# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
尽管Transformer架构已经主宰了当今几乎所有的大模型,但我们依旧对它的工作原理知之甚少。
而且,基于Transformer的预训练LLM动辄有几十亿参数,很难直接对模型进行可解释性分析。
同时,模型中间层由N个相同的块堆叠在一起,它们之间唯一的区别只有层次位置和权重值,这就让理解中间层更加困难。
然而,最近发表的一篇论文却给出了一个十分通俗易懂的比喻——「画家流水线」。

论文地址:https://arxiv.org/pdf/2407.09298v1
有着「东京AI梦之队」之称的Sakana AI,联合IBM前AI负责人Satya Nitta创始的Emergence AI,两个团队的研究人员用一种新的「打开方式」来解释Transformer架构的中间层。
值得一提的是,这篇论文作者之一Llion Jones同样也是当年Transformer架构的共同创建者之一。

那么,「画家流水线」这个比喻该如何理解呢?
首先,输入被看作是一张画布,输入通过N个组成中间层的块的过程,就像是画布在「画家流水线」上进行传递的过程。
有些画家擅长画鸟,而有些画家则更擅长画鱼。每个画家从前面的画家手中接过画布,然后决定是在画上添几笔,还是直接传给后面的画家。
在这个类比中,非常重要的一点是,每个画家都使用相同的「词汇」来理解画作,因此一个画家可以在流水线上从前一个画家手中接过画作,但不会因为对画面理解不同而造成灾难。
画家们也可以重新排序(调整图层的前后顺序),甚至可以同时添加笔触,就像N个块可以并行运行。
这个类比并不是一个严谨的理论,但可以提供一个帮助我们思考Transformer层的有趣视角。
在这个类比的启发下,研究人员提出了一些假设,并通过实验来验证这些假设是否成立——
实验
主要用于实验包括两种预训练LLM,分别是decoder-only架构的Llama2-7B,以及encoder-only架构的BERT。Llama2-7B有70亿个参数和32层(每层含2.02亿个参数),BERT仅有24层和3.4亿个参数。
在下述所有实验过程中,模型都是冻结的。除了对BERT进行GLUE基准测试时进行了标准的微调步骤,参数没有经过任何修改。
评估过程采用了ARC(科学考试题)、HellaSwag(常识)、GSM8K(数学应用题)、LAMBADA(单词预测)等常用基准。
