# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用:
……
而强化学习(RL)在理论上能够对MRM引入长期推理能力,使MRM更加高效。
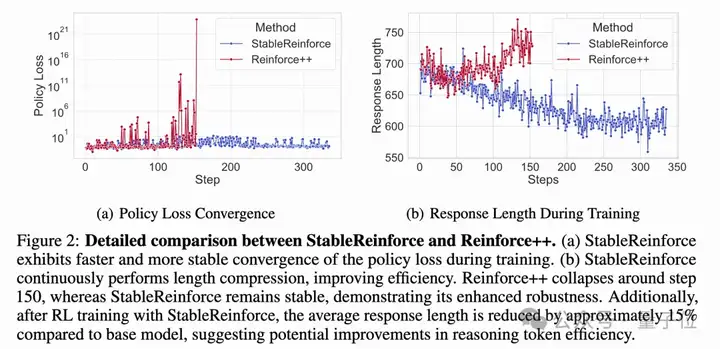
但如果直接把现有的RL算法(比如Reinforce++)用到训练MRM上,就会出现很多状况,比如,训练过程会很不稳定、甚至可能直接崩掉:
现在,来自中科院自动化所、清华大学、快手和南京大学的研究团队,在探索如何利用强化学习来稳定、有效地提升多模态奖励模型的长时推理能力方面,取得了新进展:
基于多模态强化学习的工作MM-RLHF(ICML 2025),进一步推出了R1-Reward模型。
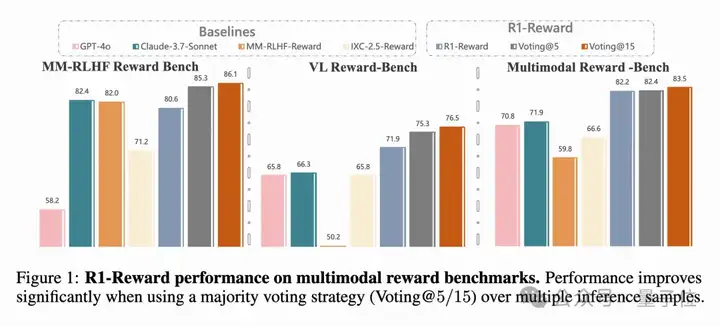
在现有的多模态奖励模型benchmark的基础上,相比于当前最先进的SOTA模型,实现5%-15%的提升。
且随着inference sampleing的数目增多还能进一步增长!

1. 重新定义问题
作者把训练奖励模型这个问题,看成是一个基于规则的强化学习任务。简单说,就是给奖励模型一个问题和两个答案,让它通过学习来判断哪个答案更好,并且能给出合理的分析。
2. 提出新算法StableReinforce
针对现有RL算法的不足,他们提出了一个改进版的算法叫StableReinforce。这个算法主要在几个方面做了优化:
3. 渐进式的训练策略
4. 效果显著
首先得知道,奖励模型(Reward Model)是干嘛的。简单说,它就是用来判断两个模型的回答,哪一个更符合人类喜好。
具体的优化公式大概长这样:
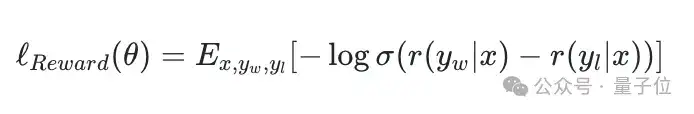
这里的r(y|x)就是模型打的分数,σ是个sigmoid函数,E表示求期望(平均)。意思就是,模型要尽量让好答案的分比坏答案的分高,差距越大越好,然后通过log和sigmoid函数来计算损失。
PPO是一种很常用的强化学习算法,属于策略梯度方法,目标是直接优化模型(策略)来获得最大的累积奖励。它的厉害之处在于——它不像传统的策略梯度方法那样,容易因为步子迈太大而导致训练不稳定。
PPO通过一种特殊的方式来限制每次策略更新的幅度。它的目标函数是这样的:
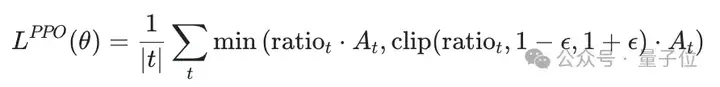
这个公式的核心思想在于那个min和clip操作。它确保了就算ratio*A_t(标准的策略梯度目标)很大,也会被clip后的项限制住,防止策略更新过猛导致训练不稳定。
PPO因为实现简单、效果好,所以在很多地方(比如机器人控制、玩游戏)都用得很广。
Reinforce++是在PPO基础上做了一些优化的版本,目的是让训练更稳定、更高效。主要改进有:

