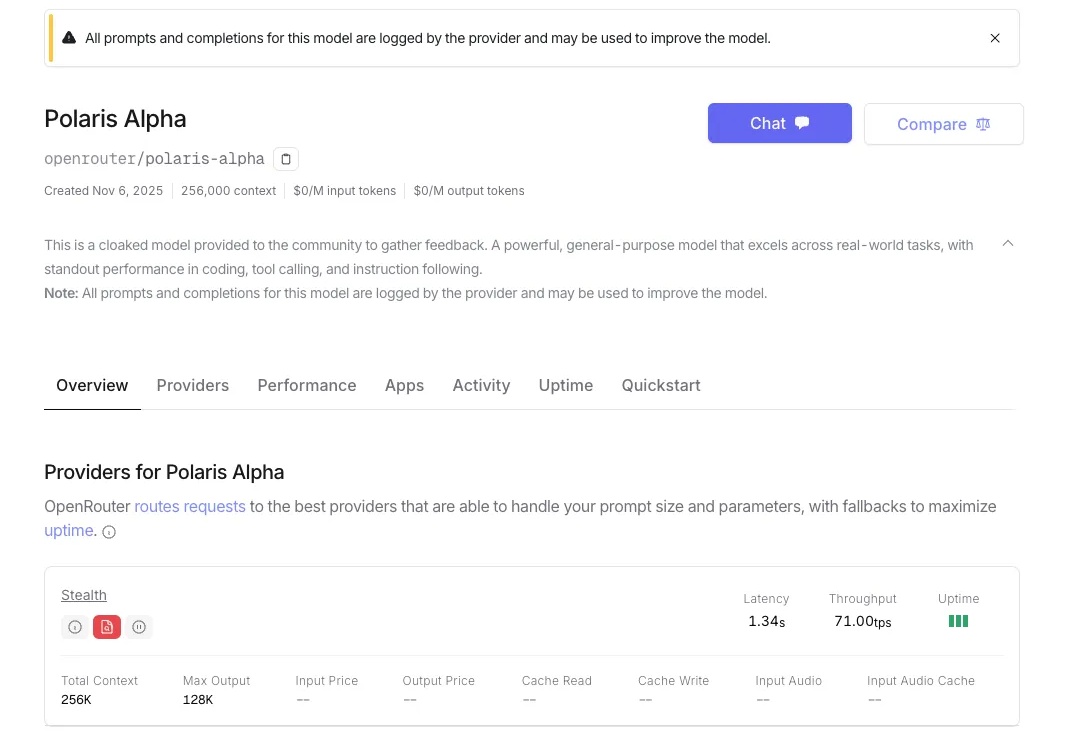
GPT-5.1 「马甲」泄露!现在免费就能用,年底 AI 一大波更新要来了
GPT-5.1 「马甲」泄露!现在免费就能用,年底 AI 一大波更新要来了Gemini 3 还没影子,GPT 5.1 已经在路上。7 号深夜,OpenRouter 平台上线了一个全新的隐名模型。已经有眼尖动作快的网友尝鲜体验,并且认为这就是披着马甲的 GPT 5.1,暂名:Polaris Alpha。
来自主题: AI资讯
8782 点击 2025-11-10 16:31
 搜索
搜索
Gemini 3 还没影子,GPT 5.1 已经在路上。7 号深夜,OpenRouter 平台上线了一个全新的隐名模型。已经有眼尖动作快的网友尝鲜体验,并且认为这就是披着马甲的 GPT 5.1,暂名:Polaris Alpha。
强化学习改变了大语言模型的后训练范式,可以说,已成为AI迈向AGI进程中的关键技术节点。然而,其中奖励模型的设计与训练,始终是制约后训练效果、模型能力进一步提升的瓶颈所在。
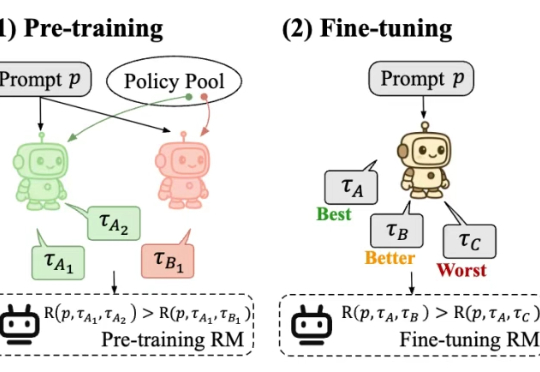
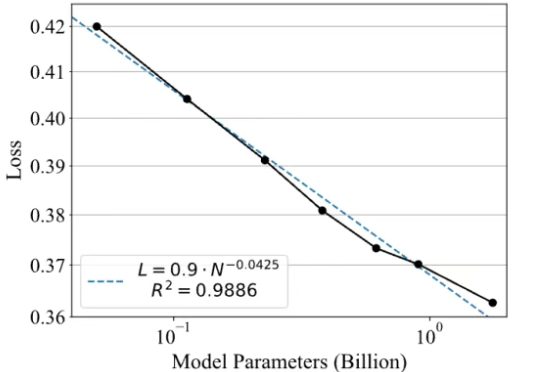
最近,一款全新的奖励模型「POLAR」横空出世。它开创性地采用了对比学习范式,通过衡量模型回复与参考答案的「距离」来给出精细分数。不仅摆脱了对海量人工标注的依赖,更展现出强大的Scaling潜力,让小模型也能超越规模大数十倍的对手。
香港大学NLP团队联合字节跳动Seed、复旦大学发布名为Polaris的强化学习训练配方:通过Scaling RL,Polaris让4B模型的数学推理能力(AIME25上取得79.4,AIME24上取得81.2)超越了一众商业大模型,如Seed-1.5-thinking、Claude-4-Opus和o3-mini-high(25/01/31)。

2025年5月,美国数字健康企业 Akido Labs 宣布完成6000万美元B轮融资,由 McKesson Ventures 和 Polaris Partners 联合领投,老股东 Andreessen Horowitz(a16z)与 SVB Capital 跟投。融资所得将主要用于扩大其核心平台 ScopeAI 的部署,尤其是在医疗资源匮乏的社区加速落地。

在今年1月《Journal of Supercomputing》上开源的「开源类脑芯片」二代(Polaris 23)完整版本源代码,基于RISC-V架构,支持脉冲神经网络(SNN)和反向传播STDP。该芯片通过并行架构显著提升神经元和突触处理能力,带宽和能效大幅提升,MNIST数据集准确率达91%。
近日, AI医学影像企业深智透医完成 B+ 轮近千万美元融资,投资方包括新进美元基金嘉加资本;深智透医联合创始人宫恩浩也是一位连续创业者,此前曾联合创办专业修图软件 Polarr 。