Scaling Law撞墙?预训练终结?亚马逊云科技为什么还在做基础大模型
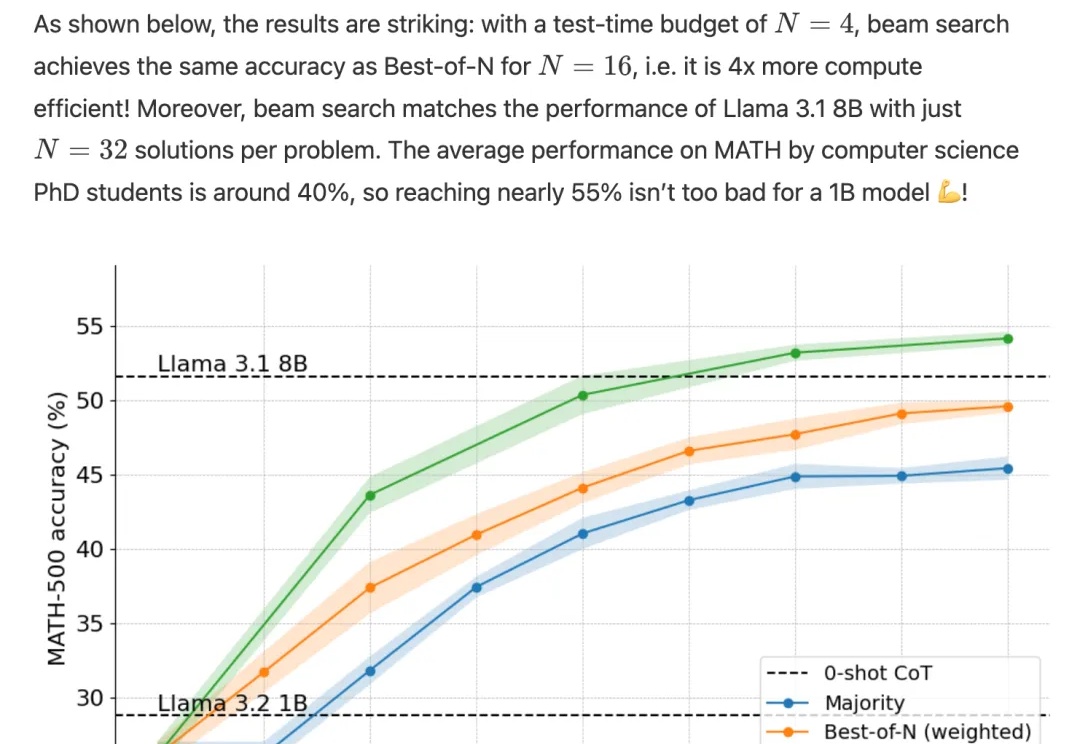
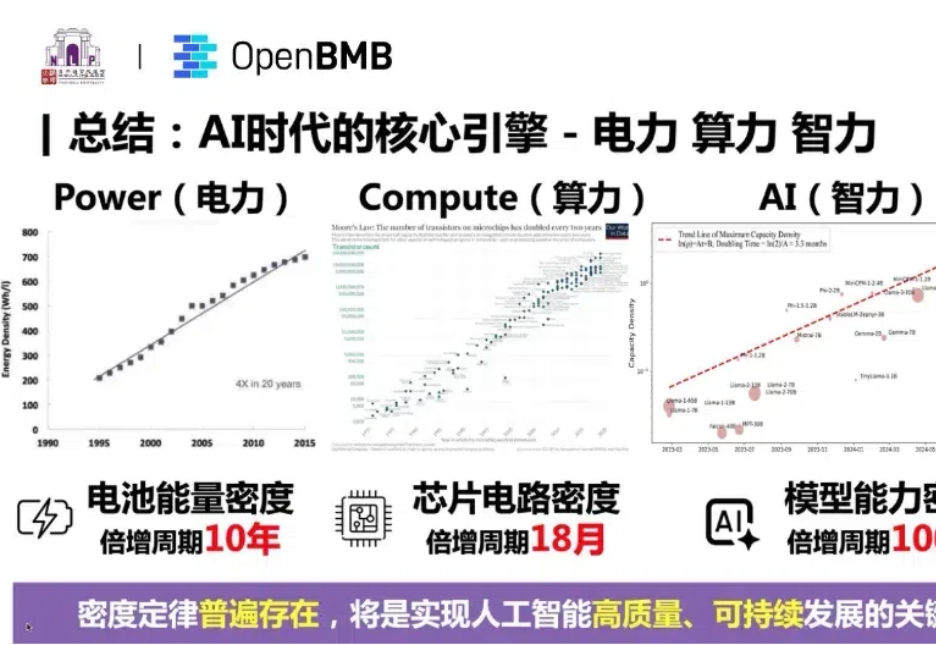
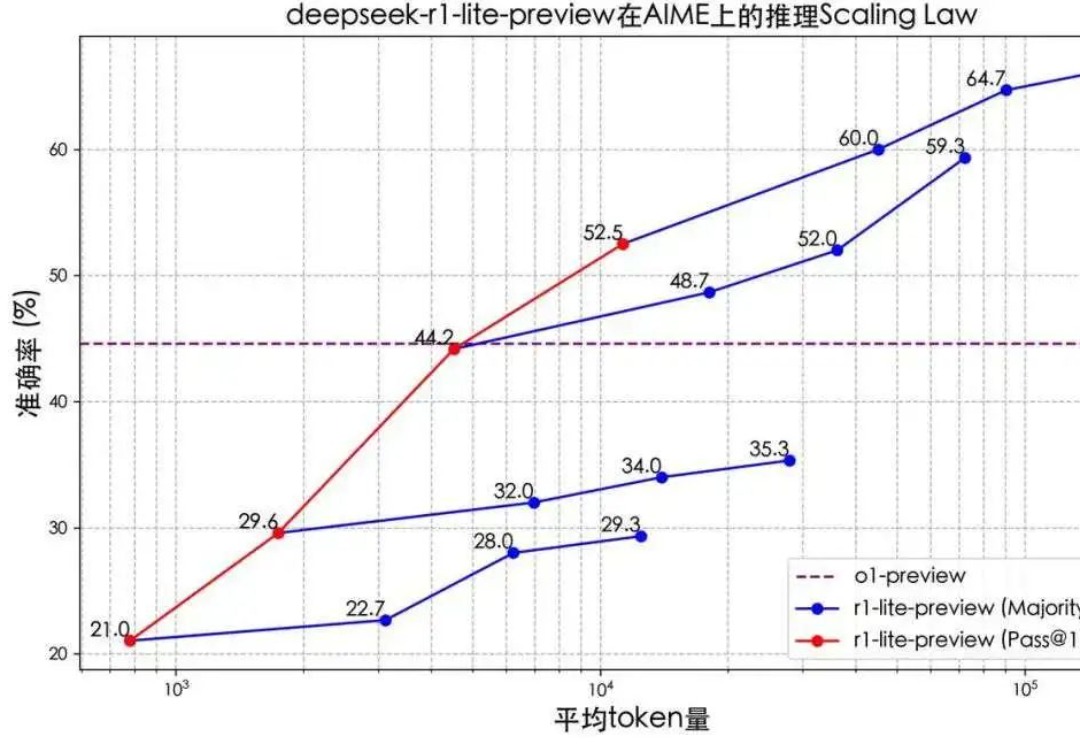
Scaling Law撞墙?预训练终结?亚马逊云科技为什么还在做基础大模型12 月 2-6 日,亚马逊云科技在美国拉斯维加斯举办了今年度的 re:Invent 大会。会上,亚马逊云科技发布了相当多东西,其中之一便是新的大模型系列 Nova。说实话,这确实出乎了相当多人的意料 —— 毕竟亚马逊已经重金押注 Anthropic,似乎没有必要再自起炉灶了。
来自主题: AI资讯
8920 点击 2024-12-18 14:41