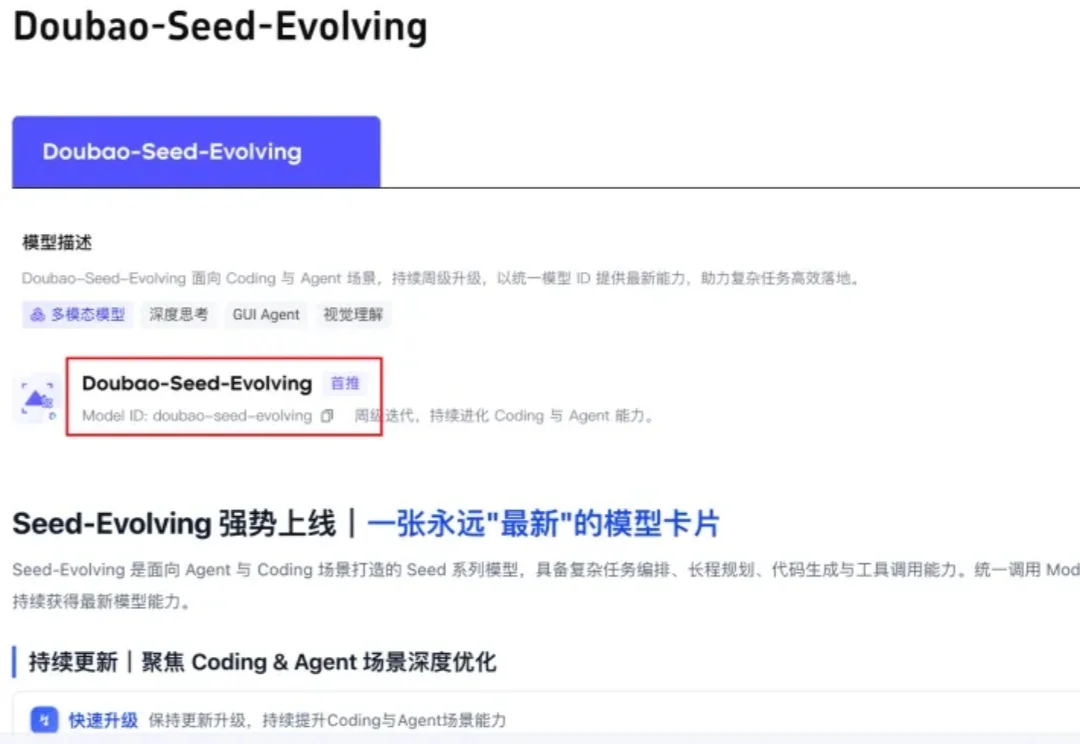
告别版本号!豆包首款无限进步模型:Seed-Evolving实测
告别版本号!豆包首款无限进步模型:Seed-Evolving实测大家好,我是袋鼠帝。 前几天,火山的朋友提前跟我同步了一个消息,说豆包Seed模型又更新了。
来自主题: AI产品测评
8307 点击 2026-07-17 11:05
 搜索
搜索
大家好,我是袋鼠帝。 前几天,火山的朋友提前跟我同步了一个消息,说豆包Seed模型又更新了。

AI 生图最难的地方,早就从「生成一张好看的图」变成了「把那张差一点的图改对」。
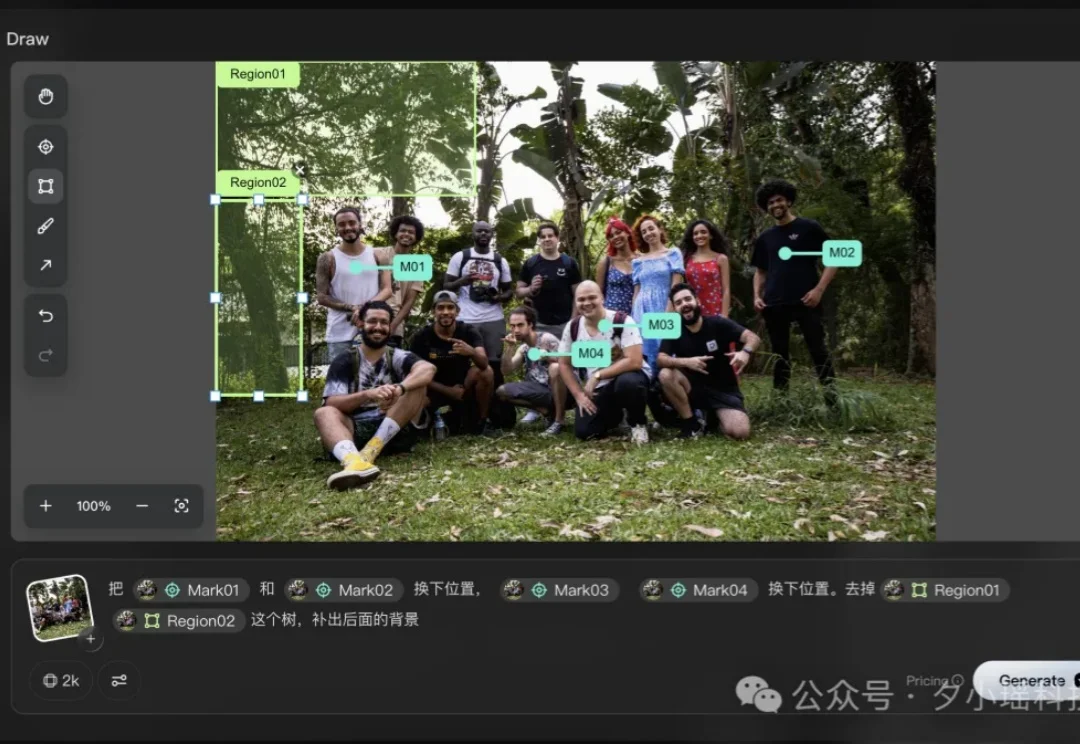
用 AI 生图的人,应该都体会过这种痛苦。

