

最具争议性研究:大模型中间层输出可 100% 反推原始输入
最具争议性研究:大模型中间层输出可 100% 反推原始输入Transformer 语言模型具有单射性,隐藏状态可无损重构输入信息。
来自主题: AI技术研报
9371 点击 2025-11-04 11:32
Transformer 语言模型具有单射性,隐藏状态可无损重构输入信息。
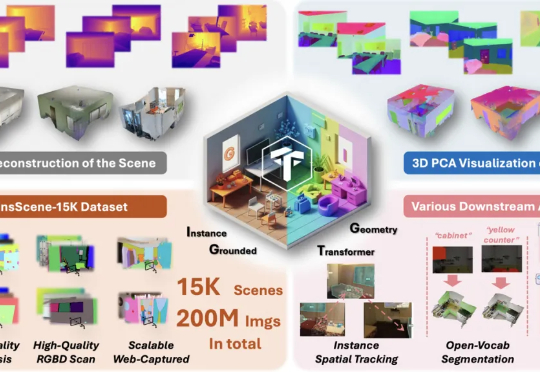
现在,NTU联合StepFun提出了IGGT (Instance-Grounded Geometry Transformer) ,一个创新的端到端大型统一Transformer,首次将空间重建与实例级上下文理解融为一体。

最近的 Meta 可谓大动作不断,一边疯狂裁人,一边又高强度产出论文。

Transformer之父「叛逃」?8年前掀起AI革命的男人,如今嫌「自己孩子」太吵太卷!当资本狂飙、论文堆积如山,他却高喊:是时候放弃Transformer,重新找回好奇心了。

近日,范鹤鹤(浙江大学)、杨易(浙江大学)、Mohan Kankanhalli(新加坡国立大学)和吴飞(浙江大学)四位老师提出了一种具有划时代意义的神经网络基础操作——Translution。 该研究认为,神经网络对某种类型数据建模的本质是:
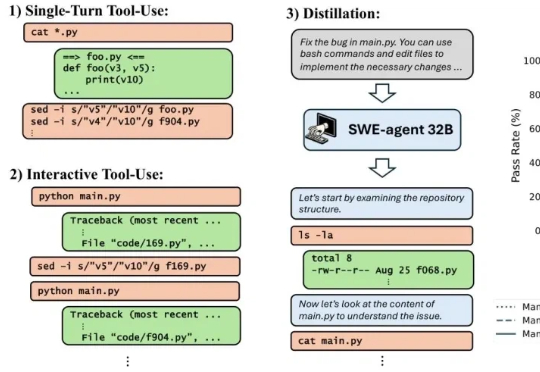
都说苹果AI慢半拍,没想到新研究直接在Transformer头上动土。(doge) 「Mamba+工具」,在Agent场景更能打!

在近日的一次访谈中,Andrej Karpathy深入探讨了AGI、智能体与AI未来十年的走向。他认为当前的「智能体」仍处早期阶段,强化学习虽不完美,却是目前的最优解。他预测未来10年的AI架构仍然可能是类似Transformer的巨大神经网络。
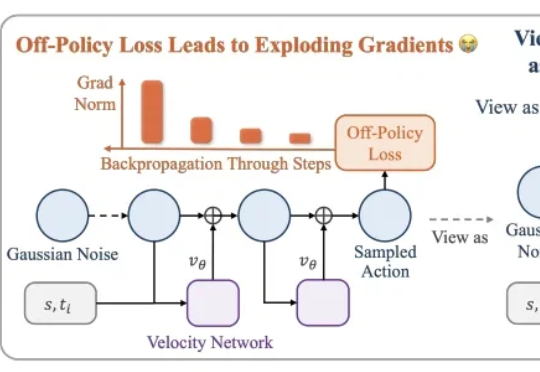
本文介绍了一种用高数据效率强化学习算法 SAC 训练流策略的新方案,可以端到端优化真实的流策略,而无需采用替代目标或者策略蒸馏。SAC FLow 的核心思想是把流策略视作一个 residual RNN,再用 GRU 门控和 Transformer Decoder 两套速度参数化。
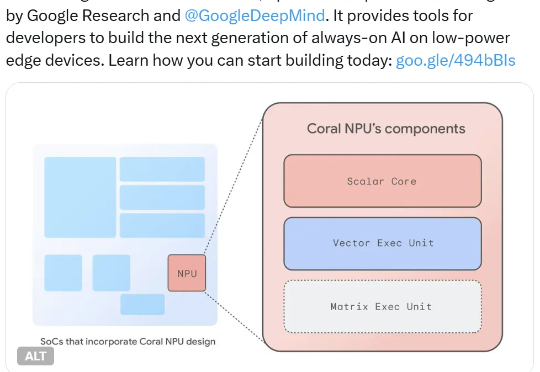
他们又推出了 Coral NPU,可用于构建在低功率设备上持续运行的 AI。具体来说,其可在可穿戴设备上运行小型 Transformer 模型和 LLM,并可通过 IREE 和 TFLM 编译器支持 TensorFlow、JAX 和 PyTorch。
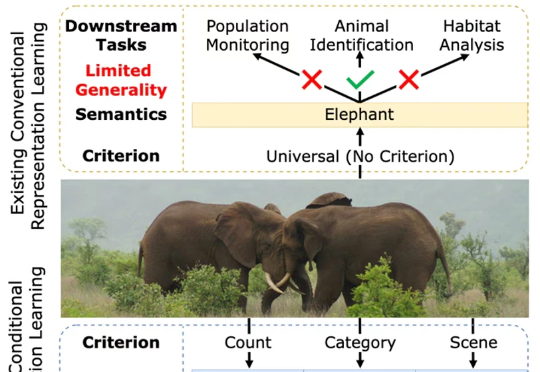
一张图片包含的信息是多维的。例如下面的图 1,我们至少可以得到三个层面的信息:主体是大象,数量有两头,环境是热带稀树草原(savanna)。然而,如果由传统的表征学习方法来处理这张图片,比方说就将其送入一个在 ImageNet 上训练好的 ResNet 或者 Vision Transformer,往往得到的表征只会体现其主体信息,也就是会简单地将该图片归为大象这一类别。这显然是不合理的。