Claude 3.5首战复现21%顶会论文,人类博士无法取代,OpenAI:AI全是草台班子
Claude 3.5首战复现21%顶会论文,人类博士无法取代,OpenAI:AI全是草台班子自己「打脸」自己?
来自主题: AI技术研报
10735 点击 2025-04-03 16:23
 搜索
搜索
自己「打脸」自己?

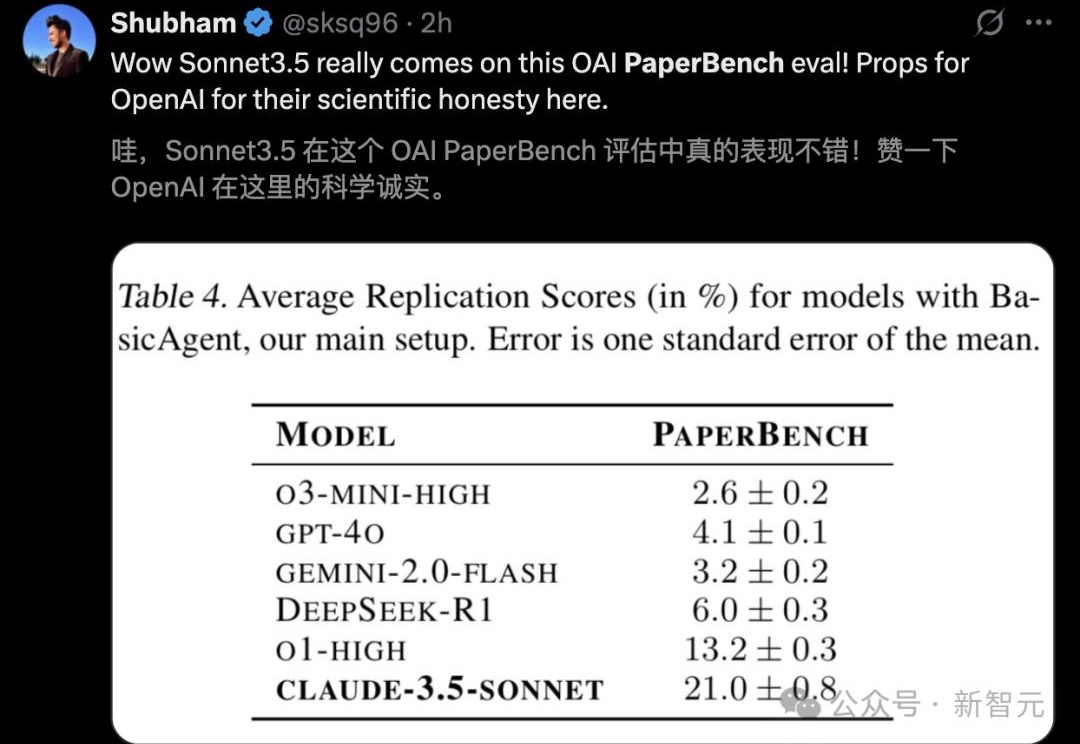
PaperBench 是一个由 OpenAI 开发的基准测试,旨在评估 AI Agent 复现尖端 AI 研究的能 力。它专注于测试 AI 是否能理解研究论文、独立开发代码并执行实验以复现研究结果。

刚刚开源的新基准测试PaperBench,6款前沿大模型驱动智能体PK复现AI顶会论文,新版Claude-3.5-Sonnet显著超越o1/r1排名第一。与去年10月OpenAI考验Agent机器学习代码工程能力MLE-Bnch相比,PaperBench更考验综合能力,不再是只执行单一任务。