
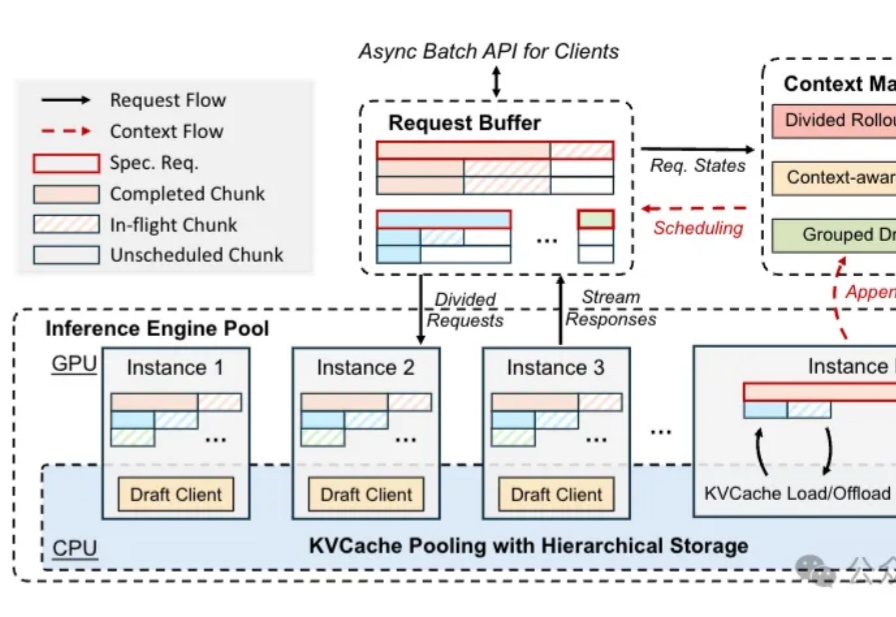
月之暗面公开强化学习训练加速方法:训练速度暴涨97%,长尾延迟狂降93%
月之暗面公开强化学习训练加速方法:训练速度暴涨97%,长尾延迟狂降93%u1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢……
来自主题: AI技术研报
8679 点击 2025-11-27 15:29
u1s1,现在模型能力是Plus了,但Rollout阶段的速度却越来越慢……

智能体终于拥有了可以海量复制的“实战演练场”。阿里此次开源的新项目ROCK,解决了无法在真实环境中规模化训练的难题。有了ROCK,开发者想要训练AI执行复杂任务时可以不再“手搓”环境,直接进行标准化的一键部署。

近期,阿里巴巴 ROLL 团队(淘天未来生活实验室与阿里巴巴智能引擎团队)联合上海交通大学、香港科技大学推出「3A」协同优化框架 ——Async 架构(Asynchronous Training)、Asymmetric PPO(AsyPPO)与 Attention 机制(Attention-based Reasoning Rhythm),
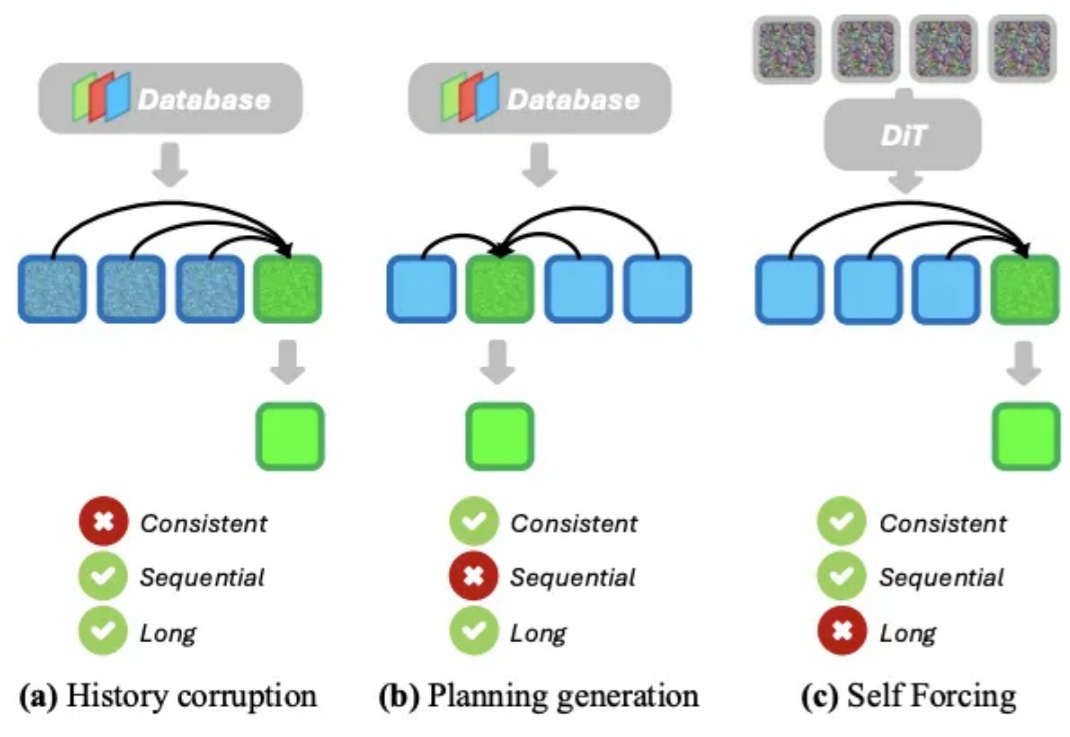
想象一下,你正在玩一款开放世界游戏,角色在无缝衔接的世界中自由漫游,游戏引擎必须实时生成一条无限长的视频流来呈现这个虚拟世界。或者,你戴着 AR 眼镜在街头行走,系统需要根据你的视线与动作,即时生成与你环境交互的画面。无论是哪种场景,都对 AI 提出了同样的要求:能实时生成高质量、长时间连贯的视频流。

AEPO 系统性揭示了「高熵 Rollout 采样坍缩」和「高熵梯度裁剪」问题,并设计了「动态熵平衡 Rollout 采样」与「熵平衡策略优化」两项核心机制。前者通过熵预监控与连续分支惩罚实现全局与局部探索预算的自适应分配,后者在策略更新阶段引入梯度停止与熵感知优势估计以保留高熵 token 的探索梯度。
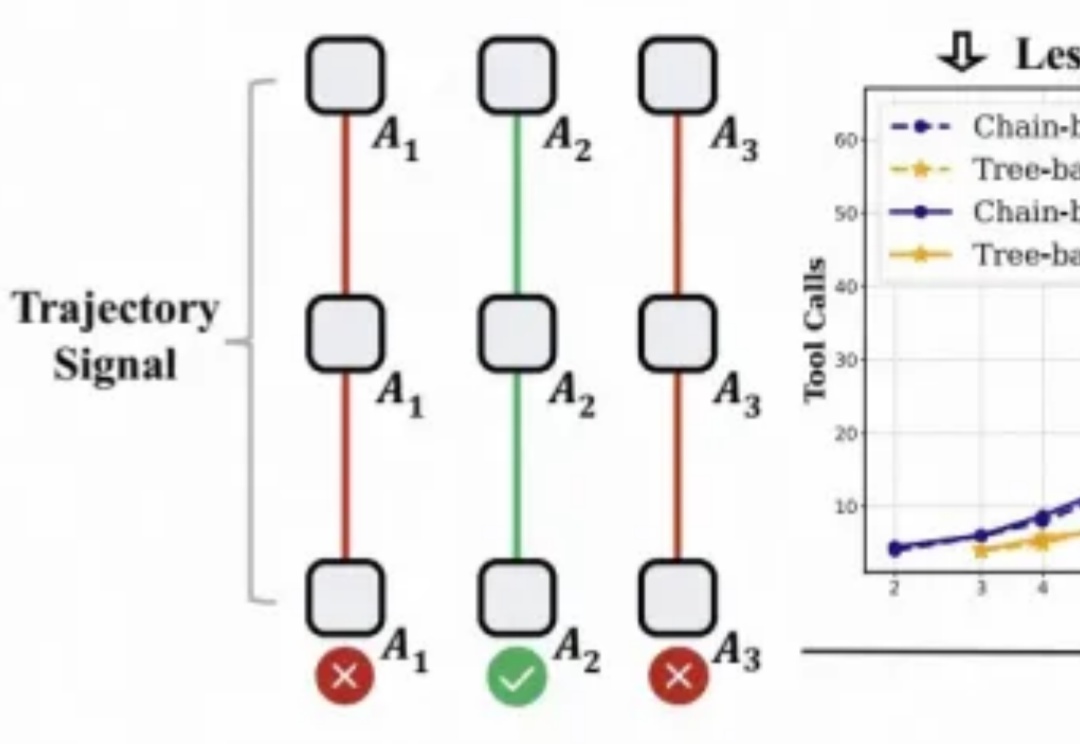
对于大模型的强化学习已在数学推理、代码生成等静态任务中展现出不俗实力,而在需要与开放世界交互的智能体任务中,仍面临「两朵乌云」:高昂的 Rollout 预算(成千上万的 Token 与高成本的工具调用)和极其稀疏的「只看结果」的奖励信号。

