
SPIRAL:零和游戏自对弈成为语言模型推理训练的「免费午餐」
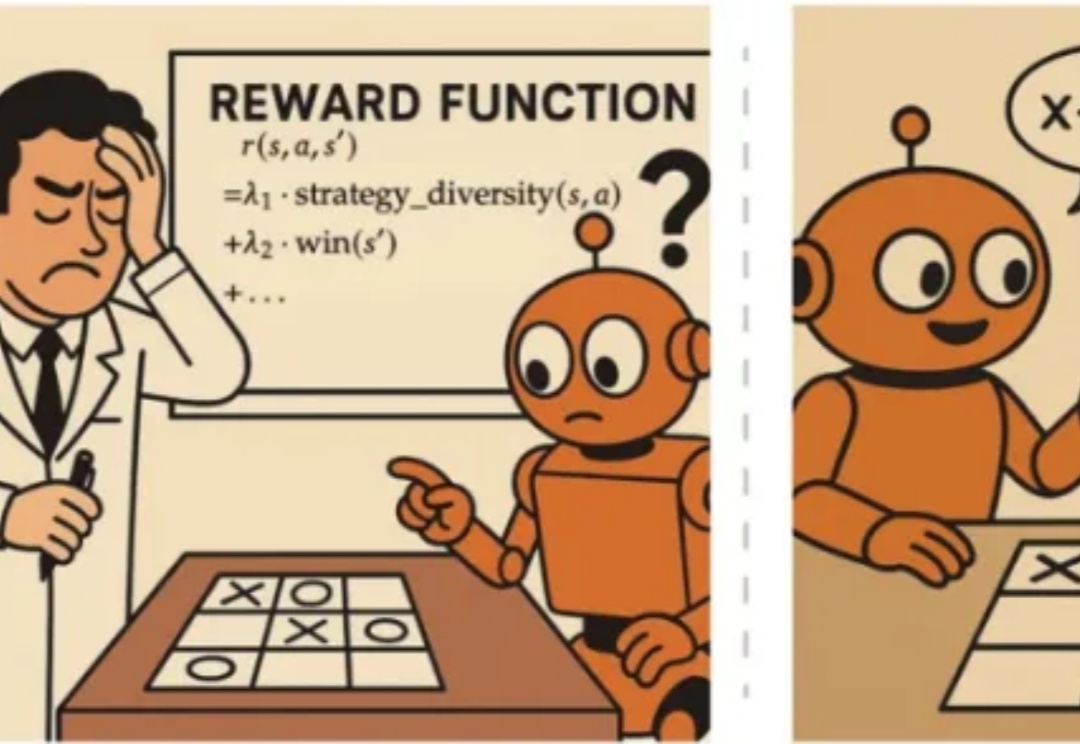
SPIRAL:零和游戏自对弈成为语言模型推理训练的「免费午餐」近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
来自主题: AI技术研报
6634 点击 2025-07-31 10:10
近年来,OpenAI o1 和 DeepSeek-R1 等模型的成功证明了强化学习能够显著提升语言模型的推理能力。通过基于结果的奖励机制,强化学习使模型能够发展出可泛化的推理策略,在复杂问题上取得了监督微调难以企及的进展。
所有人都说,他的初创公司会失败。然而,一年后,它却蓬勃发展:拥有约 50 万注册用户,刚开始收费就有近 3000 名付费用户,以及 GPTs 商店中超过 200 万次对话,屡次被 OpenAI 推荐。