RL训练总崩溃?R1-Reward稳定解锁奖励模型Long-Cot推理能力
RL训练总崩溃?R1-Reward稳定解锁奖励模型Long-Cot推理能力多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。
来自主题: AI技术研报
9576 点击 2025-05-12 14:51
 搜索
搜索
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用,在训练阶段可以提供稳定的 reward,评估阶段可以选择更好的 sample 结果,甚至单独作为 evaluator。
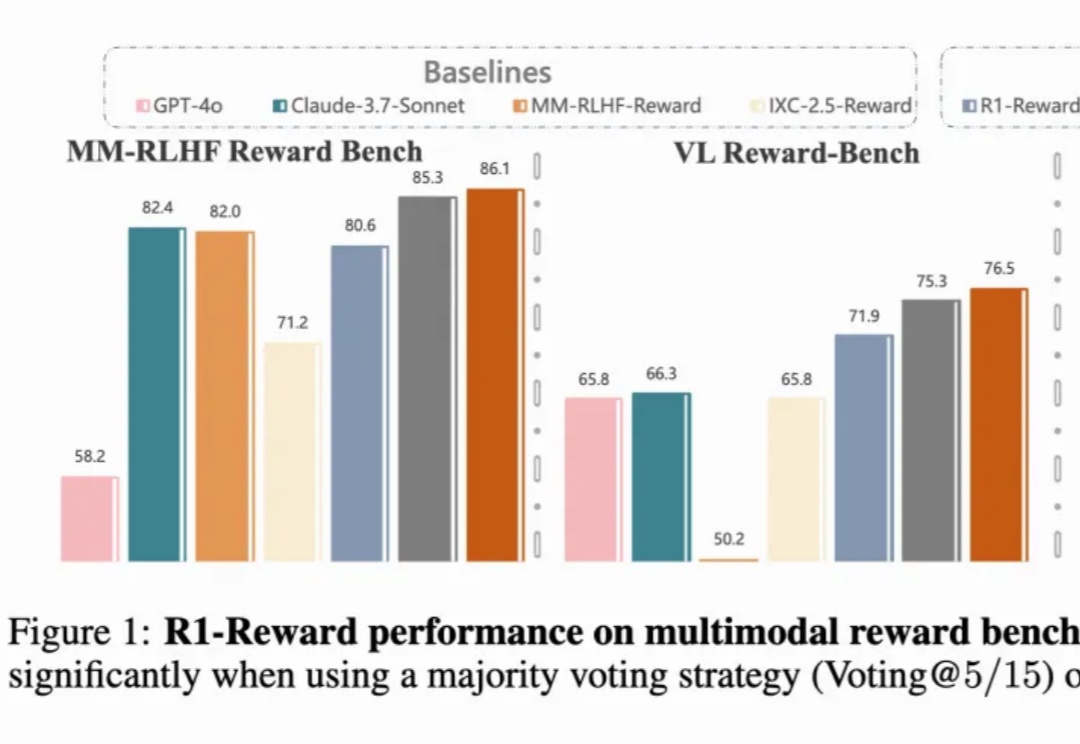
多模态奖励模型(MRMs)在提升多模态大语言模型(MLLMs)的表现中起着至关重要的作用: