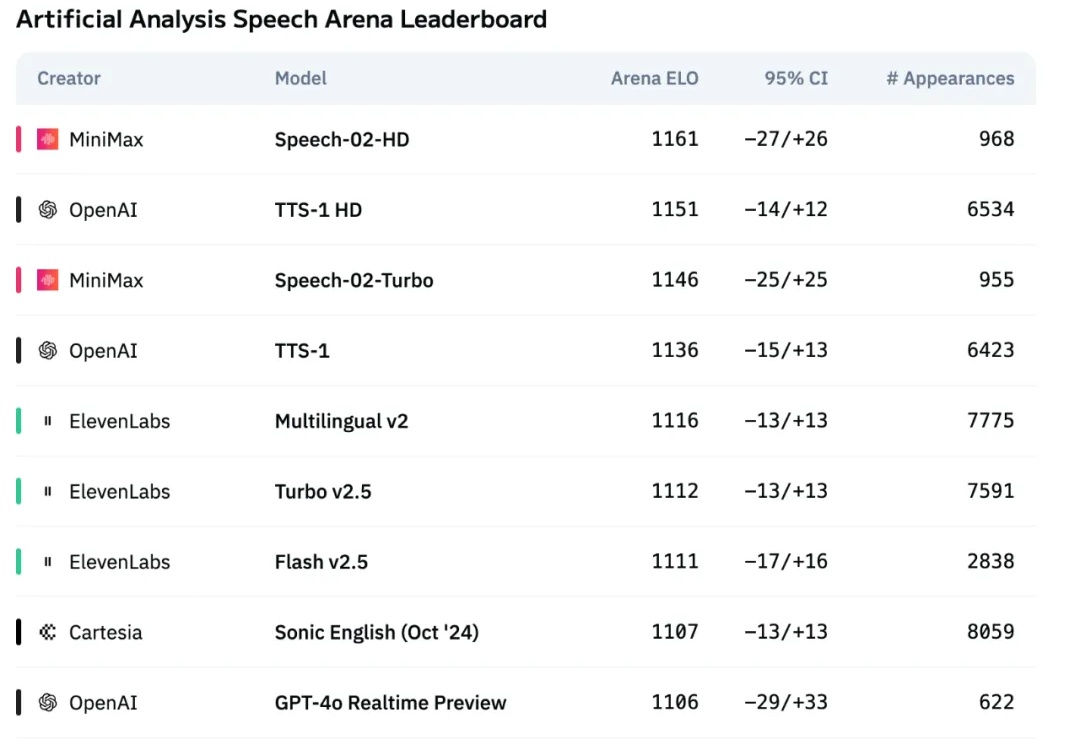
超越OpenAI、ElevenLabs,MiniMax新一代语音模型屠榜!人格化语音时代来了
超越OpenAI、ElevenLabs,MiniMax新一代语音模型屠榜!人格化语音时代来了国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。
来自主题: AI技术研报
11225 点击 2025-05-16 09:59
 搜索
搜索
国产大模型进步的速度早已大大超出了人们的预期。年初 DeepSeek-R1 爆火,以超低的成本实现了部分超越 OpenAI o1 的表现,一定程度上让人不再过度「迷信」国外大模型。

DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。

R1 横空出世,带火了 GRPO 算法,RL 也随之成为 2025 年的热门技术探索方向,近期,字节 Seed 团队就在图像生成方向进行了相关探索。

一夜之间,老黄天塌了(doge)。
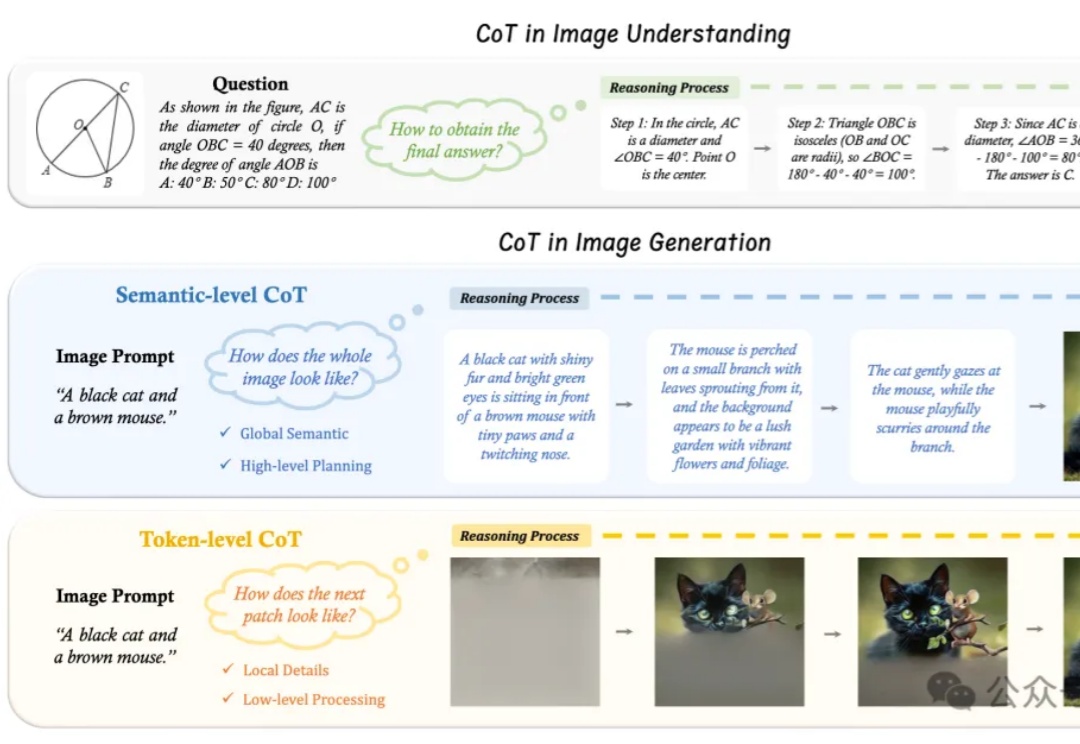
“先推理、再作答”,语言大模型的Thinking模式,现在已经被拓展到了图片领域。
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。

近日,来自SGLang、英伟达等机构的联合团队发了一篇万字技术报告:短短4个月,他们就让DeepSeek-R1在H100上的性能提升了26倍,吞吐量已非常接近DeepSeek官博数据!
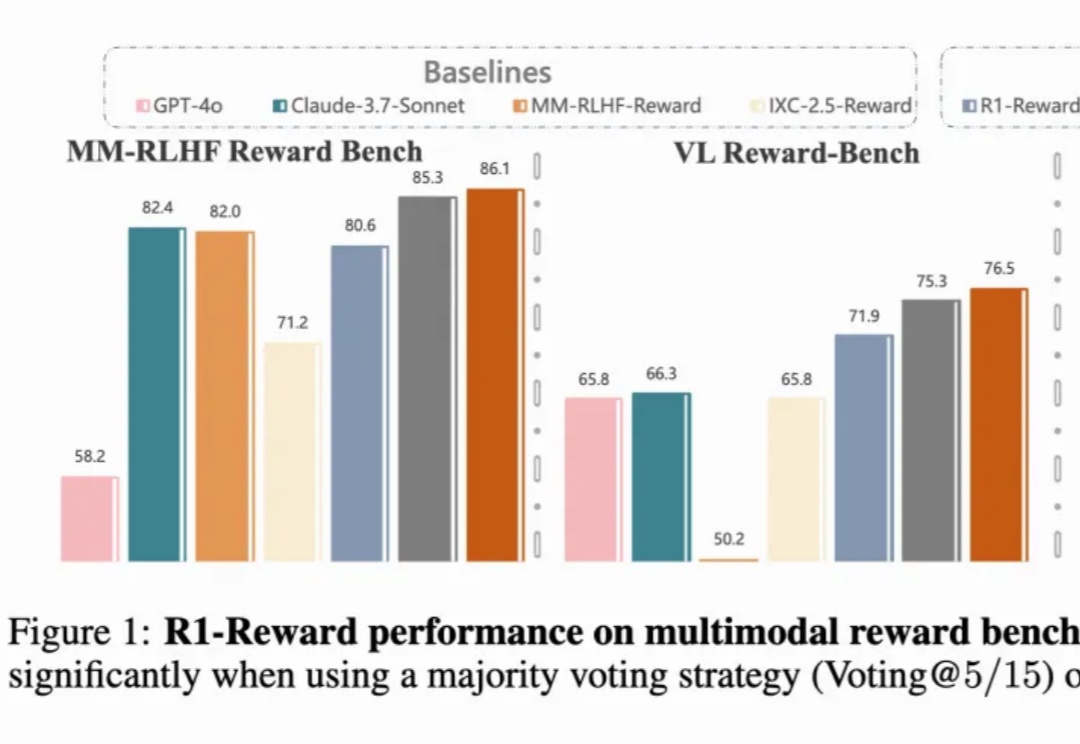
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:

超越DeepSeek-R1的英伟达开源新王Llama-Nemotron,是怎么训练出来的?刚刚放出的论文,把一切细节毫无保留地全部揭秘了!

本文深入梳理了围绕DeepSeek-R1展开的多项复现研究,系统解析了监督微调(SFT)、强化学习(RL)以及奖励机制、数据构建等关键技术细节。