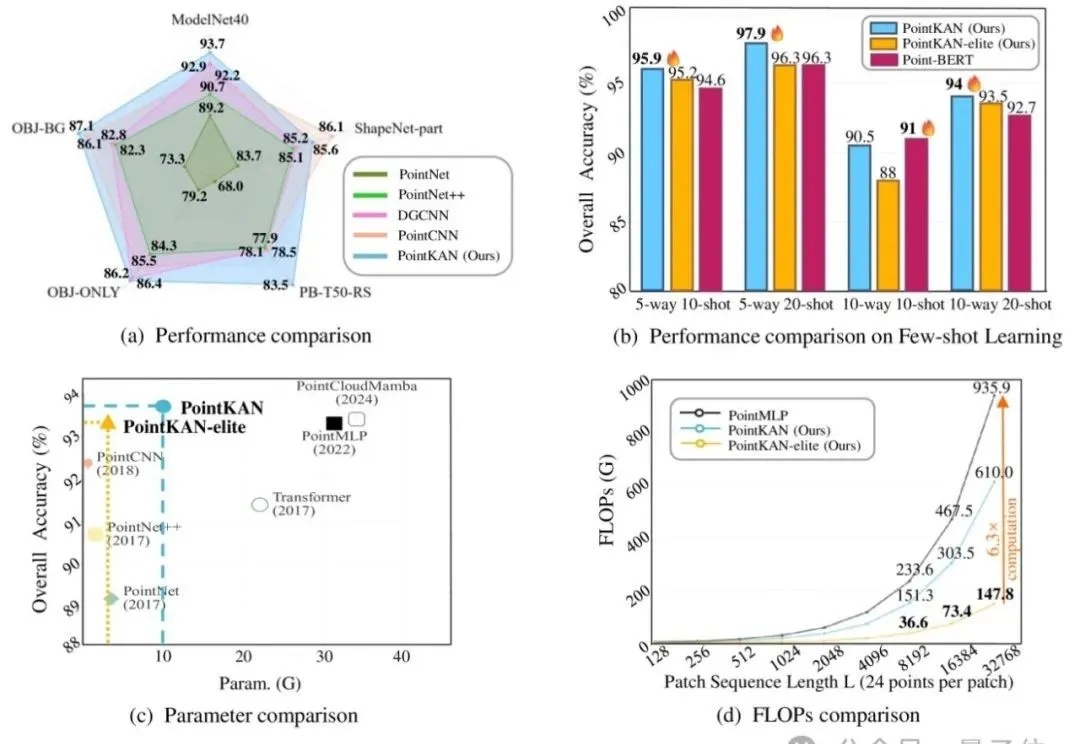
新架构选择用KAN做3D感知,点云分析有了新SOTA!

统一图像理解和生成,还实现了新SOTA。