最近,硅谷兴起了一股新玩法,叫 AI Rollup。 简单来说,就是投资机构帮助AI应用公司收购一批传统小公司,然后把 AI 技术塞进去,让它们更高效、更赚钱,然后批量做大。 一个典型案例就是AI客服公司Crescendo。
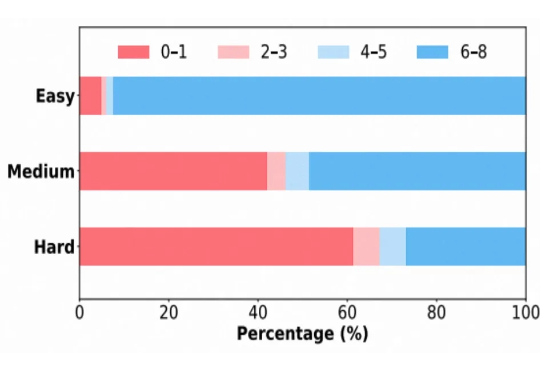
近年来,强化学习(Reinforcement Learning, RL)在提升大语言模型(LLM)复杂推理能力方面展现出显著效果,广泛应用于数学解题、代码生成等任务。通过 RL 微调的模型常在推理性能上超越仅依赖监督微调或预训练的模型。
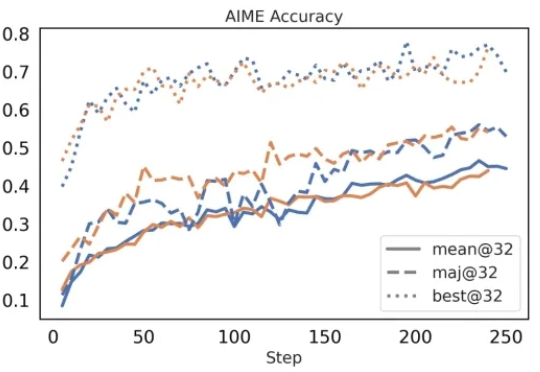
在今年三月份,清华 AIR 和字节联合 SIA Lab 发布了 DAPO,即 Decoupled Clip and Dynamic sAmpling Policy Optimization(解耦剪辑和动态采样策略优化)。
过去几年,随着基于人类偏好的强化学习(Reinforcement Learning from Human Feedback,RLHF)的兴起,强化学习(Reinforcement Learning,RL)已成为大语言模型(Large Language Model,LLM)后训练阶段的关键技术。