在很多研究中,Reinforce++都比GRPO更稳定、比PPO收敛更快。
虽然PPO和Reinforce++不错,但在实际训练中,尤其是在训练奖励模型的时候,研究者们发现它们有两个核心问题,很容易让模型训练不稳定甚至失败:


总的来说,就是直接把PPO或者Reinforce++用在奖励模型训练上,会因为损失计算和优势归一化这两个环节内在的问题,在高效率训练或者训练后期特定数据分布下,引发数值不稳定,最终影响模型效果。
1. Pre-CLIP策略
为了减小大比例差异的影响,Pre-CLIP策略会在计算对数概率的指数值之前对比例进行裁剪。通过在应用指数函数前裁剪log-πθ/πθold的比例,可以避免由于比例差异过大而导致的溢出问题,并缓解负优势情况下的大对数差异。裁剪后的公式为:
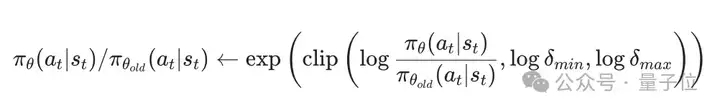

2. Advantage Filter策略
为了避免由于优势分布的极端不平衡对训练带来的影响,文章采用了3-sigma规则(即保留标准化优势在[-3, 3]范围内的样本)。公式为:
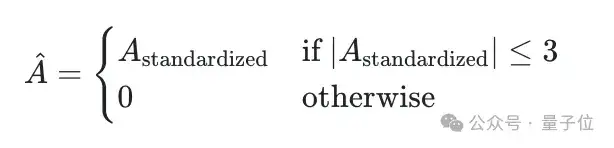

结合了Pre-CLIP和优势过滤器,最终用来优化的目标函数长得有点像常用的PPO算法的目标函数,但有所修改:
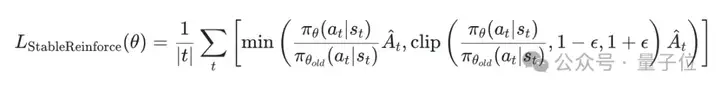
首先使用下面的prompt,将奖励建模问题转化为rule-based的强化学习问题:

近期follow deepseek-r1工作的方法基本上都是格式奖励+结果奖励,但是在奖励模型训练过程中,这存在着一致性问题:即只用上面两个奖励时,模型有时会“精神分裂”:
分析部分(<analysis>)明明说回答2更好,但最后却输出<answer>1</answer>。因此本文引入了一个额外的“裁判”模型(文中用了Qwen2.5-VL-7B-Instruct)。这个裁判专门负责检查奖励模型自己输出的分析内容,看它是不是真的支持最终给出的那个答案。
1.奖励函数设计:文章提出了三种奖励函数
2.最终奖励计算:为了解决可能出现的一致性奖励过度偏重的问题,最终的奖励计算公式为:

