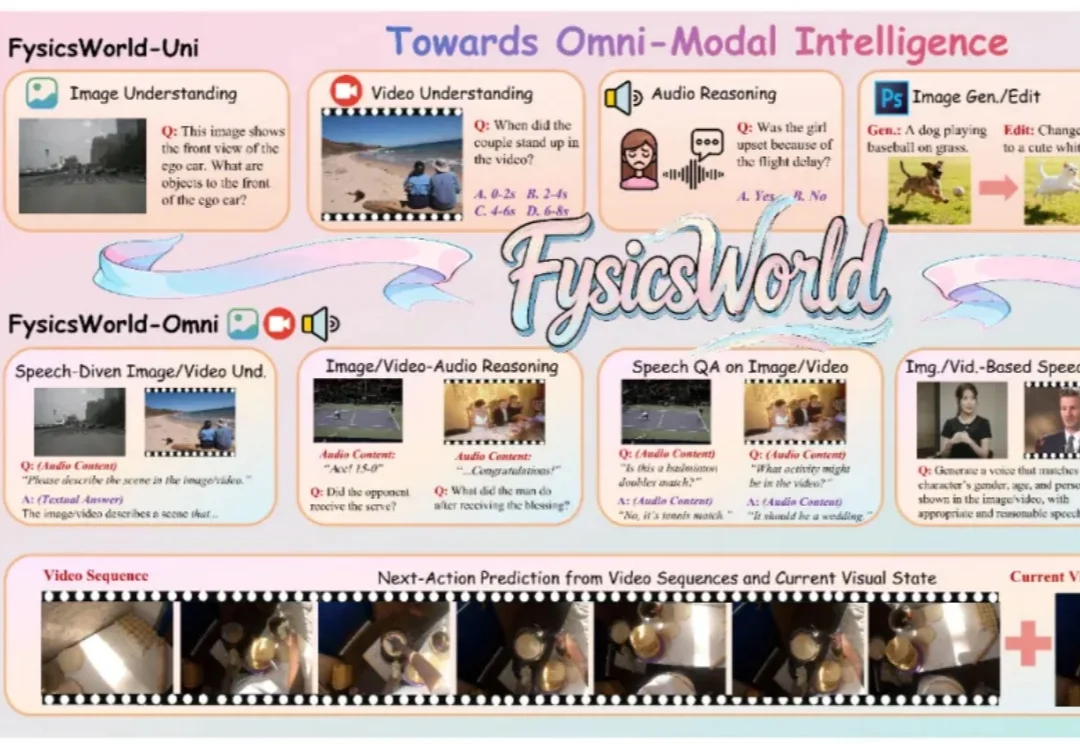
AI 真能看懂物理世界吗?FysicsWorld:填补全模态交互与物理感知评测的空白
AI 真能看懂物理世界吗?FysicsWorld:填补全模态交互与物理感知评测的空白近年来,多模态大语言模型正在经历一场快速的范式转变,新兴研究聚焦于构建能够联合处理和生成跨语言、视觉、音频以及其他潜在感官模态信息的统一全模态大模型。此类模型的目标不仅是感知全模态内容,还要将视觉理解和生成整合到统一架构中,从而实现模态间的协同交互。
来自主题: AI技术研报
9709 点击 2025-12-29 09:05