其中LAMBADA任务可以衡量模型困惑度(perplexity),任务最接近预训练时的原始token预测。
结果发现,Transformer的中间层有一定程度的一致性,但不冗余,而且对数学、推理任务而言,各层的运行顺序比在语义任务中有更重要的影响。
Transformer中的不同层是否共享相同的表示空间?
为了回答这个问题,论文采用的方法是让模型跳过特定层或调换相邻层的顺序,观察会不会出现灾难性后果。
图2中展示了Llama 2 7B在跳过或调换一些层后,模型整体在Open-LAMADA基准上的表现。
可以看到,除了起始和末端的几层,模型对这两种架构修改都表现出了相当强的鲁棒性。
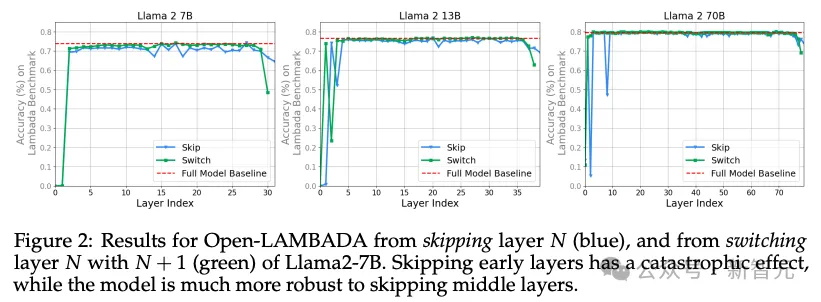
因此可以得出初步结论:1)中间层共享同一个表示空间,2)表示空间与「外层」(第一层和最后几层)不同。
为了进一步验证,论文还进入模型内部,测量了不同层中隐藏状态内激活函数的余弦相似度(图3),表明这种一致性在三个模型的所有中间层都成立。
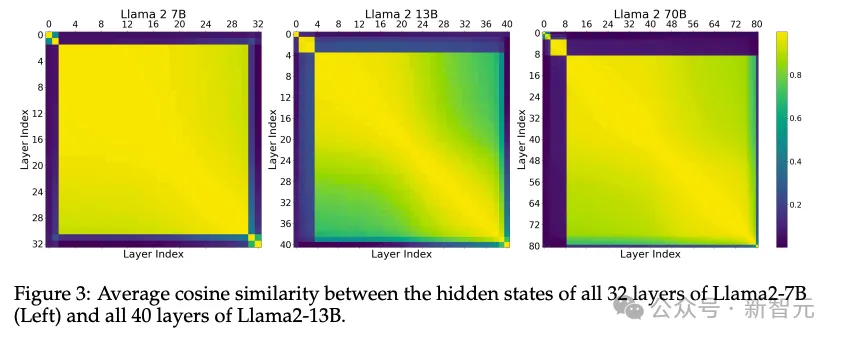
上图还可以很清晰看到,模型各层自然形成了4~5个不同的相似组,比如Llama 2 13B模型中分别是:第0层,1-3层、中间层,以及最后的1层或2层。
据此,Transformer中的所有层可以被大致分为三类:起始层、中间层和结束层。
此外,图3中的矩阵也能和图2中的模型分数相对应,更能有力证明,中间层之间共享语义表达空间。
为了进一步检验中间层的重定向空间是否真正共享(除了具有接近的余弦相似性),研究人员尝试跳过多个层。
也就是说,将第N层的输出直接送入第N+M层的输入(其中M>1),从而「跳过」M-1层。

在不进行任何微调的情况下,这个实验是要看看N+M层能否理解来自N层的激活,尽管它在训练中只接受了来自N+M-1层的输入。
结果显示,Llama2-7B和BERT-Large的许多基准性能都出现了一定程度的下降。
那么,所有层都有必要吗?这一问题已经有了答案。
No! 并非所有层都是必要的,至少有几个中间层可以跳过,而不会发生灾难性故障。
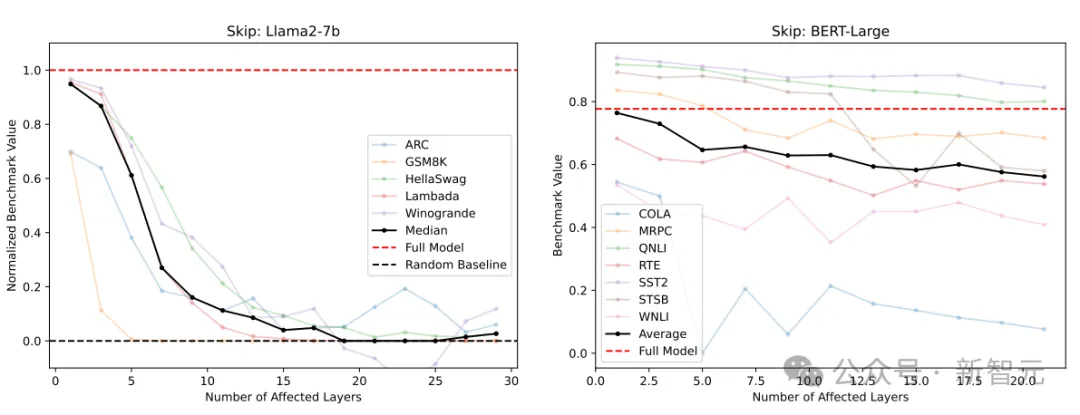
左图:Llama2-7B跳过N层~32-N层的基准测试结果(归一化);右图:BERT跳过N层~24-N 层的基准测试结果(未归一化)
如果中间层共享一个共同的表征空间,这是否意味着这些层是多余的呢?
