# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
清华与蚂蚁联合开源AReaL-boba²,实现全异步强化学习训练系统,有效解耦模型生成与训练流程,GPU利用率大幅提升。14B模型在多个代码基准测试中达到SOTA,性能接近235B模型。异步RL训练上大分!
还记得今年初DeepSeek‑R1系列把纯强化学习(RL)训练开源,点燃社区对于RL的热情吗?
不久后,来自清华蚂蚁联合开源项目AReaL(v0.1)也通过在DeepSeek-R1-Distill-Qwen-1.5B上进行RL训练,观察到模型性能的持续提升。
AReaL(v0.1)在40小时内,使用RL训练的一个1.5B参数模型,在数学推理方面就超越了o1-Preview版本。
研究人员发现,RL在构建大型推理模型(LRM)方面确实有「奇效」,但是传统的同步RL却有着「昂贵」的代价——效率很低,无法充分利用推理设备性能。
6月3日,清华蚂蚁联合研发的全异步强化学习训练系统AReaL-boba²(即AReaL v0.3)正式开源,这是AReaL的第三个版本,也是其里程碑版本AReaL-boba的重磅升级,直指RL训效提升靶心!
AReaL-boba²在经过两个版本的迭代后,进化出多项重要能力:

开源地址:https://github.com/inclusionAI/AReaL
技术论文:https://arxiv.org/pdf/2505.24298
模型下载:https://huggingface.co/collections/inclusionAI/AReaL-boba-2-683f0e819ccb7bb2e1b2f2d5
寻找兼顾高效能、高效率的强化学习训练方式,一直是从业人员持续面临的课题。
异步强化学习是一种重要的算法范式,将成为未来强化学习的重要方向之一。这次清华和蚂蚁联合开源的AReaL-boba²以及一系列实验效果,验证了这方面的共识。
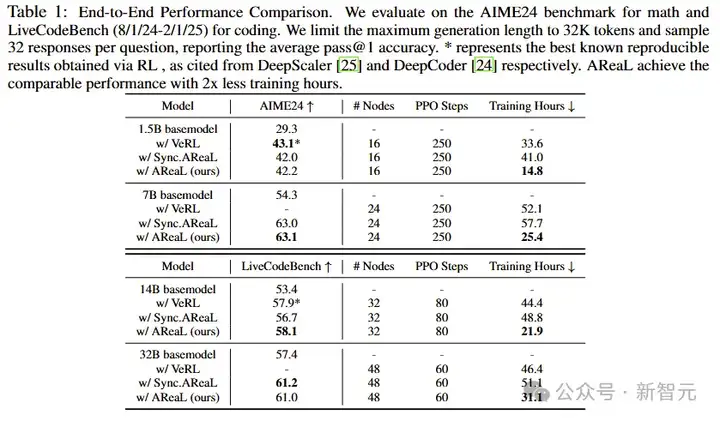
首先来看AReaL-boba²在多个测试基准上的性能对比。研究人员使用这一系统在Qwen3系列模型上做强化学习训练。
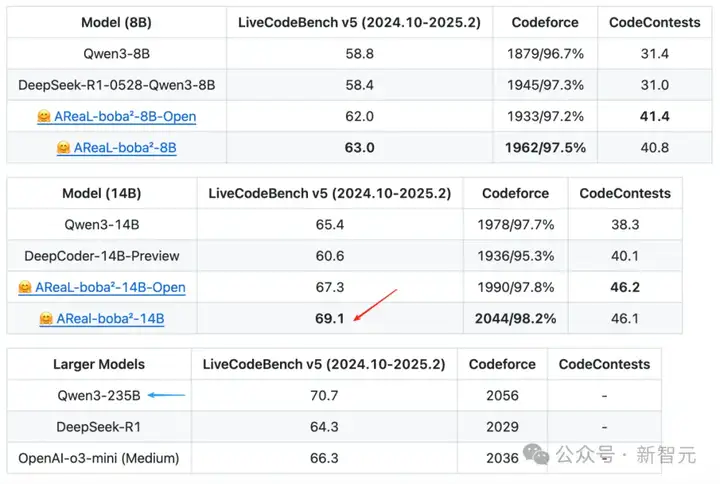
其中,AReaL-boba²-8B/14B-Open表示在开源数据上的训练结果;AReaL-boba²-8B/14B模型则额外使用了少量内部数据进行训练。
AReaL-boba²-8B/14B在LiveCodeBench、Codeforce和CodeContests上实现了SOTA。
最厉害的是在LiveCodeBench-v5上得分为69.1的14B模型,已经接近Qwen3-235B的性能!要知道这可是14B VS 235B的较量。
同时AReaL-boba²-8B模型的得分也有63分,已经接近DeepSeek-R1的水准!
