离谱,特朗普家族下场卖AI API中转站!
离谱,特朗普家族下场卖AI API中转站!太魔幻了,特朗普开始做API中转站了,还有七折的 Claude 可以用。甚至还有机会参加懂王的私人派对。前两天还在跟朋友感慨,连孙雨晨都低调下场搞中转站了,AI API 这门生意是真的下沉到水深火热了。
来自主题: AI资讯
9219 点击 2026-05-07 10:57
 搜索
搜索
太魔幻了,特朗普开始做API中转站了,还有七折的 Claude 可以用。甚至还有机会参加懂王的私人派对。前两天还在跟朋友感慨,连孙雨晨都低调下场搞中转站了,AI API 这门生意是真的下沉到水深火热了。
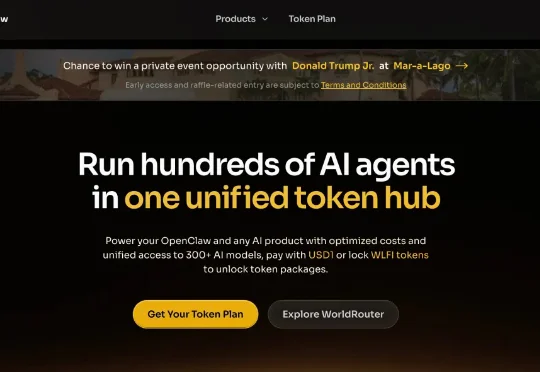
懂王开始做 API 中转站了,还七折的 Claude 的 API。买多了,还抽送懂王的私人晚宴名额!项目叫 WorldClaw,可以理解为 OpenRouter 的懂王版,在这里,需要用懂王的加密货币 WLFI 结算,聚合了 300 多个 AI 模型,声称比官方定价低 30%

