
让GPU不再摸鱼!清华蚂蚁联合开源首个全异步RL,一夜击穿14B SOTA
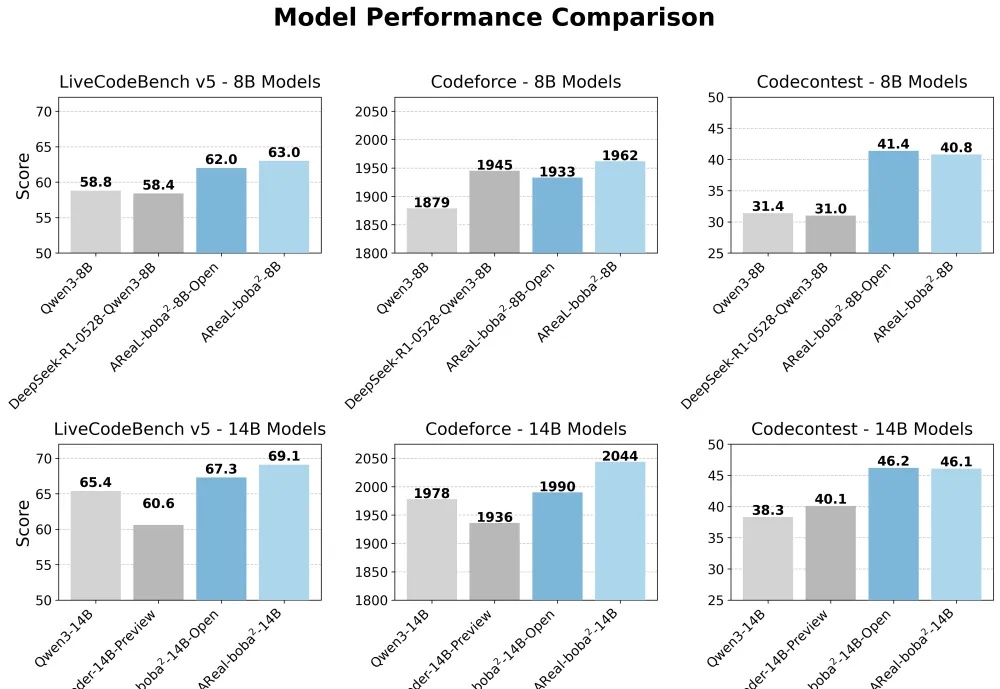
让GPU不再摸鱼!清华蚂蚁联合开源首个全异步RL,一夜击穿14B SOTA清华与蚂蚁联合开源AReaL-boba²,实现全异步强化学习训练系统,有效解耦模型生成与训练流程,GPU利用率大幅提升。14B模型在多个代码基准测试中达到SOTA,性能接近235B模型。异步RL训练上大分!
来自主题: AI技术研报
7679 点击 2025-06-05 16:30
 搜索
搜索
清华与蚂蚁联合开源AReaL-boba²,实现全异步强化学习训练系统,有效解耦模型生成与训练流程,GPU利用率大幅提升。14B模型在多个代码基准测试中达到SOTA,性能接近235B模型。异步RL训练上大分!
想训练属于自己的高性能推理模型,却被同步强化学习(RL)框架的低效率和高门槛劝退?AReaL 全面升级,更快,更强,更好用!
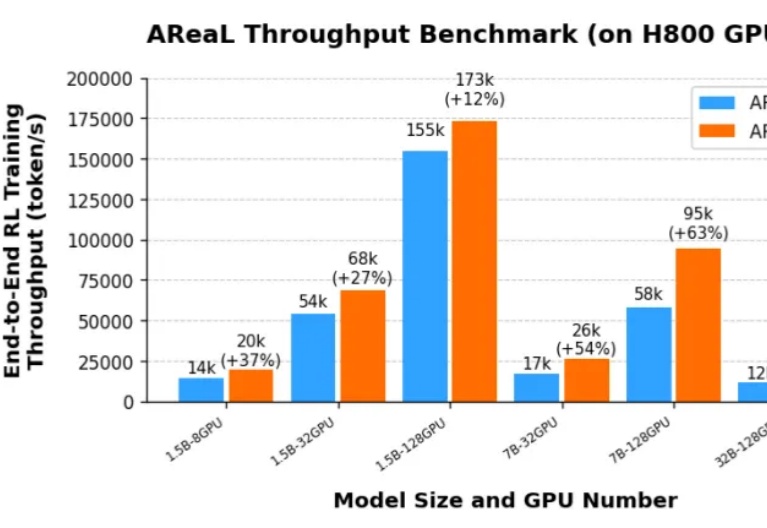
由于 DeepSeek R1 和 OpenAI o1 等推理模型(LRM,Large Reasoning Model)带来了新的 post-training scaling law,强化学习(RL,Reinforcement Learning)成为了大语言模型能力提升的新引擎。然而,针对大语言模型的大规模强化学习训练门槛一直很高: