
人形机器人的真机强化学习! ICLR 2026 通研院提出人形机器人预训练与真机微调新范式
人形机器人的真机强化学习! ICLR 2026 通研院提出人形机器人预训练与真机微调新范式目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?
来自主题: AI技术研报
10853 点击 2026-02-08 11:56
 搜索
搜索
目前,人形机器人已经能在现实中跳舞、奔跑、甚至完成后空翻。但接下来更关键的问题是:这些系统能否在部署之后持续地进行强化学习 —— 在真实世界的反馈中变得更稳定、更可靠,并在分布不断变化的新环境里持续适应与改进?
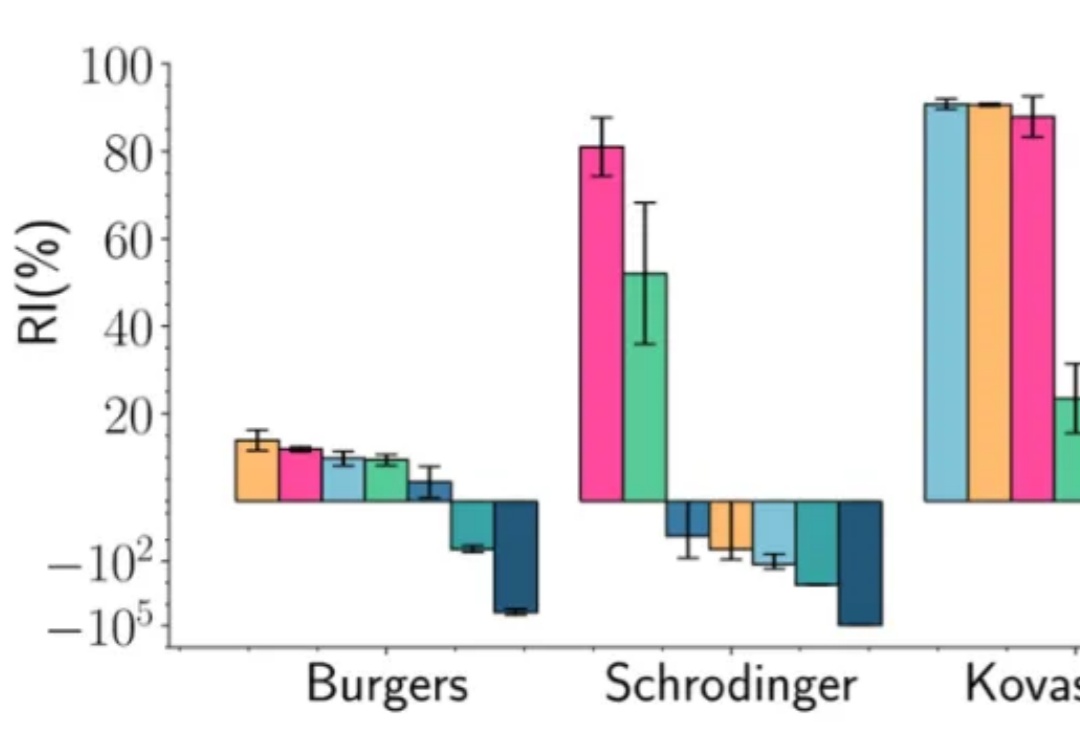
在深度学习的多个应用场景中,联合优化多个损失项是一个普遍的问题。典型的例子包括物理信息神经网络(Physics-Informed Neural Networks, PINNs)、多任务学习(Multi-Task Learning, MTL)和连续学习(Continual Learning, CL)。然而,不同损失项的梯度方向往往相互冲突,导致优化过程陷入局部最优甚至训练失败。