在传统的强化学习训练流程中,同步强化学习训练每一个batch的数据都是由最新版本模型产生,因此模型参数更新需要等待batch中数据全部生成完成才能启动。
由于推理模型的输出长短差异极大,在同样的批大小(batch size)下,强化学习训练必须等待batch中最长的输出生成完才能继续进行训练,以及进行下一个batch的数据收集,这样,就会造成极大的GPU资源浪费。
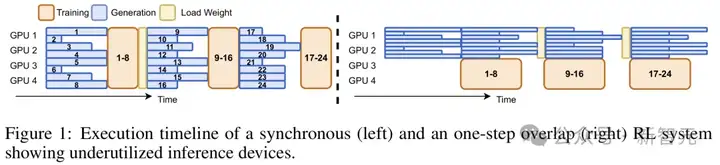
左侧为同步RL训练的执行时间线:同batch输出(蓝色)需要等待其中最长的输出生成完成,存在大量GPU空闲
DeepCoder,Intellect-2等使用从前一模型版本生成的输出来更新当前模型,从而在单步上重叠生成与训练。然而,所有这些系统仍然遵循批量生成设置,在生成阶段期间系统效率低下的问题仍未得到有效解决。
图1右侧为一步重叠RL系统的执行时间线,单模型训练与单batch数据收集同时进行。同batch内依然存在大量GPU空闲。
为了从根本上解决以上这些系统设计中的问题,清华和蚂蚁的联合研究团队开发了AReaL-boba²,一个面向大型推理模型(LRM)的完全异步强化学习训练系统,它完全解耦了生成与训练,在不影响最终性能的同时,实现大幅度加速。
而AReaL-boba²之所以能实现高GPU利用率,就是因为它以流式方式执行LRM生成,让每个rollout worker能不断生成新的输出,无需等待。
同时,AReaL-boba²中的trainer worker会并行地在从rollout worker获得生成完成的数据构成训练batch,用来更新模型。一旦模型更新完成,新的模型权重会更新到每个rollout worker中。
值得注意的是,在这种异步设计中,AReaL-boba²中的每个训练batch可能包含由不同过去模型版本生成的样本。在实践中,训练数据的陈旧性可能会导致RL算法训练效果不佳,为此研究者们提出了算法改进以保证训练效果。
结果显示,完成数学推理和代码任务时,在高达320亿参数的模型上,AReaL-boba²的训练吞吐量最高可提高2.77倍,训练效率在512块GPU上实现了线性扩展。
关键点在于,这种加速甚至还带来了解题准确性的提升,这就表明,AReaL-boba²并不需要牺牲模型性能,就能显著提升效率!
系统架构
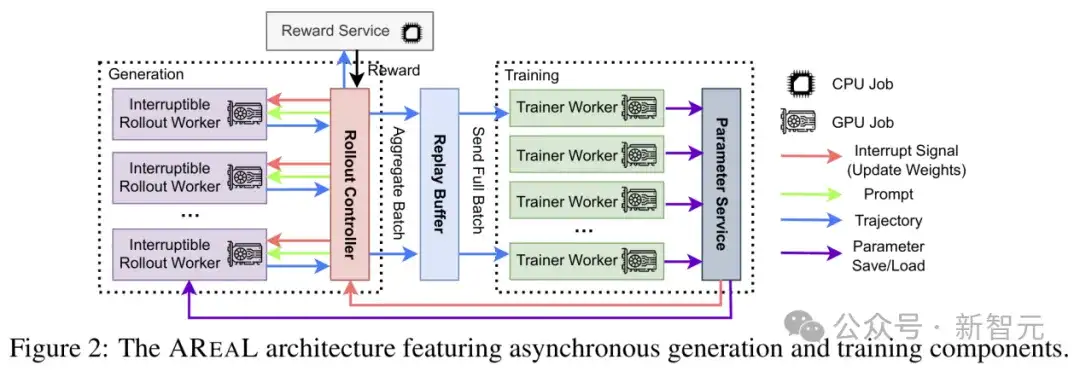
AReaL的架构与数据流
AReaL-boba²系统由四个核心组件组成:
1. 可中断的采样工作器(Interruptible Rollout Worker)
它负责处理两类请求:
(1)generate请求:根据提示词生成响应;
(2)update_weights请求:中断当前所有生成任务,并加载新版本模型参数。
在权重更新时,采样工作器会丢弃旧权重生成的KV缓存,并使用新权重重新计算。随后,采样工作器将继续解码未完成的序列,直到下一次中断或任务终止。
这种在生成中途打断并切换模型权重的机制,将导致一条轨迹由多个不同模型版本生成的片段组成。当然,这也带来了新的算法挑战。
2. 奖励服务(Reward Service)
用于评估模型生成响应的准确性。
例如,在代码任务中,该服务会提取生成的代码并执行单元测试,以验证其正确性。
3. 训练工作器(Trainer Workers)
这个组件会持续地从重放缓存(replay buffer)中采样数据,直到累积到训练所需的batch大小为止。
随后,它们将执行PPO更新,并将更新后的模型参数存储到分布式存储系统中。
4. 采样控制器(Rollout Controller)
它是采样工作器、奖励服务与训练工作器之间的重要桥梁。在训练过程中,它从数据集中读取数据,向采样工作器发送generate 请求,获取模型生成的结果。生成结果随后会被发送至奖励服务进行评估,以获取对应的奖励值。
包含奖励的轨迹会被存入重放缓存,等待训练工作器进行训练。当训练工作器更新完模型参数后,控制器会向采样工作器发送update_weights请求,将最新权重加载至采样工作器中。
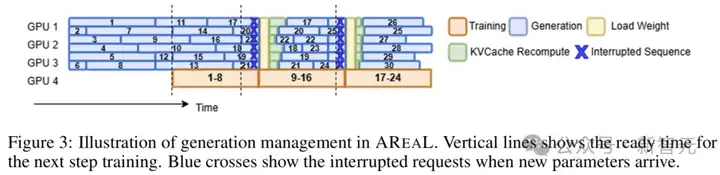
AReaL的生成与训练的管理流程
虽然异步系统设计通过提高设备利用率提供了显著的加速效果,但它也引入了一些需要从算法层面考量的技术挑战。
· 数据陈旧性
由于AReaL-boba²的异步特性,每个训练batch都包含来自多个先前策略版本的数据。数据陈旧性会导致训练数据与最新模型的输出之间出现分布差距。在针对LRM的异步RL训练中,由于解码时间延长,此问题对于长轨迹可能会更加严重。
· 策略版本不一致
如上图3所示,单个生成的轨迹可能包含由不同模型版本生成的片段。这种不一致性从根本上违背了标准PPO的公式化假设,即所有数据都由单一模型生成。
为了解决这两个挑战,AReaL-boba²提出了两种关键解决方案:
1. 陈旧性控制
为了避免数据陈旧性问题带来的负面影响,AReaL-boba²限制生成轨迹的策略版本与训练策略之间的版本差异。AReaL引入了一个超参数η,用于表示允许的最大陈旧程度。当η=0,系统退化为同步强化学习设置,此时生成与训练batch完全匹配。
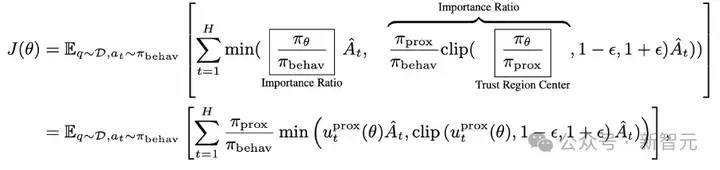
2. 解耦的PPO目标
团队应用了一个解耦的PPO目标,将行为策略和代理策略分离,其中行为策略表示用于采样轨迹的策略,而代理策略是一个近端策略,作为最近的目标,用于规范在线策略的更新。
首先在一个数学任务上评估异步AReaL-boba²,在之前发布的AReaL-boba(v0.2)基础上,采用R1-Distill-Qwen作为基础模型,并使用AReaL-boba-106k作为训练数据集。
端到端性能对比
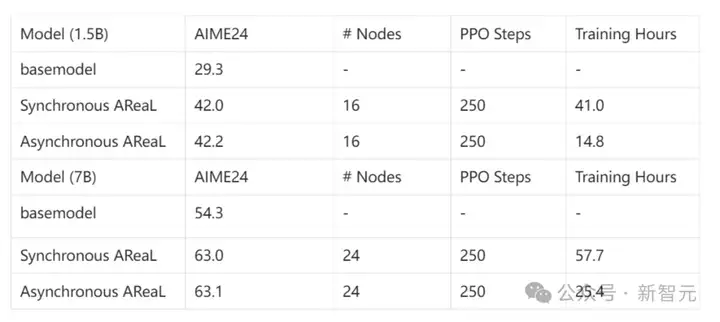
团队比较了在1.5B和7B参数模型上的同步与异步训练。
结果显示,在资源限制和训练步骤相同的情况下,异步系统速度是同步系统的两倍多!
