
扩散模型自引导新范式:直接交换token就能变强! | CVPR‘26 Oral
扩散模型自引导新范式:直接交换token就能变强! | CVPR‘26 Oral扩散模型又被玩出新花样了。
来自主题: AI技术研报
8479 点击 2026-06-25 15:00
 搜索
搜索
扩散模型又被玩出新花样了。

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。

大厂把AI按token租给你,River AI想让你直接拥有它,这是Babuschkin出走xAI后打出的第一张牌。
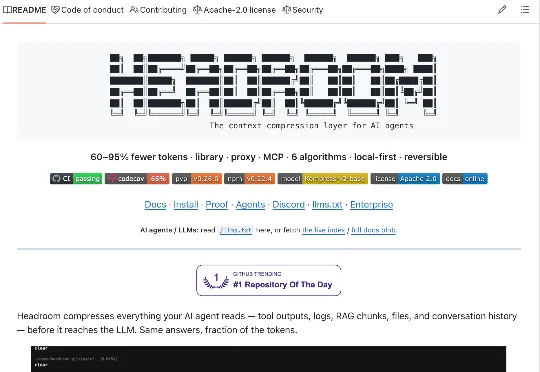
一个开源的省Token工具Headroom,火了!公开页面显示Headroom已有4万多个star,最新版本是v0.26.0。一个“上下文压缩层”工具能到这个热度,已经说明很多问题。
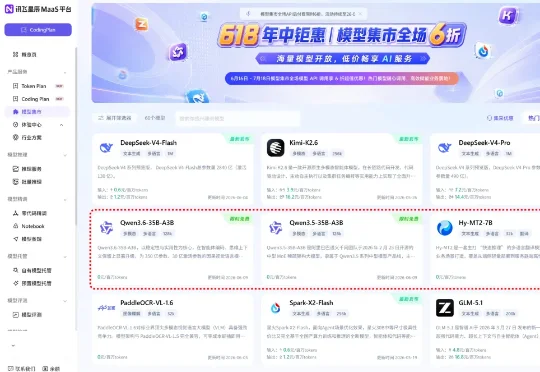
前几天听说讯飞星辰 MaaS 平台在做活动,一些模型可以限时免费调用,我第一反应就是先领了再说。这次活动限时开放了 Qwen3.6-35B-A3B 和 Qwen3.5-35B-A3B 两个模型的免费调用权益,新老用户都可以参与。

早在3月20日,纽约时报的凯文·罗斯就发现了在硅谷开发者中,出现了一种叫做 Tokenmaxxing的现象。这个现象最早出现在OpenAI、Anthropic等前沿模型开发公司。OpenAI 的工程师一周用了 2100 亿个token,大概是 33 个维基百科的量;Claude Code 的工程师则一个月单人可以烧15万美元token。

全模态算力狂欢开启:全球前十AI巨头无限期免费API,周调用爆破3.12万亿Token!本周Agnes的王炸升级了:1M超长上下文+4K超清画质「零成本」白嫖,开源社区已玩疯,独立开发者和小团队速来薅秃!

AI时代,Token正成为新的“硬通货”。
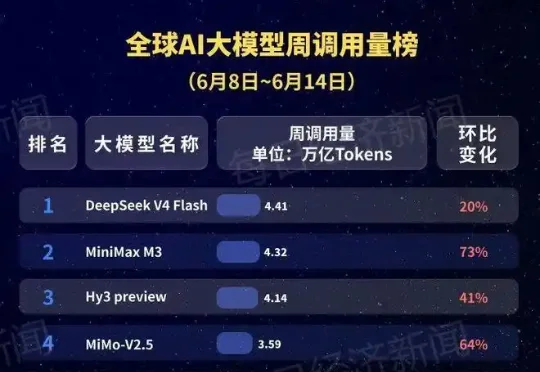
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。

大家好,我是袋鼠帝。 6月,感觉又是模型爆发的月份。