
360联合北大震撼发布!5%参数量逼近Deepseek-R1满血性能
360联合北大震撼发布!5%参数量逼近Deepseek-R1满血性能推理黑马出世,仅以5%参数量撼动AI圈。360、北大团队研发的中等量级推理模型Tiny-R1-32B-Preview正式亮相,32B参数,能够匹敌DeepSeek-R1-671B巨兽。
来自主题: AI资讯
7255 点击 2025-02-25 16:33
 搜索
搜索
推理黑马出世,仅以5%参数量撼动AI圈。360、北大团队研发的中等量级推理模型Tiny-R1-32B-Preview正式亮相,32B参数,能够匹敌DeepSeek-R1-671B巨兽。

当地时间 2 月 25 日,Anthropic 正式发布了 Claude 3.7 Sonnet,“这是迄今为止我们最智能的模型,也是市场上首个混合推理模型。”Anthropic 官方表示。
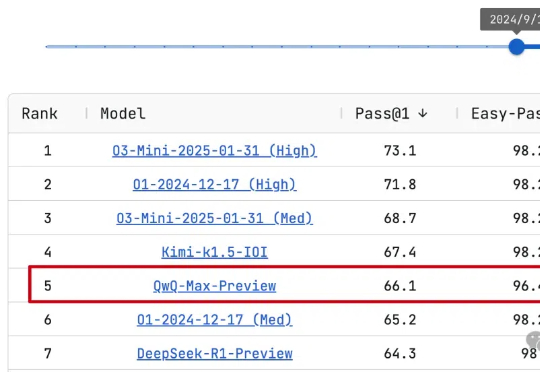
阿里通义Qwen团队熬夜通宵,推理模型Max旗舰版来了!QwQ-Max-Preview预览版,已在LiveCodeBench编程测试中排名第5,小超o1中档推理和DeepSeek-R1-Preview预览版。
知名 Chatbot 及各种 AI 工具箱产品 Monica 最近推出了国内版Monica.cn,基于 DeepSeek R1 与 V3模型,并且具备实时联网搜索与记忆能力。

就在刚刚,Anthropic祭出首个混合推理Claude 3.7 Sonnet,堪称扩展思考模式的最强模型。在最新编码测试中,新模型暴击o3-mini、DeepSeek R1,AI编码王者出世了。
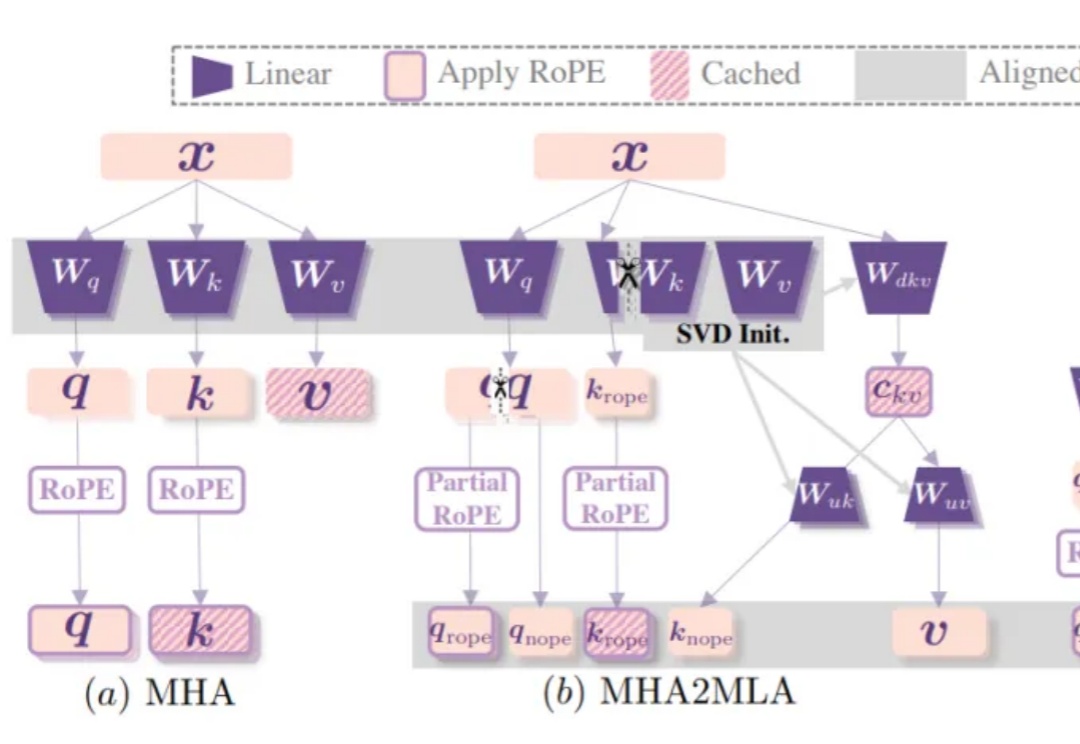
DeepSeek-R1背后关键——多头潜在注意力机制(MLA),现在也能轻松移植到其他模型了!
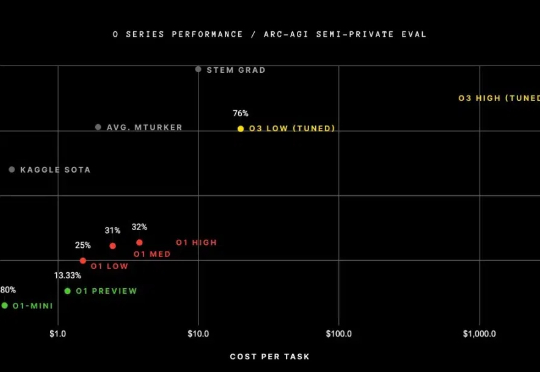
自 OpenAI 发布 o1-mini 模型以来,推理模型就一直是 AI 社区的热门话题,而春节前面世的开放式推理模型 DeepSeek-R1 更是让推理模型的热度达到了前所未有的高峰。

