Sebastian Raschka 2026预测:Transformer统治依旧,但扩散模型正悄然崛起
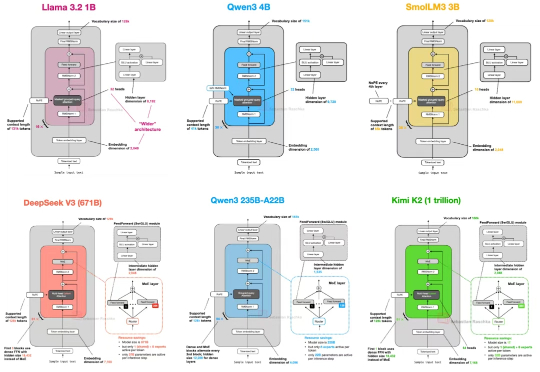
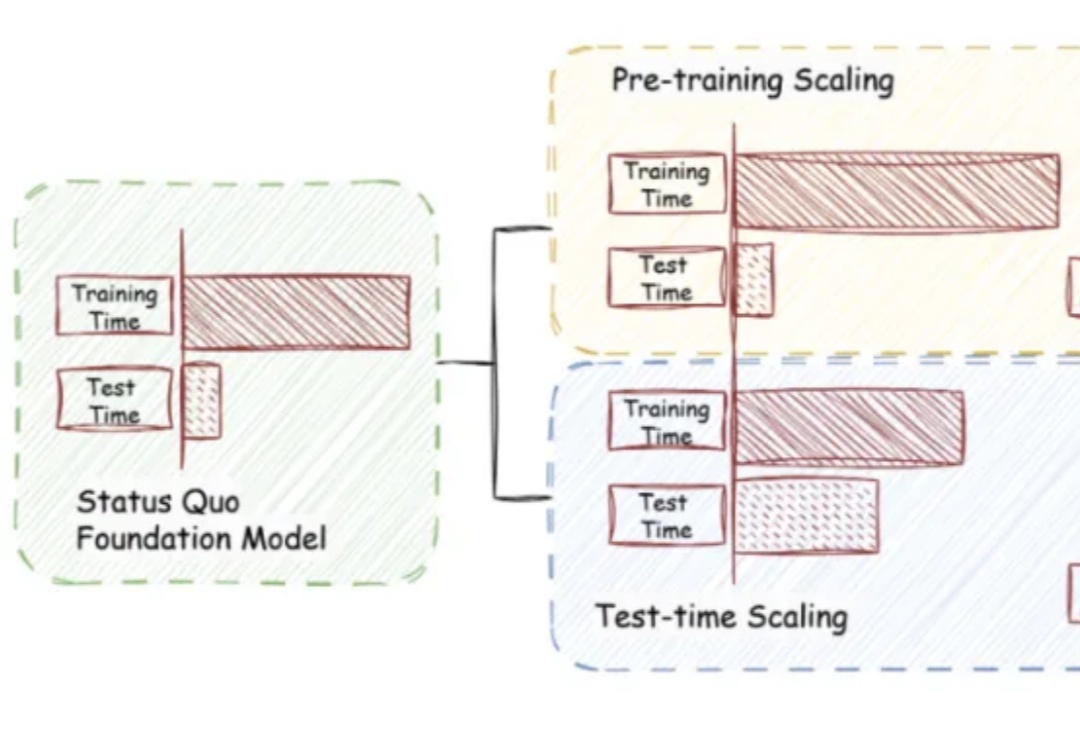
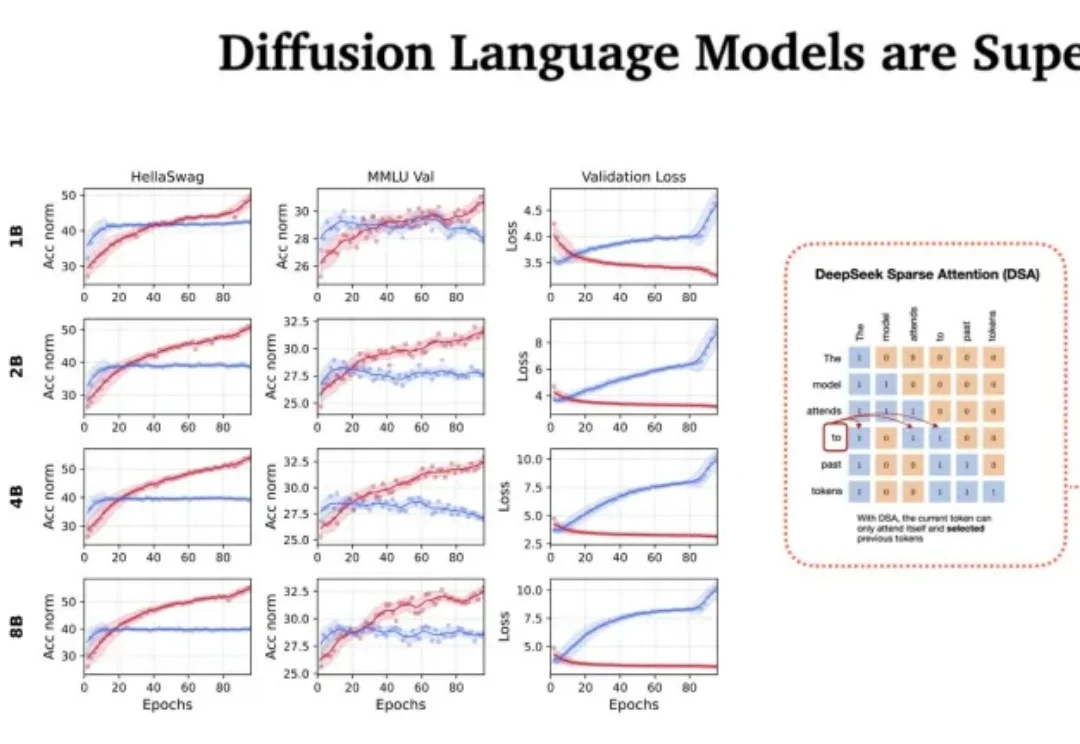
Sebastian Raschka 2026预测:Transformer统治依旧,但扩散模型正悄然崛起站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。
来自主题: AI技术研报
8959 点击 2026-01-14 15:25