# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2025 年秋的具身智能赛道正被巨头动态点燃:特斯拉上海超级工厂宣布 Optimus 2.0 量产下线,同步开放开发者平台提供运动控制与环境感知 SDK,试图通过生态共建破解数据孤岛难题;英伟达则在 SIGGRAPH 大会抛出物理 AI 全栈方案,其 Omniverse 平台结合 Cosmos 世界模型可生成高质量合成数据,直指真机数据短缺痛点。
这些热点事件共同指向行业共识:曾被算法创新掩盖的数据问题,才是具身智能落地的根本症结。
针对这个问题,近日,我们与跨维智能创始人、香港中文大学(深圳)教授贾奎,香港中文大学(深圳)助理教授、具身决策实验室主任刘桂良进行了一场深度对话与探讨,试图找到突破具身智能学习枷锁的密钥。

1. Scaling law 在具身智能领域碰到了什么挑战呢?
贾奎:Scaling law 是大语言模型发展过程中所观察到的经验定律,即模型的性能与数据量、模型容量/参数量、算力之间分别存在一个幂函数关系【1,2】,此经验定律有助于在给定的资源条件下,指导如何以最优模型性能为目标的数据、模型与算力分配。
定律的有效性是建立在训练大语言模型所需要的海量文本数据存在的前提,但对于训练具身智能模型,如上所说,领域还没有建立能够支撑scaling law的数据范式,那么定律本身也无法发挥指导作用。
具身智能的发展需要能够对其当前阶段有更好指导意义的新定律,因此在【3】中,我们基于scaling law推导出新的适用当前具身智能发展的新定律,命名为 Efficiency Law。
具体来说,我们首先定义一个叫做“数据生成速率”的量 r_D,在最大允许的模型生产时长的条件下,模型性能与 r_D 存在一个幂函数关系,并受控于一个模型容量的幂函数与一个 r_D 的幂函数的加和,进一步推出,在有限时间内,更高的 r_D 能显著提升学习效率,从而通过训练大容量模型提升实际性能,而过低的 r_D 会导致模型进入“数据稀缺区”,使规律失效。
通俗解释,Efficiency Law的核心观点是:在有限的时间内,决定具身模型性能上限的,是生成高质量数据的速率(我们称之为r_D)。数据生成速率越快,就能越快地“喂饱”一个大模型,从而突破性能瓶颈。如果速率太慢,模型就会一直处于‘吃不饱’的‘数据稀缺区’,再大的潜力也发挥不出来。所以,具身智能的重点必须从‘堆数据’转向‘高效造数据’。
因此,具身智能的发展必须从“采数据”和“堆数据”转向“高效地造数据”;通过提高高质量数据的生成与利用效率,建立起支撑具身智能发展的新学习范式。
2. 当前基于视频生成的世界模型,有什么不足之处?
贾奎:当前基于视频生成的世界模型【4,5】虽然能够生成视觉上连贯、动态一致的视频序列,但它们主要在像素层面进行统计学习,追求的是“视觉逼真”而非“物理正确”【6】。
这类模型往往缺乏对真实物理规律的理解,无法准确模拟如摩擦、质量、受力、流体等底层动力学机制,其生成结果更多依赖训练数据的分布而非因果计算,因此在面对分布外情境时容易产生违反物理常识的反事实场景。
对于具身智能而言,学习的核心在于建立真实世界中的感知、行动、反馈循环,智能体必须遵循牛顿力学等物理法则来实现可执行的行为。因此,具身智能所依赖的世界模型【7,8】必须具备物理精确性,能够针对刚体、软体、流体等显式三维表征,根据动力学、运动学原理预测世界状态变化计算系统的内部状态,推理被遮挡或未观测到的元素变化,保持运行过程中的时序一致性,并支持世界状态的存储与恢复,以实现精确的仿真与规划。唯有如此,世界模型才能为具身智能提供符合真实物理约束的环境基础,支撑其在现实世界中的可执行学习与决策。

3. 您能展开阐述一下“基于生成式仿真的世界模型”的内涵,原理,和基本属性么,它能如何解决视频世界模型的不足之处?
