
从Memory到端侧Agent,OPPO正在寻找AI手机的下一块价值底座
从Memory到端侧Agent,OPPO正在寻找AI手机的下一块价值底座2026年的AI行业,正在出现一种微妙的变化。
来自主题: AI资讯
9093 点击 2026-06-03 09:26
 搜索
搜索
2026年的AI行业,正在出现一种微妙的变化。

一家叫泛灵人工智能的团队,出了一款主打「超级办公助理」的硬件产品。

在当前的 LLM 开发中,后训练阶段通常被视为赋予模型特定能力的关键环节。传统的观点认为,模型必须通过强化学习(如 PPO、GRPO 或 RLHF)和进化策略(ES)等算法,在反复的迭代和梯度优化过程中调整权重,才能在特定任务上达到理想的性能。
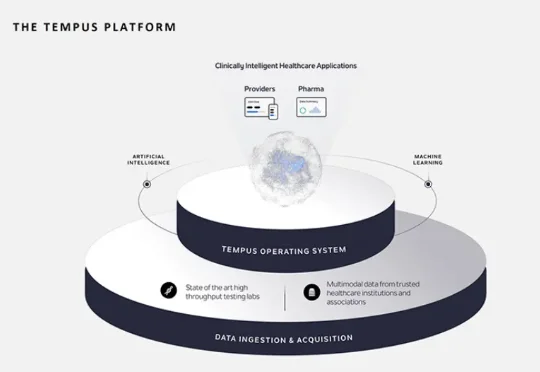
「中国巴菲特」段永平,押注AI医疗。 数据显示,段永平Q4买入了AI医疗公司Tempus AI,新进11万股。 段永平曾一手打造小霸王、步步高,还是OPPO、vivo的幕后奠基人;之后退居幕后转向投资

硬氪获悉,AI智能运动穿戴品牌「苔源MossCode」近日完成数千万元天使轮融资,本轮由XVC和清流资本共同投资。
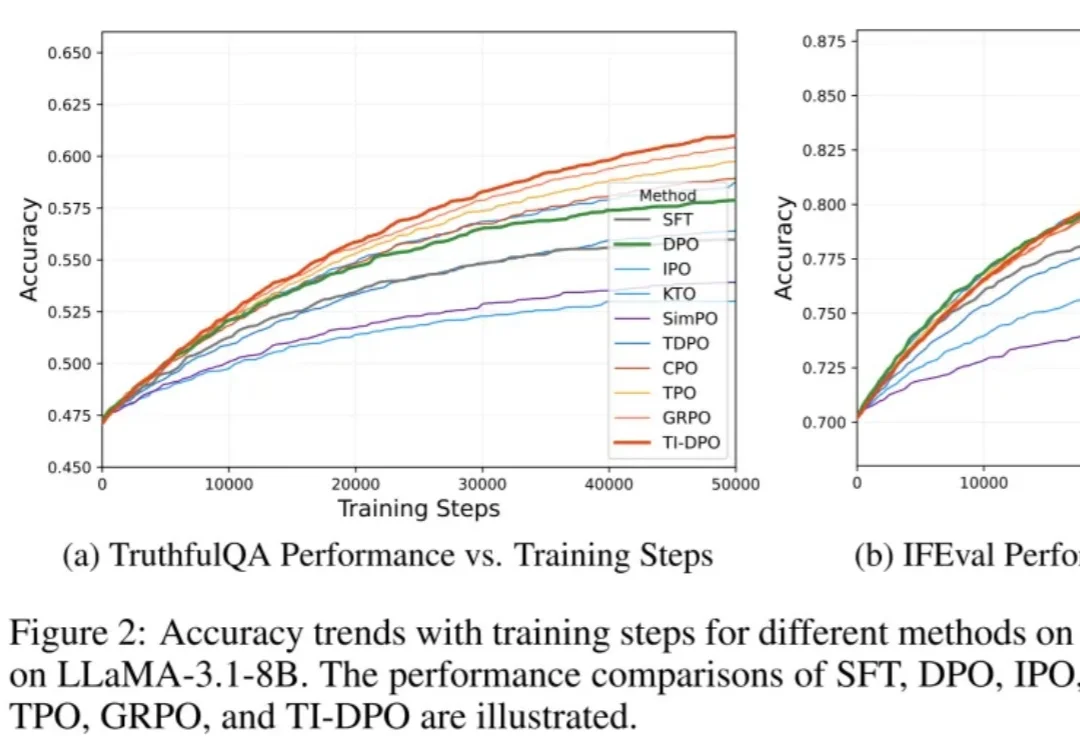
在当今的大模型后训练(Post-training)阶段,DPO(直接偏好优化) 凭借其无需训练独立 Reward Model 的优雅设计和高效性,成功取代 PPO 成为业界的 「版本之子」,被广泛应用于 Llama-3、Mistral 等顶流开源模型的对齐中。