上周,我们又打了一通电话。酱油开口的第一句话是:「这个行业已经没有了!」 当时他们还在讨论要招 3000 人、4000 人;现在,只剩下 300 人左右。在 Seedance 2.0 出现后,行业没有因此更繁荣,反而被更快地推向过剩。

由阿里巴巴集团孵化的空间智能企业“元境”,正在内测“JellyToken”,平台定位AI大模型一站式超市,支持一套密钥调用多款模型。该平台整合了Qwen3.7、Seedance2.0等多款国产大模型,面向个人创作者、中小团队、企业推出付费统一调用服务。

7月8日晚间,字节跳动Seed团队正式发布多模态图像创作模型Seedream 5.0 Pro。这距离今年2月10日Seedream 5.0预览版上线,已经过去近5个月。相比此前版本,Seedream 5.0 Pro在图文匹配、结构合理性、文字渲染与画面美感等基础能力上进行了升级,并重点强化了四项核心能力
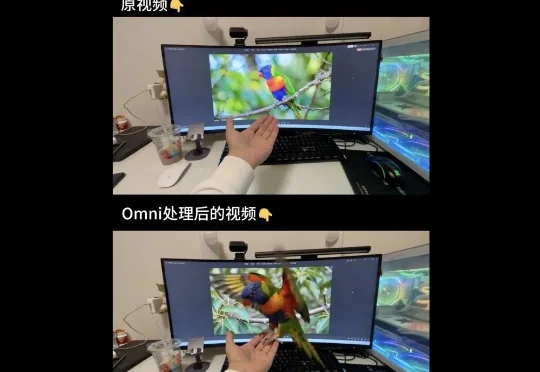
其实Omni Flash和Seedance 2.0还真不一样,Omni Flash的能力是编辑视频,对原有视频的极度控制,而非直接生成视频。先给朋友们看几个实测案例吧,你可能就会有更深的体感。
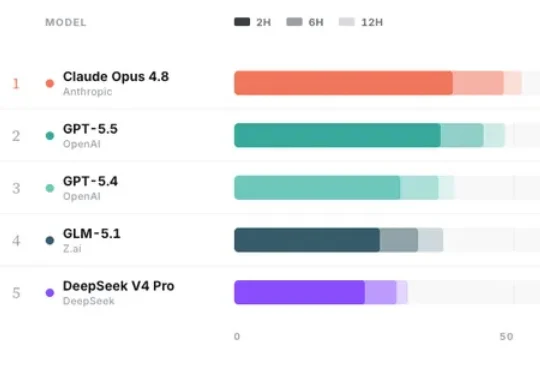
7月2日,字节 Seed 发布了一个 Agent评测项目 EdgeBench。看起来又是一个 benchmark,但它问了一个其他榜单不问的问题。EdgeBench 的切口就是把盲区里的东西放进评测,解答一个问题:把Agent扔进一个陌生环境,12小时后,你能变强多少?

从被排斥到占领好莱坞,字节Seedance你都做了什么??现在好莱坞已经是酱婶儿的了:比如这部95分钟长片《Hell Grind》(地狱磨坊),Higgisfield AI出品。还有这部AI奇幻剧集《骸骨编年史》,包含了6条独立故事线和众多角色:

两万多名快手员工,今年以来最关心的话题就是可灵。 这不仅因为它已成为快手最具想象力的AI业务,还因为5月传出拆分上市的消息后,可灵估值一度超过母公司快手的三分之二。 可灵几乎成为全村的希望。过去的舆论