能上生产才是硬道理!Coding Agent 评测,终于开始关注过程了
能上生产才是硬道理!Coding Agent 评测,终于开始关注过程了今天是一期硬核的话题讨论: Coding Agent 评测。 AI 编程能力进步飞速,在国外御三家和国产中厂四杰的努力下,AI 编程基准 SWE-bench 的分数从年初的 30% 硬生生拉到了年底的
来自主题: AI技术研报
9404 点击 2026-01-18 14:56
 搜索
搜索
今天是一期硬核的话题讨论: Coding Agent 评测。 AI 编程能力进步飞速,在国外御三家和国产中厂四杰的努力下,AI 编程基准 SWE-bench 的分数从年初的 30% 硬生生拉到了年底的
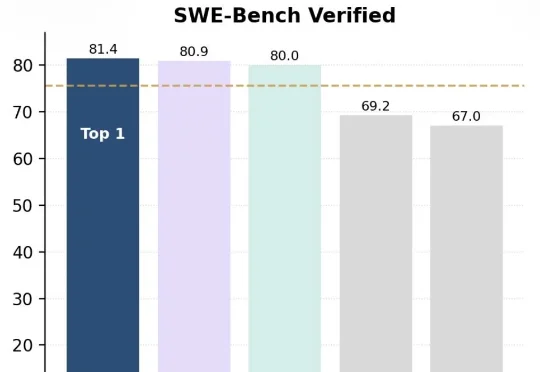
又一个中国新模型被推到聚光灯下,刷屏国内外科技圈。IQuest-Coder-V1模型系列,看起来真的很牛。在最新版SWE-Bench Verified榜单中,40B参数版本的IQuest-Coder取得了81.4%的成绩,这个成绩甚至超过了Claude Opus-4.5和GPT-5.2(这俩模型没有官方资料,但外界普遍猜测参数规模在千亿-万亿级)。

MiniMax最新旗舰级Coding & Agent模型M2.1,刚刚对外发布了。这一次,它直接甩出了一份硬核成绩单,在衡量多语言软件工程能力的Multi-SWE-bench榜单中,以仅10B的激活参数拿下了49.4%的成绩,超越了Claude Sonnet 4.5等国际顶尖竞品,拿下全球SOTA。
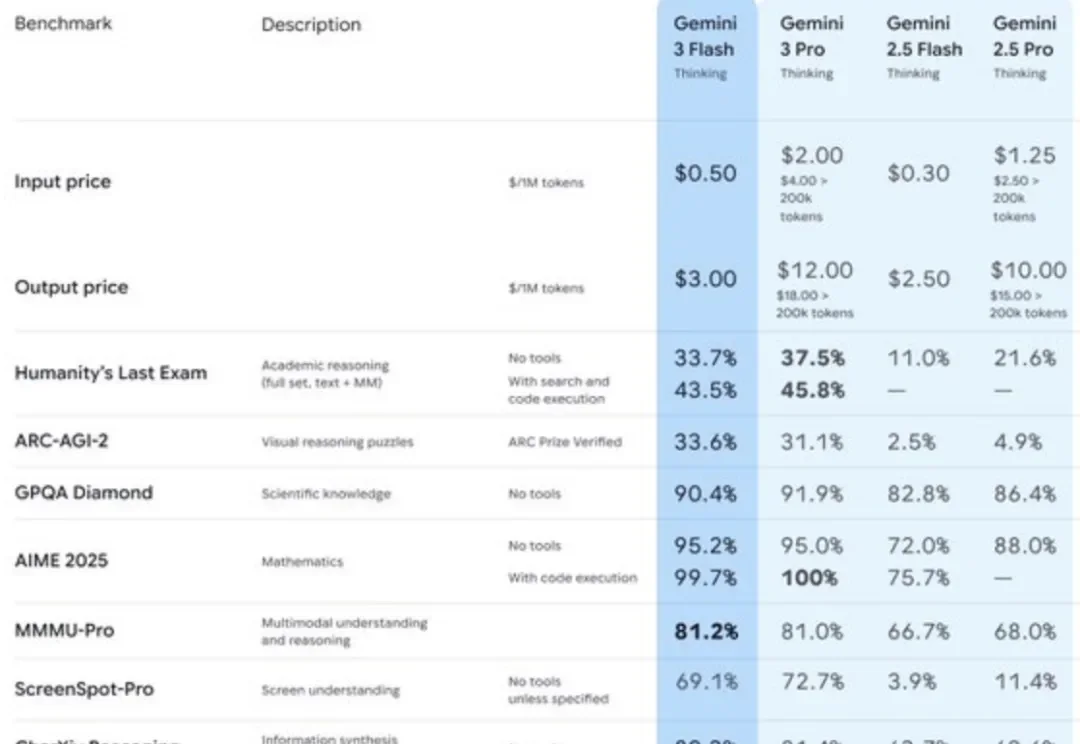
倒反天罡! Gemini 3 Flash的表现在SWE-Bench Verified测试中获得了78%的分数,比超大杯Pro还略胜一筹。

来自中国的初创团队词元无限给出了自己的答案。由清华姚班校友带队设计开发的编码智能体 InfCode,在 SWE-Bench Verified 和 Multi-SWE-bench-CPP 两项非常权威的 AI Coding 基准中双双登顶,力压一众编程智能体。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。

学界杀入主赛道!UCL 校园团队 EuniAI 抛出开源智能体 Prometheus,在 SWE-bench Verified 上 71.2% Pass@1、主榜实锤合并;成本低至 $0.23/issue。
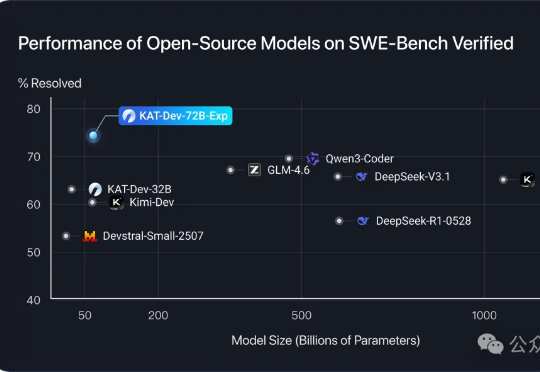
开源编程模型王座,再度易主!来自快手的KAT-Dev-72B-Exp,在SWE-Bench认证榜单以74.6%的成绩夺得开源模型第一。KAT-Dev-72B-Exp是KAT-Coder模型的实验性强化学习版本。
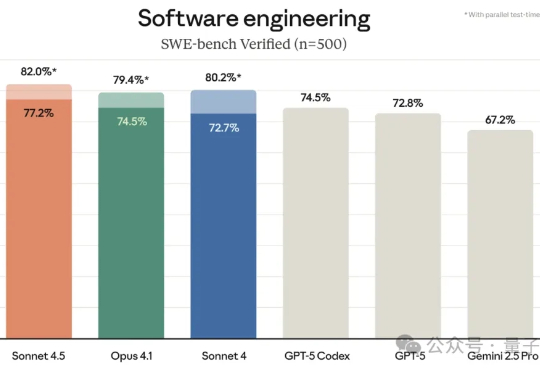
最强编程模型让位了。 但没有换人,依然是Claude。 新发布的Claude Sonnet 4.5,在SWE-bench上的成绩比Sonnet 4提升了1.8个百分点,而且提质不加价。
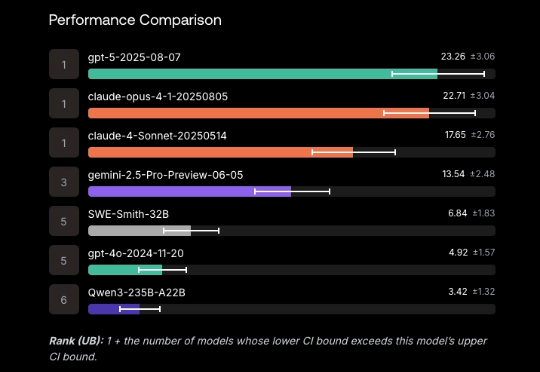
Scale AI的新软件工程基准SWE-BENCH PRO,出现反转!表面上看,“御三家”集体翻车,没一家的解决率超过25%: GPT-5、Claude Opus 4.1、Gemini 2.5分别以23.3%、22.7%、13.5%的解决率“荣”登前三。