随着AI工具越来越普及,类似Deep Researh这样的工具越来越好用,科学研究成果呈现爆炸式增长。以arXiv为例,仅2024年10月就收到超过24,000篇论文提交。
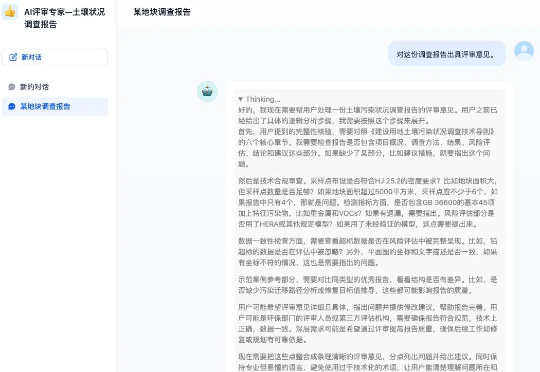
国内首个生态环境“AI报告评审专家”已完成土壤污染状况调查报告领域的前期训练,启动上线试运行。日前,无锡市梁溪生态环境局已完成DeepSeek-R1“满血版”大模型本地化部署,通过AI与生态环境业务深度融合,
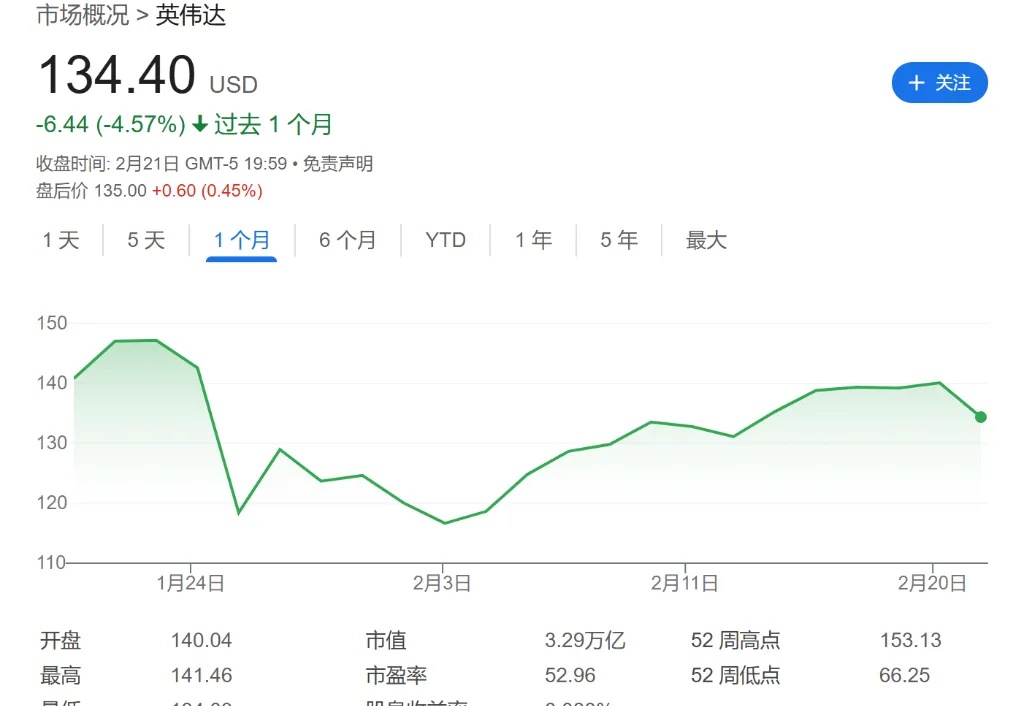
DeepSeek的横空出世引发大模型算力逻辑的质疑,英伟达股价一度暴跌。然而,黄仁勋却在最新访谈中表示,市场对DeepSeek的理解“完全搞反了”。