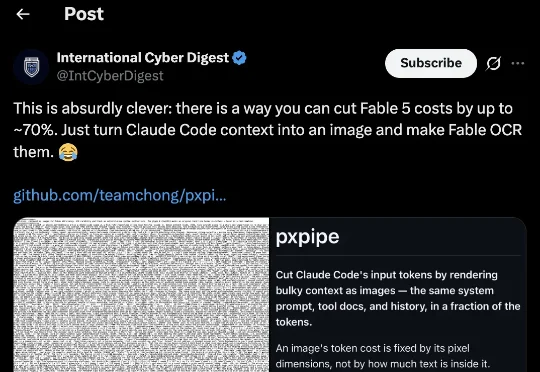
Fable 5被网友薅出省钱神招!pxpipe最高让token减70%!
Fable 5被网友薅出省钱神招!pxpipe最高让token减70%!这两天,有位机智的老哥发现,只要把Fable 5的上下文转换成一张张密密麻麻写满文字的图片,再让模型通过OCR读回来,token输入成本最多能省下70%。更离谱的是,不只是普通对话,系统提示、工具文档、历史记录,全都能一股脑塞进图里。
来自主题: AI资讯
8856 点击 2026-07-06 12:25
 搜索
搜索
这两天,有位机智的老哥发现,只要把Fable 5的上下文转换成一张张密密麻麻写满文字的图片,再让模型通过OCR读回来,token输入成本最多能省下70%。更离谱的是,不只是普通对话,系统提示、工具文档、历史记录,全都能一股脑塞进图里。

Bug Team 最新力作,在疯狂星期四落下帷幕,其实 K12 的教师空间就是 Bug Team 的另外一种业务模式,他同样是有管理员和普通用户。 也有邀请和被邀请的功能,完全不知道 OpenAI 到底如何能写出这么匪夷所思的代码的,他的后端权限接口竟然没有鉴权,允许用户非受邀主动加入 K12 的教师空间,然后再拥有非管理员审批的权限,唯一的要求就是需要使用同一个域名邮箱
埃森哲的 AI 策略负责人最近在一次内部会议上,吐槽了公司里消耗 AI 算力的情况:驱动 token 消耗的,不是工程师在做开发,是非技术人员在用 AI 把 PDF 转成 PPT。 这怎么是滥用呢?堂堂埃森哲一个咨询公司,做 PPT 才是正经事啊!

做大模型RL微调,你是不是也踩过这些坑?

哈喽朋友们,最近也是囤上 Codex 的重置额度了。

刚刚,Anthropic正式官宣:Fable 5回来了!就这简单的一句话,让全网奔走相告。苦等19天,所有人像过年一样冲回Claude,就为了亲眼确认那个熟悉的名字重新亮起。而且千万注意,一旦额度达上限,Fable 5跑起来的Token消耗远超Opus 4.8。

大模型公司在港股热度正酣,现在,卖Token的公司也开始冲刺了。硅基流动已向港交所提交上市申请,剑指港股「AI Token工厂第一股」。此前,硅基流动已完成7轮融资,估值77.4亿元。阿里、美团、商汤、蔚来、智谱等产业方和明星AI投资机构均有押注。

2026年,具身智能赛道的融资热度仍在持续,但投资人的提问方式已经变了。
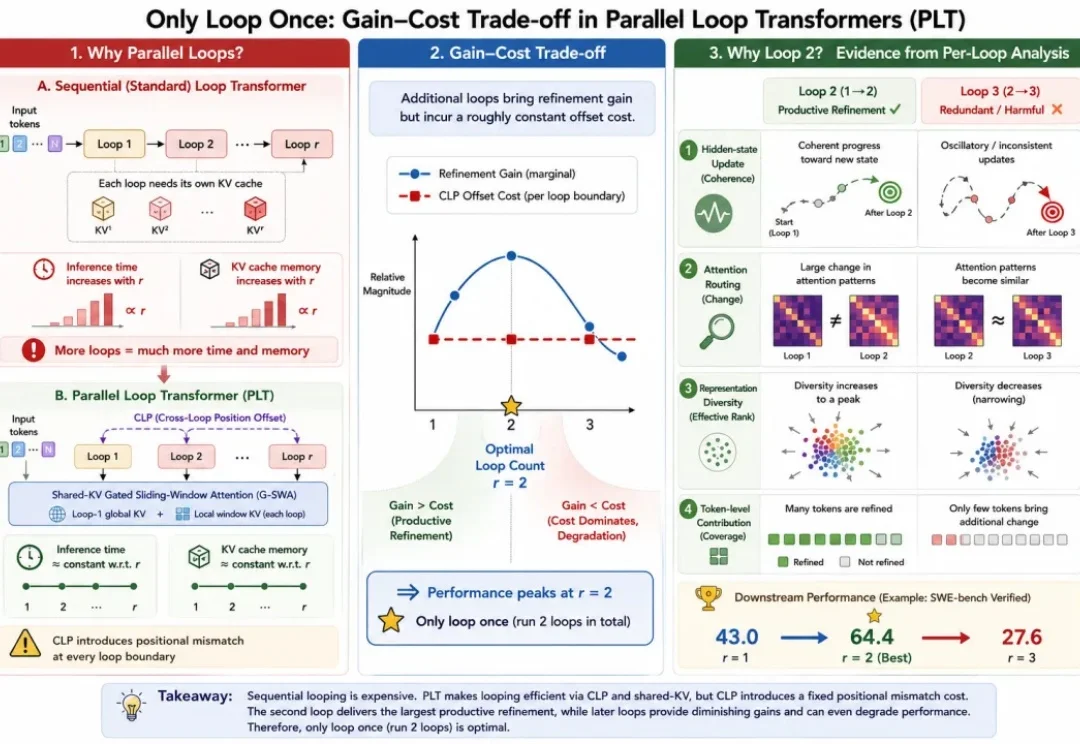
当所有人都在比谁「想得更久、算得更多」——推理模型动辄输出成千上万个思考 token,循环式架构恨不得在内部反复迭代十遍八遍——一项新研究反手泼了盆冷水:

如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?