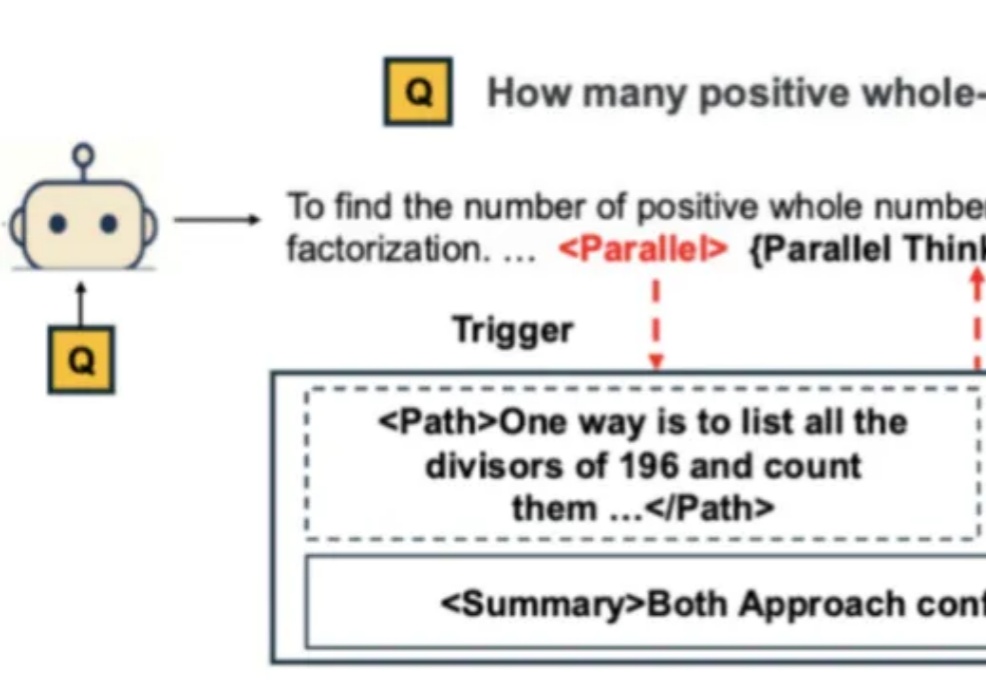
腾讯AI Lab首创RL框架Parallel-R1,教大模型学会「并行思维」
腾讯AI Lab首创RL框架Parallel-R1,教大模型学会「并行思维」自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。
来自主题: AI技术研报
9144 点击 2025-09-18 15:04
 搜索
搜索
自从 Google Gemini 将数学奥赛的成功部分归功于「并行思维」后,如何让大模型掌握这种并行探索多种推理路径的能力,成为了学界关注的焦点。
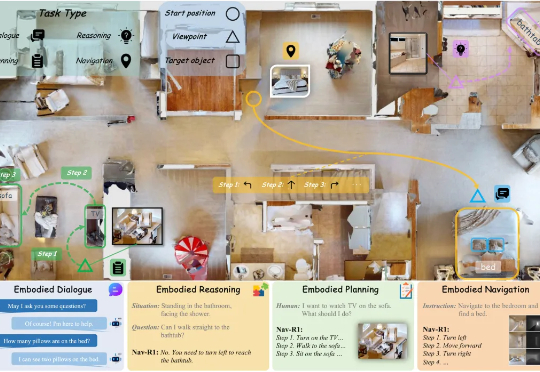
这篇题为《Nav-R1: Reasoning and Navigation in Embodied Scenes》的新论文,提出了一个新的「身体体现式(embodied)基础模型」(foundation model),旨在让机器人或智能体在 3D 环境中能够更好地结合「感知 + 推理 + 行动」。简单说,它不仅「看到 + 听到+开动马达」,还加入清晰的中间「思考」环节。

DeepSeek荣登Nature封面,实至名归!今年1月,梁文锋带队R1新作,开创了AI推理新范式——纯粹RL就能激发LLM无限推理能力。Nature还特发一篇评论文章,对其大加赞赏。
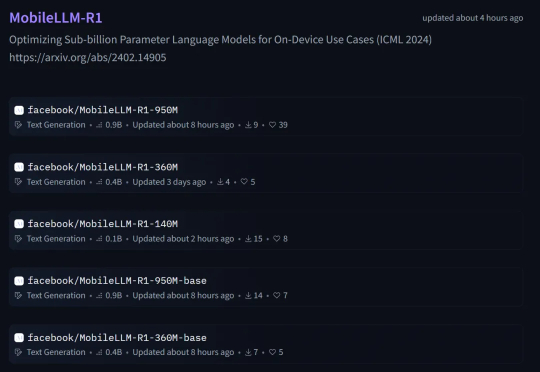
本周五,Meta AI 团队正式发布了 MobileLLM-R1。 这是 MobileLLM 的全新高效推理模型系列,包含两类模型:基础模型 MobileLLM-R1-140M-base、MobileLLM-R1-360M-base、MobileLLM-R1-950M-base 和它们相应的最终模型版。
AI 编程初创公司 Replit 在一轮融资中成功筹集 2.5 亿美元,估值达到 30 亿美元。普信资本(Prysm Capital)正领投本轮融资,美国运通风投(Amex Ventures)和谷歌 AI 未来基金(Google’s AI Futures Fund)等投资机构参与其中。

如果把当下最让人迷惑的科技产品拉个清单,AI 硬件网红们绝对榜上有名。 从 699 美元的 Humane Ai Pin 到 200 美元的 Rabbit R1,这些 AI 创业公司都在兜售同一个美丽的谎言:你需要专门的硬件才能体验真正的 AI。 今天,这个名单上又多了一个新成员——AI Key。

您对“思维链”(Chain-of-Thought)肯定不陌生,从最早的GPT-o1到后来震惊世界的Deepseek-R1,它通过让模型输出详细的思考步骤,确实解决了许多复杂的推理问题。但您肯定也为它那冗长的输出、高昂的API费用和感人的延迟头疼过,这些在产品落地时都是实实在在的阻碍。
随着DeepSeek R1、Kimi K2和DeepSeek V3.1混合专家(MoE)模型的相继发布,它们已成为智能前沿领域大语言模型(LLM)的领先架构。由于其庞大的规模(1万亿参数及以上)和稀疏计算模式(每个token仅激活部分参数而非整个模型),MoE式LLM对推理工作负载提出了重大挑战,显著改变了底层的推理经济学。

不止贴「AI生成」标签
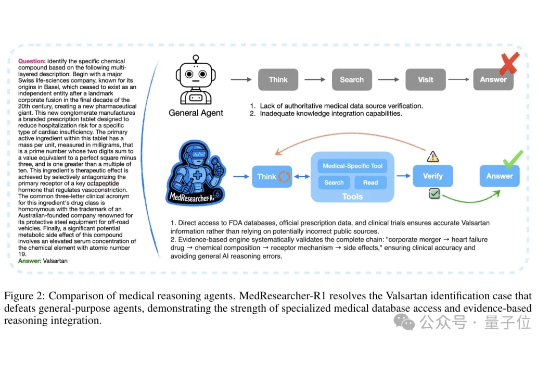
不卷参数的专业模型,会不会被通用大模型取代? 在医疗领域,这个疑问正在被打破。