
4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理
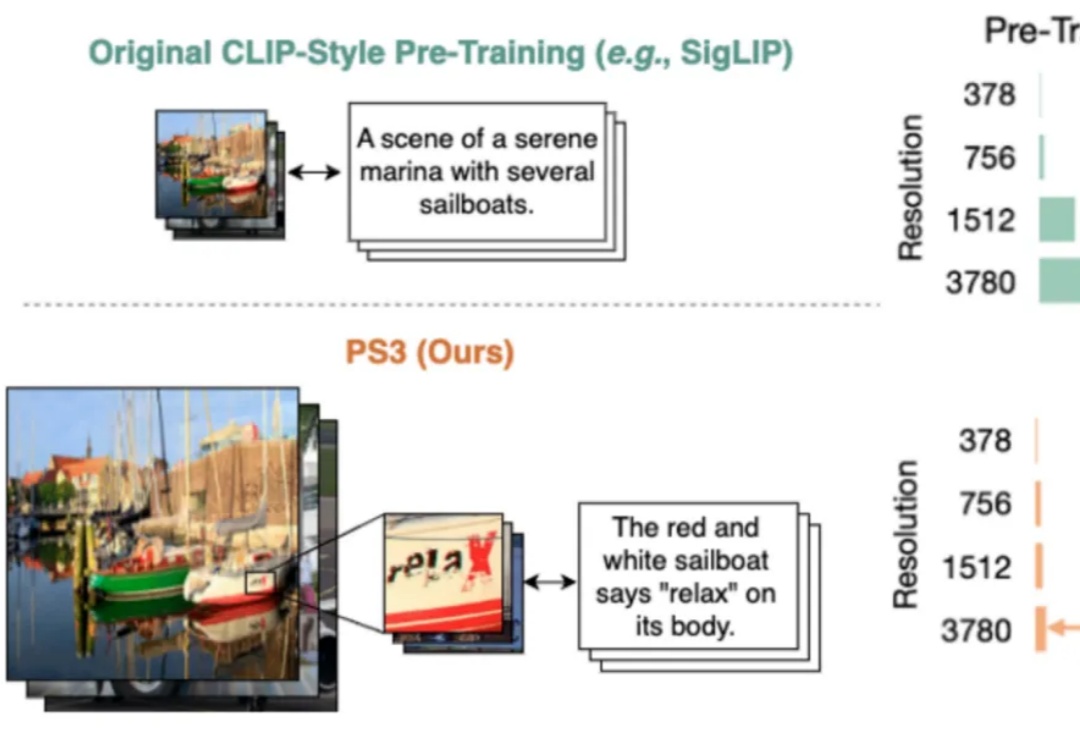
4K分辨率视觉预训练首次实现!伯克利&英伟达多模态新SOTA,更准且3倍加速处理当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。
来自主题: AI技术研报
6730 点击 2025-04-17 13:54
当前,所有主流的视觉基础模型(如 SigLIP、DINOv2 等)都仍然在低分辨率(如 384 * 384 分辨率)下进行预训练。对比人类视觉系统可以轻松达到 10K 等效分辨率,这种低分辨率预训练极大地限制了视觉模型对于高清细节的理解能力。