SimKO:缓解RLVR训练中的概率过度集中,优化pass@K性能
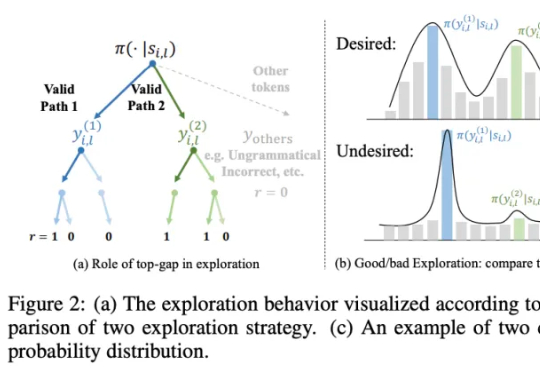
SimKO:缓解RLVR训练中的概率过度集中,优化pass@K性能研究团队提出一种简洁且高效的算法 ——SimKO (Simple Pass@K Optimization),显著优化了 pass@K(K=1 及 K>1)性能。同时,团队认为当前的用熵(Entropy)作为指标衡量多样性存在局限:熵无法具体反映概率分布的形态。如图 2(c)所示,两个具有相同熵值的分布,一个可能包含多个峰值,而另一个则可能高度集中于一个峰值。
来自主题: AI技术研报
8011 点击 2025-11-08 15:48