为了验证这一点,研究人员重新进行了上一小节的「跳过」实验。
但不同的是,这次不是直接跳过M个中间层,而是用模型最中心的的一层代替全部M个层(Llama是第16层,BERT是第12层),相当于在这一层上循环T-2N+1次,其中T是层的总数。
结果表明,随着被替换层数M的增加,基准测试结果迅速下降。
在研究人员所尝试的所有测试中,这一项测试的变化是最严重的,比直接跳过一些层还要严重得多。
因此,中间层功能相同吗?这一问题的答案是——
No! 在中间层之间共享权重是灾难性的,这表明中间层在执行不同的功能。
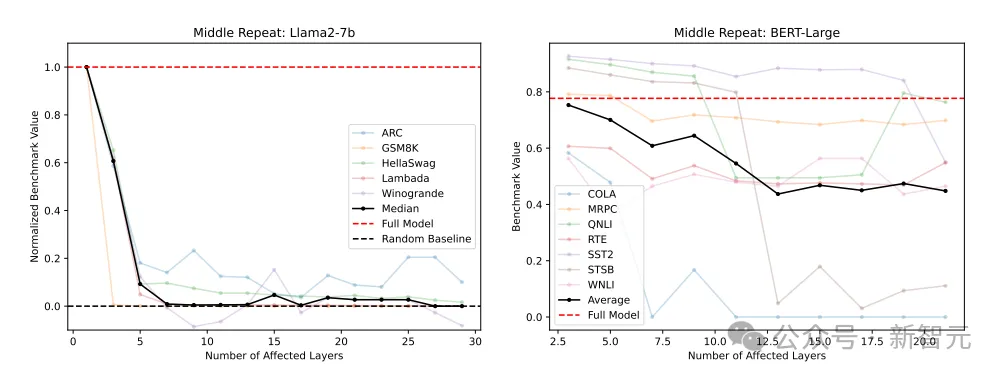
用中心层替换M个中间层(左侧经过归一化,右侧未经归一化)
之前的实验表明,中间层共享一个表征空间,但对这个空间执行不同的操作。
那么另一个问题来了——这些操作的执行顺序有多重要?
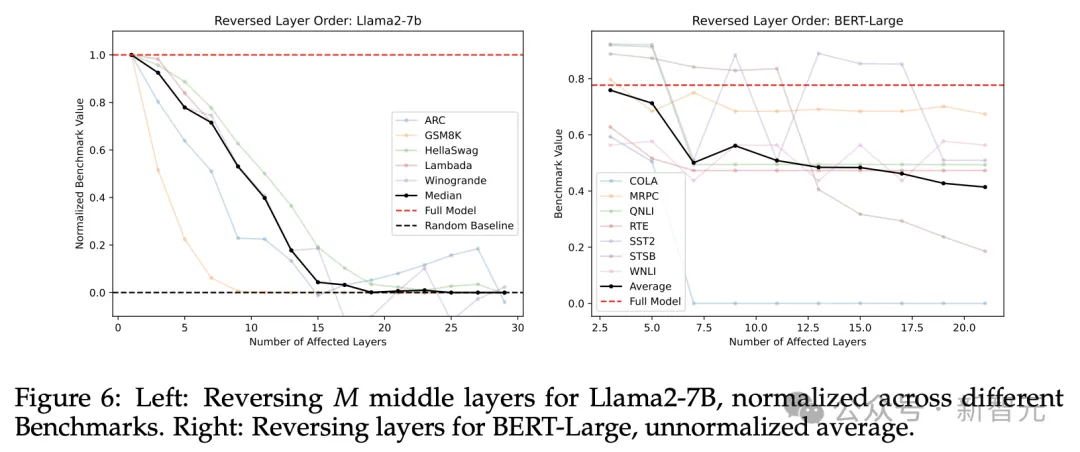
论文进行了两组实验来检验这个问题。首先,以与预训练完全相反的顺序运行中间层,如下图所示:
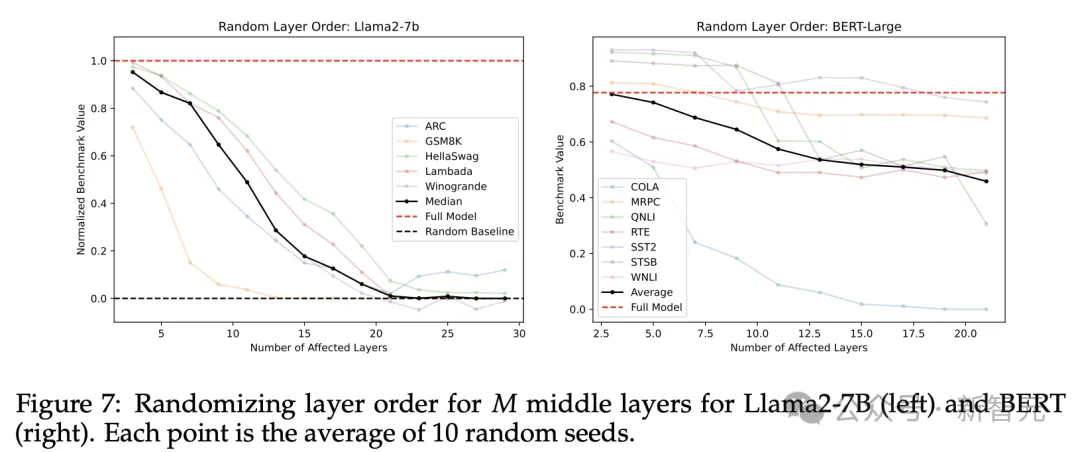
第二组则是以随机顺序运行中间层,最终结果是取10个随机种子进行实验后的均值。
图6和图7分别展示了中间层完全翻转和随机顺序的结果,虽然都出现了一定程度的性能下降,但两者的结果都优于直接跳过的情况。
所以,中间层顺序重要吗?这一问题的答案是——
比较重要。改变中间层的执行顺序,无论是随机打乱或者完全翻转,都会导致模型性能退化。
如果层本身的存在比它们的执行顺序更重要,那么我们是否可以独立运行各层,最后合并它们的结果呢?