用强化学习(RL)优化文生图模型的 prompt following 能力,是一条被广泛验证的路径 —— 让模型根据 prompt 用不同随机种子生成多张图片,通过 reward model 计算 reward,再利用相关 RL 算法优化模型。
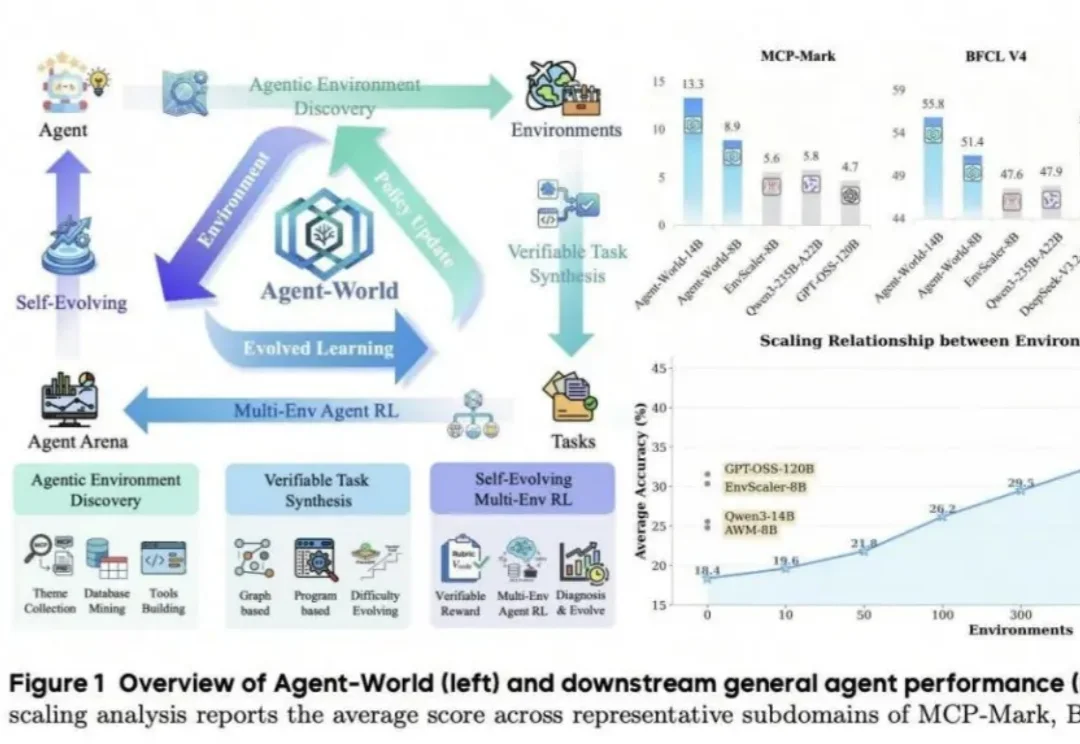
随着MCP、Agent Skills与各类Harness的快速发展,大模型能轻松调用成百上千种外部工具,但在多工具,具备复杂状态、长程交互的任务上仍有明显短板。尽管一系列环境扩展方法尝试复刻真实世界的交互环境(如订票系统,外卖平台),但仍受限于环境扩展的规模与真实性。
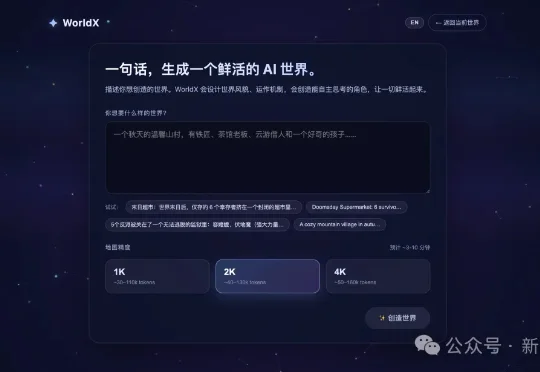
2023年斯坦福「AI小镇」火了,后续也诞生了大量类似的热门项目,但所有这类项目都有一个共同瓶颈——世界是人工搭建的,固定的。最近,一位独立开发者用10天婚假爆肝了一个项目WorldX:输入一句话、5分钟,一个完整的AI世界就诞生了——地图、角色、动画、人设全部自动生成,AI角色们自主在其中生活、对话、形成记忆、产生戏剧性的涌现行为。
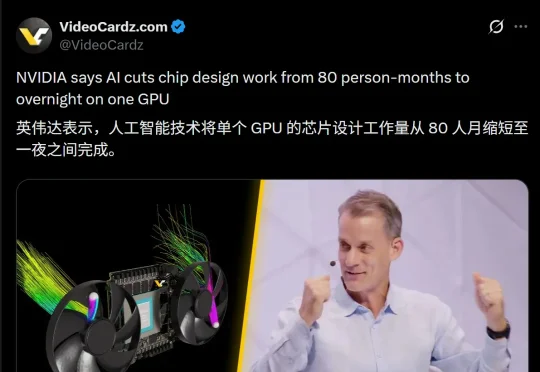
8人团队干10个月,AI只需一夜!英伟达祭出「造芯」神技:芯片设计效率狂飙百倍,非人类直觉的设计方案惊呆工程师。硅基生命开始自进化,人类正退居二线?进来看黄仁勋的秘密武器。
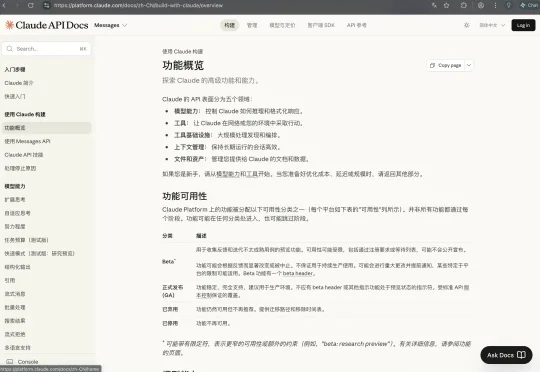
我发现:Claude 一边把中国大陆挡在门外,一边在认认真真做简体中文。事情是这样—— 前两天我把 Claude 文档 URL 里的 /en/ 改成了 /zh-CN/。页面唰地就变了。整站简体中文,翻译贼讲究。
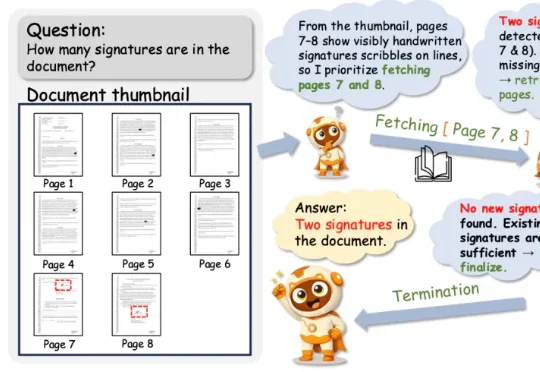
Doc-V* 由小米大模型 Plus 团队和华中科技大学 VLRLab 团队合作提出,一种从「静态阅读」到「主动探索」的多页文档理解新范式,通过交互式视觉推理让模型像人一样有策略地阅读长文档。

世界模型黑马横空出世!就在刚刚,生数科技的MotuBrain零宣发登顶双榜,直接打通「看懂世界+执行行动」,而且不同的是,他们把World Action Model适配多个头部机器人本体,完成多个长程任务,这是国产AI的硬核突围!从此,具身智能彻底迈入新纪元。

红警不再只是童年游戏,而成了AI Agent的硬核训练场:OpenRA-RL把25Hz实时战场、50个工具调用和64局并发打包开源,让大模型第一次真正站上RTS战争迷雾里的公开考场。