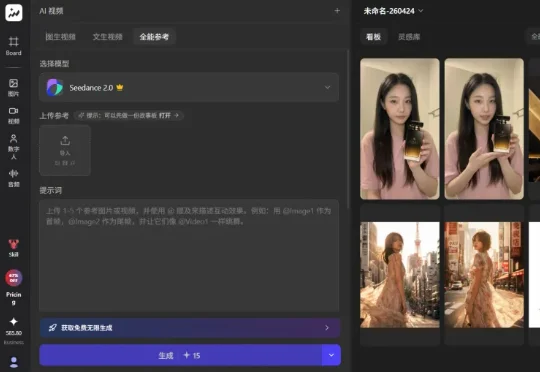
满血版 Seedance 2.0 的成本被 Topview 打下来了!
满血版 Seedance 2.0 的成本被 Topview 打下来了!做过 AI 视频的都懂,除了 Seedance 2.0 本身的高定价,废片所烧掉的 token 算力也是一笔不小的开支。但在 Topview 平台,直接把这笔最大试错成本给重新定义了!热门视频生成模型 Seedance 2.0,加上最新的图片生成模型 Image 2,订阅 Ultra Plan,可不限量使用。
来自主题: AI资讯
7630 点击 2026-04-27 10:00