比如像下图中,将原本堆叠在一起的中间层展开,并行运行后取各层输出的平均值,传递给最后的N个层。
实验结果显示,GSM8K(数学应用题)基准中,模型性能有剧烈的变化,直线下降,其他基准分数的下滑则平缓得多。
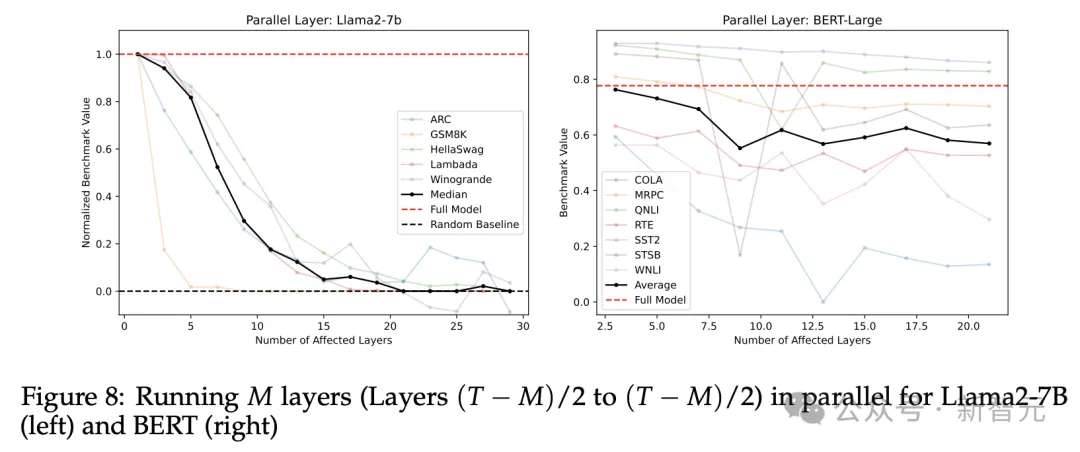
我们暂且可以下这样一个结论:并行运行是可行的,但解决数学问题除外。
要理解这种性能下降,可以用我们的「画家流水线」进行类比:某些中间层只有在看到合适输入时,才能对结果有所贡献,就像一个擅长画车轮的画家,只有在画面上看到汽车车身时,才更有可能画出轮子。
如果是这种情况,将中间层并行运行的过程迭代多次应该会提高性能。
如下图所示,论文将多个并行层的平均输出再作为输入反馈回去,如此进行一定次数的循环。
图9显示了循环3次的结果,与图8中没有循环的方案相比,性能曲线的确相对平缓,尤其是在图右BERT模型未经归一化的分数上更加明显。
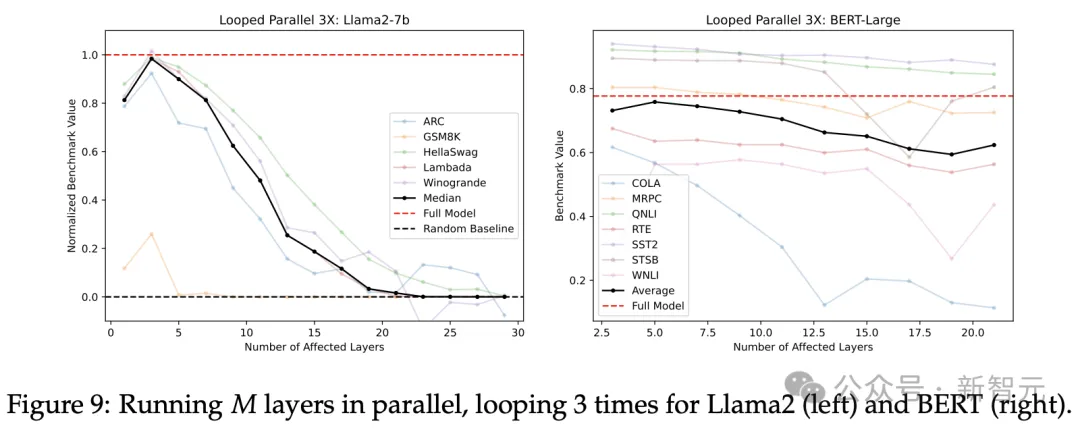
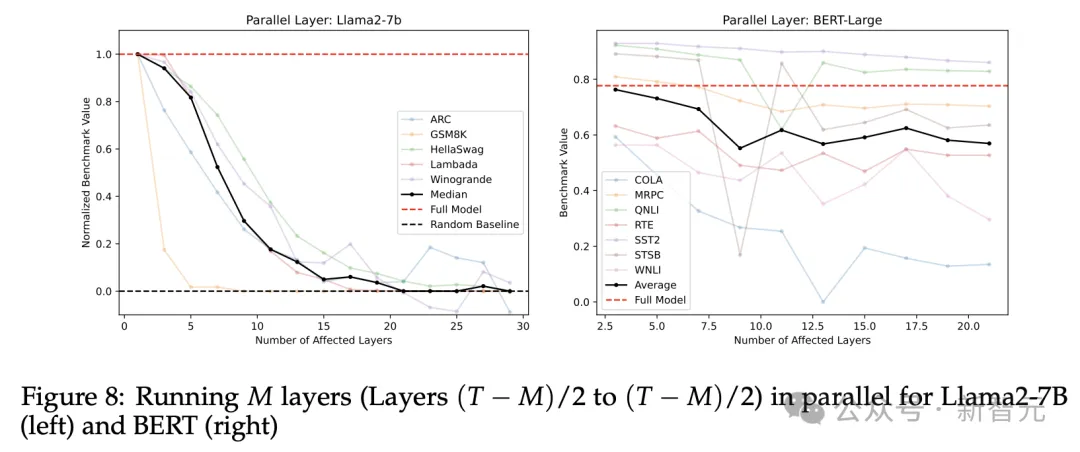
图10更清楚直观地展示了,并行的中间层数和循环次数如何影响性能,其中红框圈出了每列上的最高值。
除了29层和31层(接近Llama 2 7B的总层数32)得出例外的结果,从5层到27层都呈现出一致的趋势:最佳迭代次数大致与并行化层数呈线性比例。
