We-Math 2.0:全新多模态数学推理数据集 × 首个综合数学知识体系
We-Math 2.0:全新多模态数学推理数据集 × 首个综合数学知识体系近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。
来自主题: AI技术研报
10024 点击 2025-08-28 12:20
 搜索
搜索
近期,多模态大模型在图像问答与视觉理解等任务中进展迅速。随着 Vision-R1 、MM-Eureka 等工作将强化学习引入多模态推理,数学推理也得到了一定提升。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。
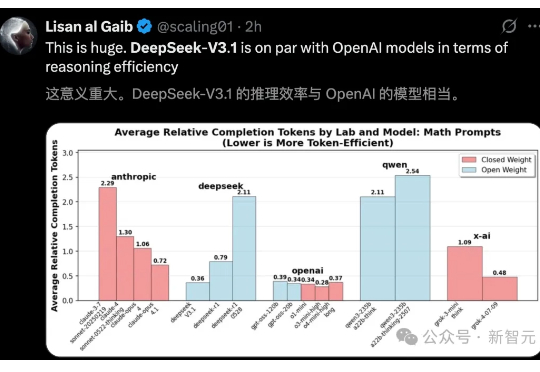
DeepSeek-V3.1官宣了,作为首款「混合推理」模型,将开启智能体新时代。新模型共有671B参数,编码实力碾压DeepSeek-R1、Claude 4 Opus,登顶编程开源第一。
AI能像科幻电影中的先知一样预测未来吗?一个名为「Prophet Arena」的全新基准测试,正通过预测真实世界事件来评估AI的「预言」能力。
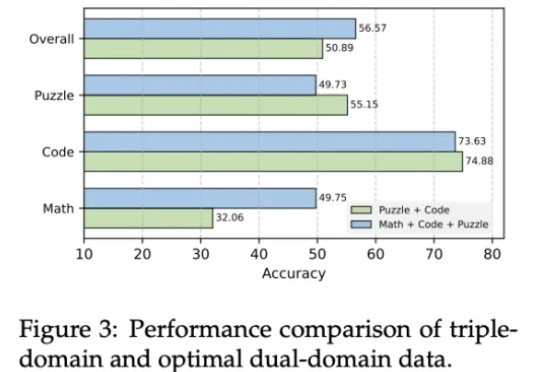
近年来,AI大模型在数学计算、逻辑推理和代码生成领域的推理能力取得了显著突破。特别是DeepSeek-R1等先进模型的出现,可验证强化学习(RLVR)技术展现出强大的性能提升潜力。
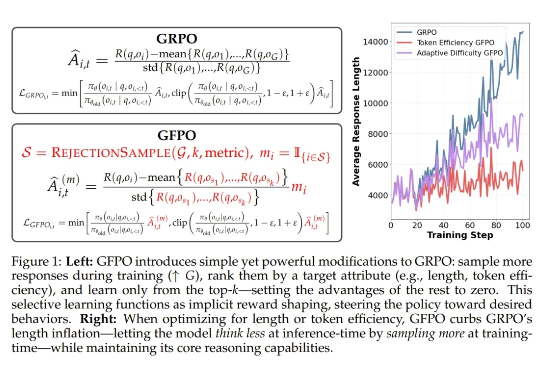
用过 DeepSeek-R1 等推理模型的人,大概都遇到过这种情况:一个稍微棘手的问题,模型像陷入沉思一样长篇大论地推下去,耗时耗算力,结果却未必靠谱。现在,我们或许有了解决方案。

强化学习(RL)是锻造当今顶尖大模型(如 OpenAI o 系列、DeepSeek-R1、Gemini 2.5、Grok 4、GPT-5)推理能力与对齐的核心 “武器”,但它也像一把双刃剑,常常导致模型行为脆弱、风格突变,甚至出现 “欺骗性对齐”、“失控” 等危险倾向。
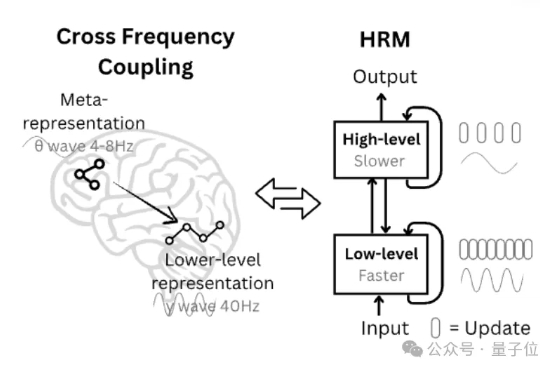
27M小模型超越o3-mini-high和DeepSeek-R1!推理还不靠思维链。 开发者是那位拒绝了马斯克、还要挑战Transformer的00后清华校友,Sapient Intelligence的创始人王冠。
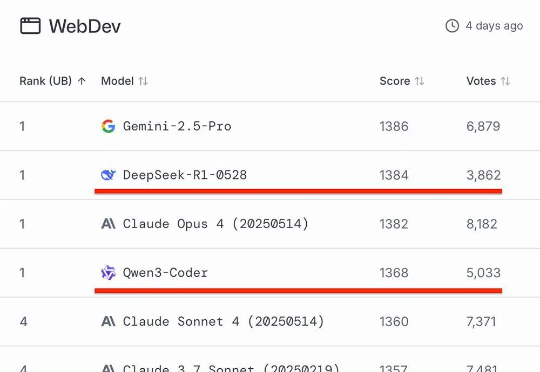
知名AI大模型评测Chatbot Arena放榜!阿里Qwen3-235B-A22B-Instruct-2507位列大语言模型总榜第三,月之暗面Kimi-K2-0711-preview、深度求索DeepSeek-R1-0528并列为总榜第五,以开源之姿超越Claude 4、GPT-4.1等顶尖闭源模型。

在人工智能快速发展的今天,我们已逐渐习惯于让 AI 识别图像、理解语言,甚至与之对话。但当我们进入真实三维世界,如何让 AI 具备「看懂场景」、「理解空间」和「推理复杂任务」的能力?这正是 3D 视觉语言模型(3D VLM)所要解决的问题。