
Claude强到不敢发的Mythos,被质疑用了字节Seed技术
Claude强到不敢发的Mythos,被质疑用了字节Seed技术Claude最强“神话”模型,可能用到来自字节的技术?
来自主题: AI技术研报
6695 点击 2026-04-13 15:05
 搜索
搜索
Claude最强“神话”模型,可能用到来自字节的技术?

“你好,老板,你这个视频我们用即梦Seedance 2.0 生成,这一条视频报价1235.25元人民币,我们分分钟就可以用这1609.45元做出来这条视频,这可是仅仅2235.32元人民币就能换来的视频爆款,都不知道有多划算,我们产出一条视频仅需要一天,白天开工,到了晚上您只需要支付3245.98元就可以了,现在签合同吗?”

字节Seed最新研究,让大模型能“原地改参数”了。既不用改模型结构,也不用重新训练,还跑得很快。具体是这么个情况。智能体时代嘛,大家都知道模型们面对的任务开始变得越来越复杂、上下文越来越长。

HappyHorse身份曝光,或将明天上线?
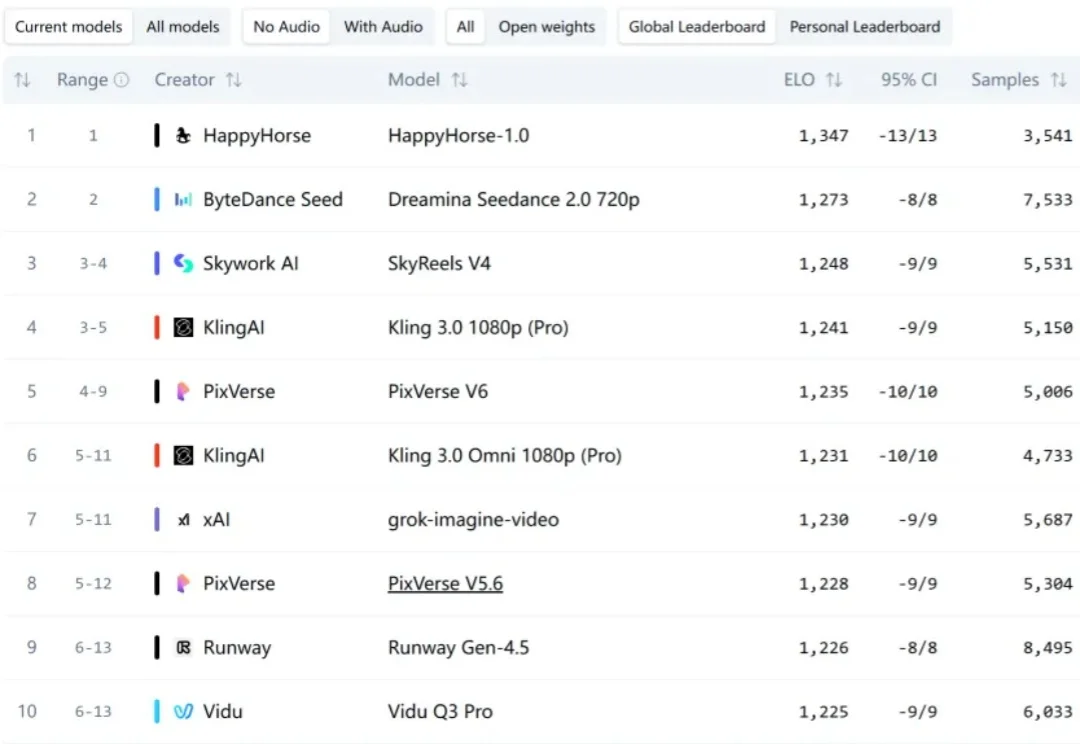
就在 OpenAI 都停了 Sora,所有人以为 Seedance 2.0 要一统天下的时候,没想到不知哪里冒出来一匹马。

AI交互的「机械感」消失了!今天,豆包甩出原生全双工语音大模型Seeduplex,不仅能边听边说,甚至能听懂你在思考时的「卡壳」,就算环境再吵也不怕,抗干扰能力直接拉满。

被动成为新一代 AI 黄埔军校的字节跳动。

最近Seedance 2.0接入大赛开始了,有头有脸的视频agent都当上字节中介原地起飞了。
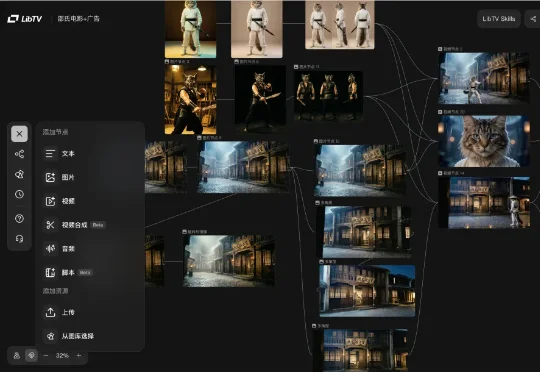
不过,最近有个好用的破局工具。LibTV终于接入了万众瞩目的Seedance 2.0!最关键的是,在LibTV里跑Seedance 2.0,速度非常快,几分钟就能出一条高质量的视频,彻底治好了我的排队焦虑。

每天 120 万亿 Tokens,这就是今天上午火山引擎 AI 创新巡展上,豆包大模型亮出的最新成绩单。