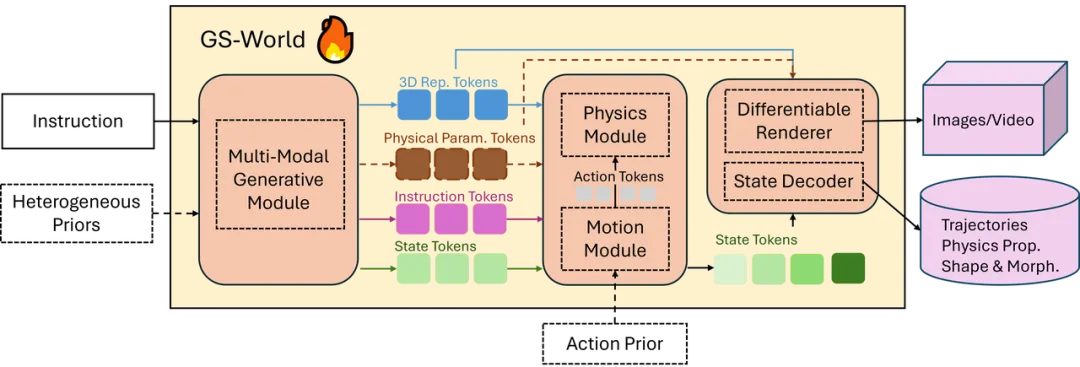
刘桂良:我们在【3】提出了基于生成式仿真的世界模型,即 World Models of Generative Simulation (GS-World)。它是一种将生成模型与物理仿真引擎深度融合的新型世界模型,它从根本上改变了“世界生成”的机制。
传统基于视频生成的世界模型主要在像素层学习数据分布,追求视觉上的逼真,却无法保证物理规律的正确性;而 GS-World 则在生成过程中显式或隐式地引入物理仿真,将生成模型与可微分的物理仿真结合,使世界的动态演化遵循真实的力学等方程。
它不仅生成场景的视觉外观,还同时生成三维资产、物体材质、物理参数与交互规则,从源头上保证运动、碰撞、受力等现象的因果合理性。由于内部状态可被显式计算与反向传播,GS-World 能支持智能体在仿真环境中真实地行动、学习与验证,既具备可控性又具备物理精度,从而摆脱了视频模型依赖数据分布记忆、无法泛化和反事实失真的局限。
简而言之,GS-World 把“看起来像真的世界”真正变成了“遵循物理规律可计算的世界”,为具身智能提供了可信赖的学习与推理基础。

4. “基于生成式仿真的世界模型”,有什么潜在的用途?
贾奎:我们所提出的GS-World具有极高的潜在应用价值,它不仅是一种新的技术形态,更代表着“世界模型”的终极方向。
首先,GS-World 能够在物理上精确建模和预测世界动态,真实地生成三维环境、物体属性及其物理交互规律,从而解决了 Sora2 等视频生成模型仅具视觉拟真、缺乏物理一致性的问题。在这种框架下,视频生成仅是一个“自然副产物”,系统可通过任意视角的可微渲染输出视频,而其本质是一个能够内蕴计算完整物理因果过程的引擎。
其次,GS-World 也是强化学习领域中长期追求的“model-based RL 的终极模型”,它能够在仿真空间内构建世界动力学并进行高保真策略验证,实现虚拟试错与策略优化的闭环学习。
与此同时,有了 GS-World,VLA模型的学习将变得极为便利:系统无需依赖昂贵的真实机器人数据采集即可通过仿真世界自动生成多模态训练数据,并在物理精确的环境中实现策略验证与微调。
最根本地,GS-World 能作为一个通用智能引擎(Engine),驱动持续、流式的具身智能学习,使得它能自动生成、仿真、评估和反向优化整个学习过程,使智能体在不断变化的虚拟物理世界中自主学习与进化,从而开辟“引擎驱动的具身智能”这一全新的学习范式。
5. 您能介绍一下“基于生成式仿真的世界模型”作为引擎,如何形成新的具身智能学习范式?
