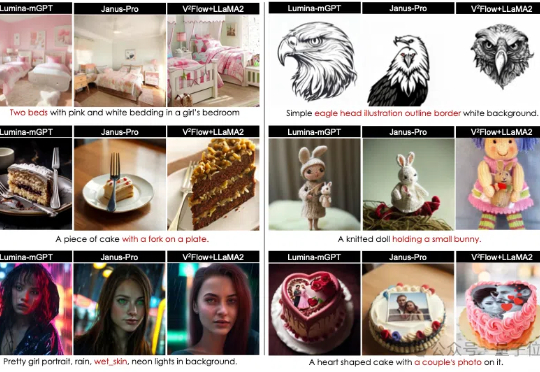
视觉Token无缝对齐LLMs词表!V²Flow:基于LLMs实现高保真自回归图像生成
视觉Token无缝对齐LLMs词表!V²Flow:基于LLMs实现高保真自回归图像生成视觉Token可以与LLMs词表无缝对齐了!
来自主题: AI技术研报
9727 点击 2025-04-03 15:48
 搜索
搜索
视觉Token可以与LLMs词表无缝对齐了!

当我们看到一张猫咪照片时,大脑自然就能识别「这是一只猫」。但对计算机来说,它看到的是一个巨大的数字矩阵 —— 假设是一张 1000×1000 像素的彩色图片,实际上是一个包含 300 万个数字的数据集(1000×1000×3 个颜色通道)。每个数字代表一个像素点的颜色深浅,从 0 到 255。

研究者提出了FAST,一种高效的动作Tokenizer。通过结合离散余弦变换(DCT)和字节对编码(BPE),FAST显著缩短了训练时间,并且能高效地学习和执行复杂任务,标志着机器人自回归Transformer训练的一个重要突破。
2019 年问世的 GPT-2,其 tokenizer 使用了 BPE 算法,这种算法至今仍很常见,但这种方式是最优的吗?来自 HuggingFace 的一篇文章给出了解释。

Sora、Genie等模型会都用到的Tokenizer,微软下手了—— 开源了一套全能的Video Tokenizer,名为VidTok。

BLT 在许多基准测试中超越了基于 token 的架构。
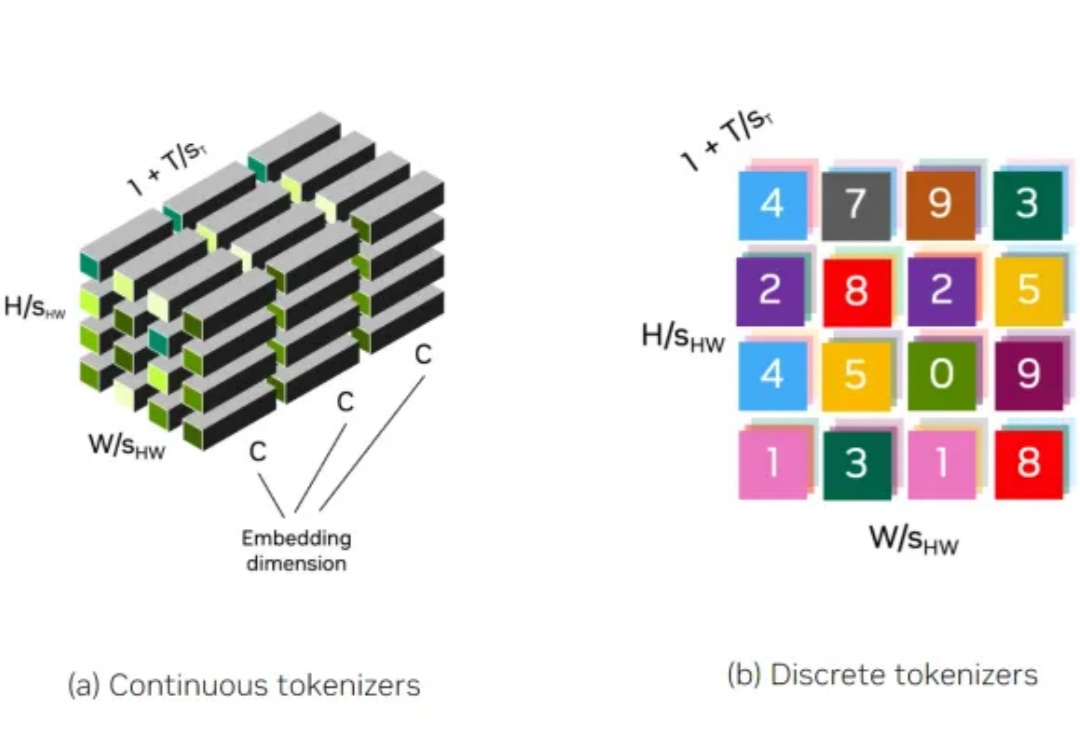
tokenizer对于图像、视频生成的重要性值得重视。
只需Image Tokenizer,Llama也能做图像生成了,而且效果超过了扩散模型。

在生成式模型的迅速发展中,Image Tokenization 扮演着一个很重要的角色,例如Diffusion依赖的VAE或者是Transformer依赖的VQGAN。这些Tokenizers会将图像编码至一个更为紧凑的隐空间(latent space),使得生成高分辨率图像更有效率。
技术大神卡帕西离职OpenAI以后,营业可谓相当积极啊。