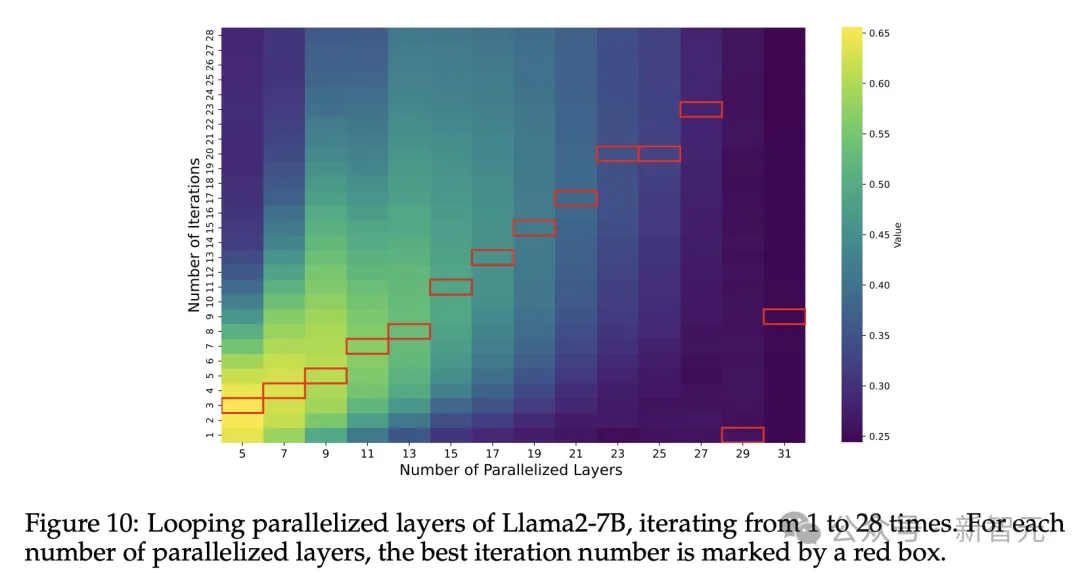
将上述所有实验结果放到同一张图中(图11),我们就能比较不同变体对模型性能的影响程度。
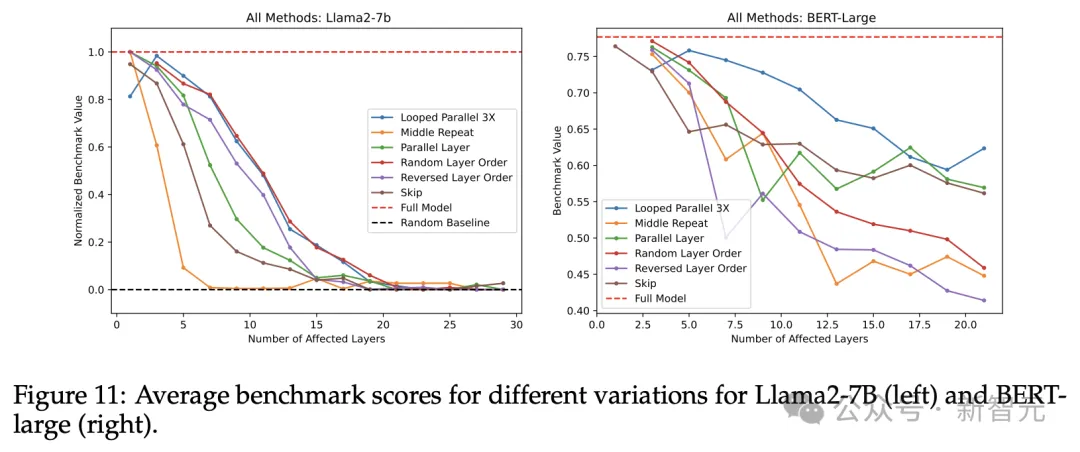
左图(Llama2)取各基准的中值,右图(BERT)取各基准的平均值
「随机化层顺序」和「循环并行」分别在Llama2和BERT-Large上造成了最少的性能下降,「中间重复」方案(用中心层运行多次代替整个中间层)则在两个模型上都造成了最严重的滑坡。
讨论
自从Transformer发布后,大多数工作都在关注架构的修改和优化,以达到性能提升或参数减少。这篇论文则提供了另一种视角,调查了层并行化和重用的影响。
基于「Transformer层即画家」这个类比,我们开头提出的几个问题都通过实验得到了答案,最后得到了3个有趣的发现:
为什么Transformer架构面对各种架构修改时能表现出如此强大的鲁棒性?作者表示将在之后的工作中再深入研究。
一个可能的假设是,训练过程中的残差连接是各层共享相同表征的必要条件。
我们已经知道,残差连接有助于解决梯度消失问题,然而相比没有残差连接的Transformer,加上残差会降低性能。
如果能在没有残差的Transformer上重新运行上述架构的变体,看看是否会破坏完全无残差模型所取得的微薄收益,那将会非常有趣。
对于未来的其他工作,研究人员还计划「解冻」模型,并研究Transformer是否需要(以及需要多长时间)通过微调来适应上述的架构变化。
虽然本文的目的是更好地理解Transformer的中间层,而非引入新模型,但根据实验结果,中间层并行或者干脆跳过都可以用适度的准确性损失换取更低的推理延迟。
作者团队
本文作者分别来自两家AI初创公司:Sakana AI和Emergence AI。
Sakana AI在今年年初刚刚获得3000万美元的种子轮融资,由Lux Capital领投,并得到了硅谷顶级风投公司Khosla Ventures以及Jeaf Dean、Alexandr Wang等大佬的支持。

公司研发的重点是基于自然启发的新型基础模型,创始团队也是星光熠熠,一半成员来自「AI黄埔军校」——谷歌大脑和DeepMind。

相比于关注基础研究的Sakana,Emergence AI更关注应用,专门从事LLM驱动的multi-agent系统研发。
公司联合创始Satya Nitta曾担任IBM研究院「AI解决方案」领域的全球主管,其中的许多研究人员和工程师也同样来自谷歌、Meta、微软、亚马逊和Allen AI等顶尖机构。

Emergence上个月刚刚从Learn Capital获得9720万美元的资金,以及额外的总计超过一亿美元的信贷额度,未来的发展也是前途可期。
文章来源于“新智元”,作者“新智元”



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
