视频世界模型JEPA‑2与Meta AI的具身智能系统
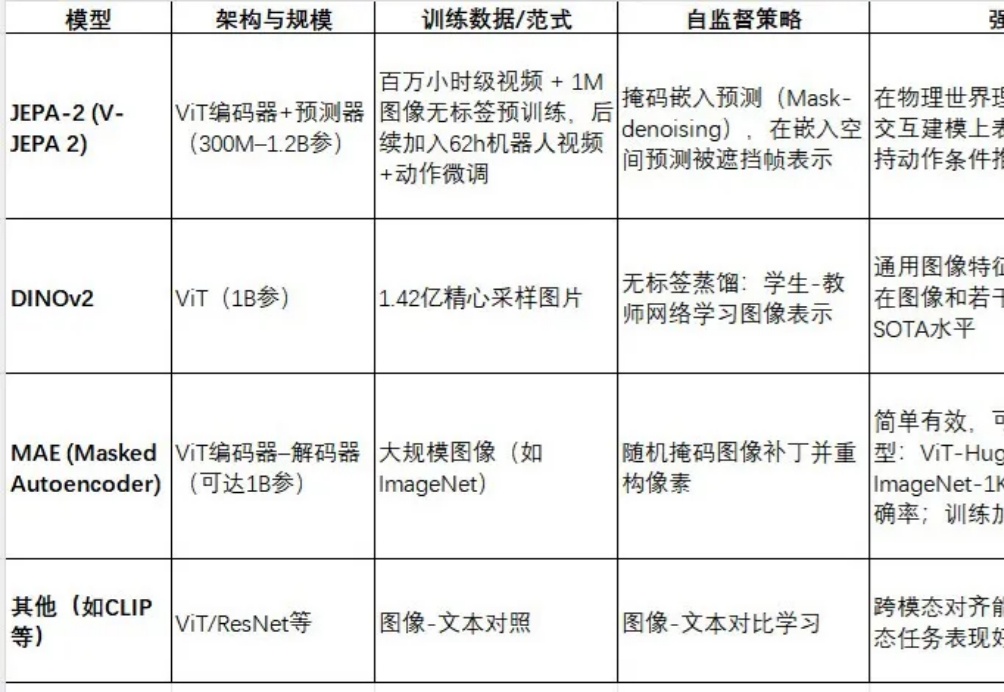
视频世界模型JEPA‑2与Meta AI的具身智能系统JEPA-2(V-JEPA 2)是Meta最新推出的视频世界模型,采用视图嵌入预测(Joint Embedding Predictive Architecture)框架进行自监督预训练。
来自主题: AI资讯
8419 点击 2025-07-01 10:30
 搜索
搜索
JEPA-2(V-JEPA 2)是Meta最新推出的视频世界模型,采用视图嵌入预测(Joint Embedding Predictive Architecture)框架进行自监督预训练。

刚刚,LeCun竟然亲自出镜,重磅讲解了V-JEPA 2!就在外界猜测他已被边缘化之际,这位AI老将用一支视频回应了质疑:要坚定不移做世界模型!这位20年孤勇者押注的方向,是将引领AI的下一个潮流,还是走上了歧路?

就在刚刚,Meta 又有新的动作,推出基于视频训练的世界模型 V-JEPA 2(全称 Video Joint Embedding Predictive Architecture 2)。其能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。
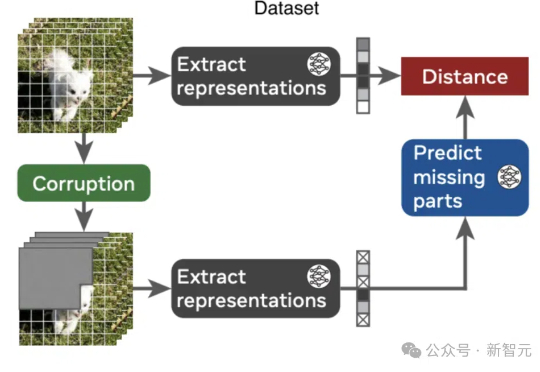
AI如何理解物理世界?视频联合嵌入预测架构V-JEPA带来新突破,无需硬编码核心知识,在自监督预训练中展现出对直观物理的理解,超越了基于像素的预测模型和多模态LLM。

杨立昆:Sora不是世界模型,V-JEPA才是。
短短几天,「世界模型」雏形相继诞生,AGI真的离我们不远了?Sora之后,LeCun首发AI视频预测架构V-JEPA,能够以人类的理解方式看世界。