贾奎:GS-World推动了一个全新的“引擎驱动的具身智能学习范式”。
相比当前基于任务开发的Sim2Real路径或Real2Sim2Real等变种,GS-World 能主动生成并仿真物理精确的三维世界,使智能体在其中感知、行动、试错与学习,形成“生成—交互—反馈—优化”的闭环。
它不仅让世界具备因果可计算性与自演化能力,还使智能体的策略学习、任务构建与环境生成融为一体,从而实现流式、自我进化的具身智能训练体系。
这种引擎驱动(engine-driven)的 Sim2Real VLA 范式,使智能体真正能在生成并物理自洽的世界中持续成长,为通用具身智能的自主学习奠定了核心引擎基础。
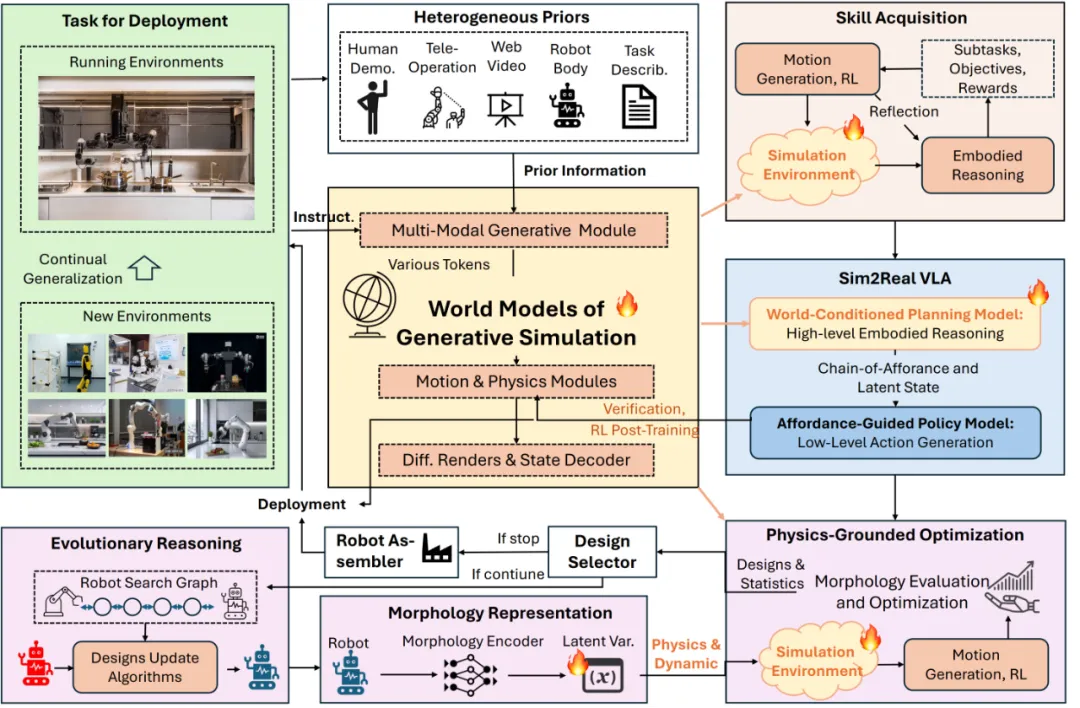
6. 这种范式如何实现efficiency law, 它还有什么其他好的属性?
刘桂良:GS-World是实现efficiency law的核心机制。
首先,GS-World 将“世界生成、物理仿真、任务构建、反馈优化”整合为一个可微分、可自进化的统一引擎,使智能体的训练过程由被动的数据驱动转向主动的任务生成与环境演化。这样,世界与智能体共同构成一个自激励、自循环的学习系统,智能增长速度将与生成仿真能力成正比,体现出学习效率随数据生成速率(r_D)的 efficiency law。
其次,GS-World 通过可控生成能力构建无限多样的物理环境与任务空间,使智能体能够在统一的世界模型框架下同时学习多任务、多模态、多物理规律的行为,从而实现“通才化(generalist)”的认知扩展。同时,引擎还具备精细化的分布调节能力,可针对特定任务、技能或物理机制自动收缩学习空间、聚焦优化,形成“专才化(specialist)”的高效学习结构【9】。
也就是说,GS-World 提供了一个既能横向扩展智能广度、又能纵向精化智能深度的动态引擎,使具身智能得以在高效率、强自适应和持续演化的闭环中不断生长。
这种具备自动化、可扩展与弹性特征的引擎机制,为未来的具身智能建立了一种真正可自组织、自演化的学习生态。

7. 您能展开描述一下“数据驱动”与“引擎驱动”的具身智能学习,范式上有什么本质不同?
刘桂良:数据驱动的具身智能学习以外部数据为中心,智能体被动地从过去的经验分布中提取规律,缺乏对物理世界的显式建模,因此学习受限、扩展性差、缺乏因果一致性。
而引擎驱动的具身智能学习则以生成式仿真引擎(GS-World)为核心,让智能体在一个可生成、可演化、可验证的世界中自主学习,通过闭环交互持续生成数据、构建因果模型并优化策略。它不依赖外部数据供给,而依靠自身生成能力驱动智能持续增长,实现学习效率、泛化能力与可解释性的全面跃升。
简而言之,从数据驱动到引擎驱动,是具身智能从“模仿现实”走向“生成现实”的根本范式转变。

8. 为什么要实现产品级成功率和鲁棒抗干扰性的具身智能,世界模型引擎驱动的学习范式是必然选项?
