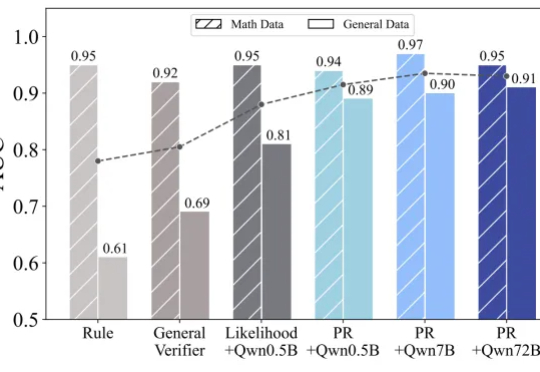
突破通用领域推理的瓶颈!清华NLP实验室强化学习新研究RLPR
突破通用领域推理的瓶颈!清华NLP实验室强化学习新研究RLPRDeepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward
来自主题: AI技术研报
10714 点击 2025-06-27 10:03
 搜索
搜索
Deepseek 的 R1、OpenAI 的 o1/o3 等推理模型的出色表现充分展现了 RLVR(Reinforcement Learning with Verifiable Reward