全球人工智能(AI)热潮下,英国斯塔默政府在今年1月推出了雄心勃勃的“人工智能机遇行动计划”(AI Opportunities Action Plan),目标是成为“人工智能超级大国”。

AI 手机,做真正懂你的超级助理。
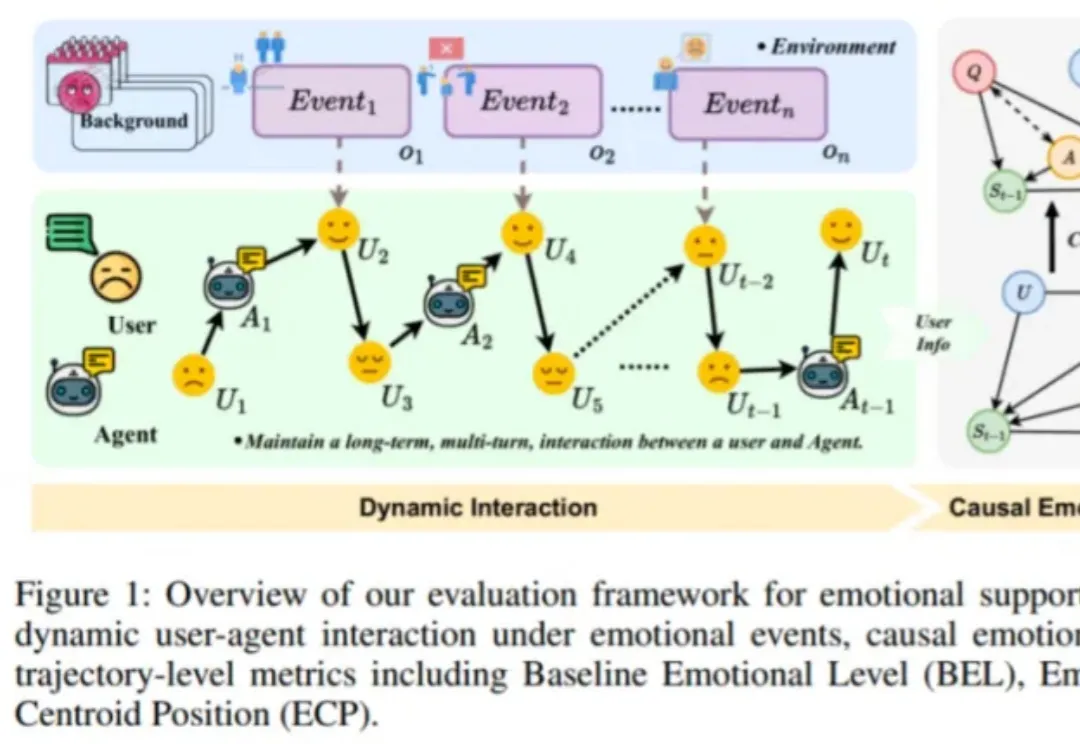
近日,由趣丸科技与北京大学软件工程国家工程研究中心共同发表的《Detecting Emotional Dynamic Trajectories: An Evaluation Framework for Emotional Support in Language Models(检测情感动态轨迹:大语言模型情感支持的评估框架)》论文,获 AAAI 2026 录用。

近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),