贾奎:在家庭、商业和工业等复杂真实场景中,机器人只有在具备物理精确性、抗环境扰动能力及泛化安全性的前提下,才能实现产品级的稳定性与成功率。
传统数据驱动方法只能从表象数据中学习统计相关性,缺乏与现实物理一致的因果约束,因而在遇到扰动或未见场景时性能崩溃。
而基于 GS-World 的引擎驱动学习范式,能够从根本上构建物理一致的可生成世界,让智能体在仿真中经历无限真实的交互与试错过程,自主习得对复杂力学、噪声和变化的补偿策略,从而自然获得鲁棒性、泛化力与安全性。
这意味着:要实现真正可部署、可靠且可信赖的具身智能产品,引擎驱动的世界模型学习已不是一个可选方向,而是必然的技术路径。
9. 机器人的技能是如何在“基于生成式仿真的世界模型”中产生和训练的?
刘桂良:在 GS-World 中,机器人技能不再是人类手工设计的任务脚本,而是通过引擎生成的物理世界中自然“挖掘”出来的。
该模型通过生成真实物理交互的世界,使技能在仿真中经由交互、优化与验证逐步形成;通过多模态表示与动作语法机制,这些技能又能抽象、组合与迁移,形成具可扩展性的技能生态。最终,凭借世界模型的物理准确性与仿真鲁棒性,以及引擎的连续域随机和域适应能力,这些在虚拟世界中学习的技能能够安全而高保真地迁移至现实环境,实现从生成世界到学习行为再到迁移现实的闭环。
这意味着,在 GS-World 引擎中,技能成为具身智能内生的、可解释、可扩展、可复用的智能基元,是未来通用机器人能力的核心生成机制。

10. 如何理解“基于生成式仿真的世界模型”是具身智能机器人的演化场?
贾奎:GS-World 之所以是具身智能机器人的演化场,在于它让智能体的身体结构、控制策略与环境动力学在同一物理生成机制下共同演化【10】。
GS‑World 通过可微分的物理仿真、图结构的形态表示及仿生搜索机制,使机器人能够在虚拟但物理一致的世界中不断重塑自身形态、优化行为并积累演化经验。
它提供的不只是训练环境,而是一个能促使机器人实现身体与智能协同生长、自组织、自适应的物理‑认知生态场;在这个意义上,GS‑World 成为具身智能机器人从“人工设计产物”走向“自演化生命体”的关键跃迁平台,从而实现让人工智能定义机器人本体。
AGI、Physical AGI 与具身智能正处在高速发展的阶段,行业迫切期待一种基于第一性原理、能与具体任务场景深度匹配且具备高性价比的新技术范式。
而跨维智能联合香港中文大学(深圳)提出的GS-World 世界模型引擎,以及基于该引擎的具身智能学习新范式,正是这一范式的典型代表。
据悉,GS-World 引擎原型以及基于其自动训练的VLA 模型也将于近期开源。期待更多产业及学术研究人员投入到这一极具潜力的新方向,共同推进具身智能产业的快速发展与广泛落地。
参考文献
【1】Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361, 2020.
【2】Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, Tom Hennigan, Eric Noland, Katie Millican, George van den Driessche, Bogdan Damoc, Aurelia Guy, Simon Osindero, Karen Simonyan, Erich Elsen, Jack W. Rae, Oriol Vinyals, and Laurent Sifre. Training compute-optimal large language models. arXiv preprint arXiv:2203.15556, 2022.
【3】Guiliang Liu, Yueci Deng, Zhen Liu, Kui Jia,GS-World: An Engine-driven Learning Paradigm for Pursuing Embodied Intelligence using World Models of Generative Simulation, Open Review, 2025.
【4】NVIDIA, Alisson Azzolini, Hannah Brandon, Prithvijit Chattopadhyay, Huayu Chen, et al. Cosmos-reason1: from physical common sense to embodied reasoning. arXiv preprint arXiv:2503.15558, 2025.
【5】OpenAI. Sora: creating video from text, 2024.
【6】Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video models understand physical principles? arXiv preprint arXiv:2501.09038, 2025.
【7】David Ha and Jurgen Schmidhuber. World models. CoRR, abs/1803.10122, 2018.
【8】Yann LeCun. A path towards autonomous machine intelligence. Open Review, 2022.
【9】Kaiyan Zhang, Biqing Qi, and Bowen Zhou. Towards building specialized generalist ai with system 1 and system 2 fusion. arXiv preprint arXiv:2205.11487, 2024.
【10】Luca Carlone and Carlo Pinciroli. Robot co-design: beyond the monotone case. In IEEE International Conference on Robotics and Automation (ICRA), pages 3024–3030, 2019.
文章来自于“机器中心”,作者“机器之心编辑部”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