在AIME24上的评估,证实了这一加速并未影响性能。
可以看到,AReaL-boba²在性能上始终与基线持平甚至超过,并且训练速度有显著提升。
特别是在训练吞吐量方面,AReaL-boba²相较于同步方法最高可实现2.77倍的提升,且几乎无性能损失。
研究者在数学任务上基于一个1.5B的大型推理模型(LRM),开展了消融实验,以验证他们所提出算法创新。
他们调整了允许的最大staleness η,并比较使用和不使用解耦式PPO目标函数的不同配置。结果表明,陈旧性控制有效地避免了过旧的数据带来的负面影响,同时使用解耦PPO目标可以在陈旧程度大的情况下保持训练效果。
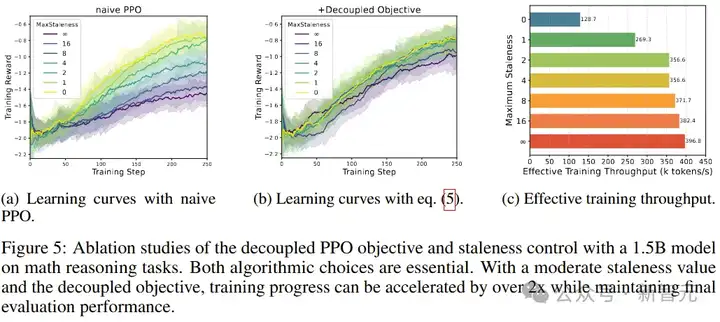
(a)和(b)分别为使用传统PPO以及解耦PPO目标进行训练的曲线
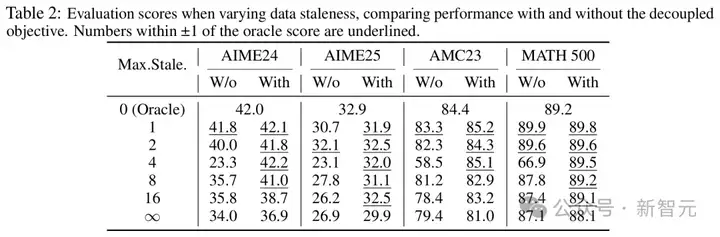
解耦PPO目标的消融实验
此前,联合研究小组在3月开源的AReaL-boba项目,得到了来自海外开发者的高度认可,评价「AReaL-boba通过开放SOTA推理模型的资源和透明的训练方式,让先进的AI推理技术平权化,降低了研究的门槛。 」
而AReaL-boba² 延续了一贯的完全开源原则,代码、数据集、脚本及 SOTA 级模型权重全部开源,团队希望 AReaL 能让AI智能体搭建像制作一杯奶茶一样便捷、灵活、可定制化。
AReaL团队在技术报告中表示,该项目融合了蚂蚁强化学习实验室与清华交叉信息院吴翼团队多年的技术积累,也获得了大量来自蚂蚁集团超算技术团队和数据智能实验室的帮助。
AReaL的诞生离不开DeepScaleR、Open-Reasoner-Zero、OpenRLHF、VeRL、SGLang、QwQ、Light-R1、DAPO等优秀开源框架和模型的启发。
最后,AReaL还给出了完善的训练教程和开发指南,包括复现SOTA代码模型训练指南以及基于Async RL的智能体搭建教程,想体验极速RL训练的小伙伴可以跑起来了!
参考资料:
https://github.com/inclusionAI/AReaL
文章来自于“新智元”,作者“Aeneas 定慧”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