这样的设计好在Consistency Reward的加成效果(乘以0.5再加1)只有在Result Reward大于0(也就是答案选对)的时候才能真正起作用。如果答案选错了,Result Reward通常是0或者负数,那么一致性奖励就不会带来正向激励(或者激励很小),从而确保模型首要目标还是把答案选对。格式奖励作为一个基础分被加上去。
多模态大模型(MLLMs)本身并不是为做奖励模型这种“评价比较”任务而设计的,所以直接用强化学习去训练它们,效果通常很差而且不稳定,因此本文先进行了一轮监督微调。
做法:让GPT-4o对R1-Reward-200k数据集里的每一条数据,都按照Table 1里的提示模板,生成标准的“分析过程”和“最终答案”。生成时设置temperature=1(让输出更发散),并且最多尝试3次,直到生成的答案和真实标签一致。
记录难度:同时,他们还记录了GPT-4o需要尝试几次才能生成正确答案,把这个次数作为样本“难度”的指标。
目的:这个SFT阶段就像是给模型“预习”。通过模仿GPT-4o的输出,先让模型学会任务的基本格式和流程,熟悉这个奖励建模任务应该怎么做。
研究人员认为,这些样本通常意味着两个回答之间的差别更小,更难判断优劣。用这些“硬骨头”来训练模型进行强化学习,可以更有效地提升模型辨别细微差异的能力。
研究人员通过一系列实验来验证他们提出的R1-Reward模型和StableReinforce算法的效果,得到了一些挺有意思的结果:
在好几个主流的多模态奖励模型排行榜(比如VLReward Bench, Multimodal Reward Bench, MM-RLHF-Reward Bench)上,R1-Reward的表现都非常亮眼,平均准确率显著超过了之前最好的开源模型(比如IXC-2.5-Reward)。
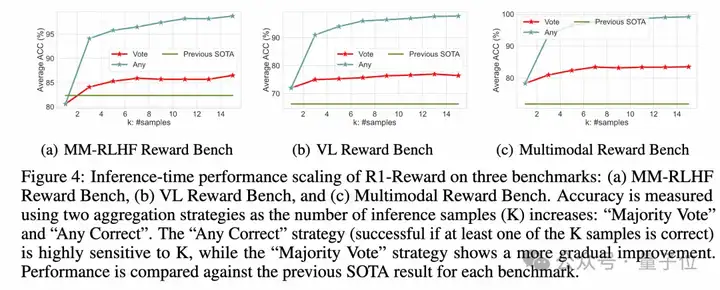
他们尝试在评价的时候,让R1-Reward模型对同一个问题输出好几个判断结果(比如输出5次或15次),然后采取少数服从多数(投票)的方式来决定最终哪个答案更好。
结果发现,这种简单的“投票”策略能大幅提升R1-Reward的准确率。比如在MM-RLHF这个比较难的榜单上,投票5次就能把准确率从大约71%提升到85.3%,投票15次更是达到86.47%,远超其他模型。
更有意思的是,他们还试了另一种策略叫“Any Correct”,就是只要模型输出的K次结果里有一次是正确的,就算对。结果发现,当K=15时,这种策略的准确率几乎接近100%!这暗示R1-Reward其实有潜力完美区分所有样本,只是需要更多的数据或更好的训练策略来完全激发出来。

通过SFT和RL训练,R1-Reward不仅学会了如何评价两个回答,还自主地学习到了一套分析流程:先明确目标、分析图像、尝试解决问题、给出答案,然后基于这个过程去评价两个外部给定的回答。
更有趣的是,模型展示出了类似人类的反思和纠错能力。比如在上图中,模型自己计算时出错了,但在检查图表后,意识到了错误并重新计算得到了正确结果。这说明模型不仅仅是在模仿,还在学习某种程度的自我检查和修正机制。
经过强化学习训练后,模型输出的分析内容的平均长度还减少了约15%,说明模型可能变得更“言简意赅”,推理效率提高了。
本文介绍了R1-Reward,这是一种使用StableReinforce算法训练的多模态奖励模型(MRM)。通过实验,本文证明了强化学习(RL)在奖励建模中的有效应用,显著提升了模型的表现。R1-Reward解决了多个关键问题,包括训练不稳定、优势归一化限制以及推理和结果之间的不一致性。通过引入Pre-Clipping、优势过滤、一致性奖励以及渐进式训练策略,StableReinforce算法有效稳定了训练过程并提升了模型性能。
实验结果表明,R1-Reward在多个多模态奖励模型基准上超越了现有最先进的模型(SOTA),在准确率和数据效率方面取得了显著进展。此外,R1-Reward还展示了优秀的推理时扩展能力,为未来将强化学习融入多模态奖励模型(MRM)的研究奠定了基础。
展望未来,RL在奖励建模中的应用仍有许多值得探索的方向。例如,本文仅测试了简单的多数投票策略用于推理时扩展,未来可能通过更先进的方法进一步提升性能。此外,改进训练策略以进一步增强奖励模型的基础能力,也是一个有意义的开放性问题。
论文链接:
https://arxiv.org/abs/2505.02835
https://github.com/yfzhang114/r1_reward
https://huggingface.co/yifanzhang114/R1-Reward
文章来自于“量子位”,作者“R1-Reward团队”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
