英伟达笑到最后!训练2000步,1.5B逆袭7B巨兽,Scaling真来了
英伟达笑到最后!训练2000步,1.5B逆袭7B巨兽,Scaling真来了强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
来自主题: AI技术研报
8264 点击 2025-06-22 16:32
 搜索
搜索
强化学习可以提升LLM推理吗?英伟达ProRL用超2000步训练配方给出了响亮的答案。仅15亿参数模型,媲美Deepseek-R1-7B,数学、代码等全面泛化。
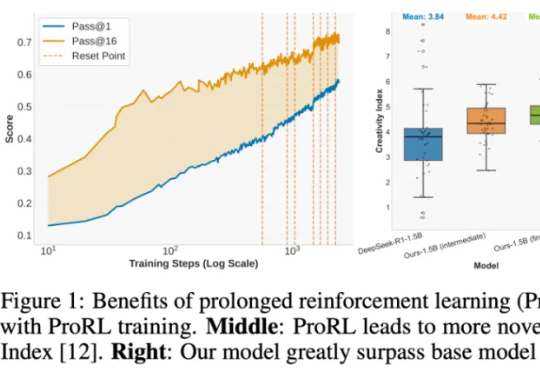
强化学习(RL)到底是语言模型能力进化的「发动机」,还是只是更努力地背题、换个方式答题?这个问题,学界争论已久:RL 真能让模型学会新的推理技能吗,还是只是提高了已有知识的调用效率?