MiniMax开源首个视觉RL统一框架,闫俊杰领衔!推理感知两手抓,性能横扫MEGA-Bench
MiniMax开源首个视觉RL统一框架,闫俊杰领衔!推理感知两手抓,性能横扫MEGA-Bench仅需一个强化学习(RL)框架,就能实现视觉任务大统一?
来自主题: AI技术研报
8047 点击 2025-05-28 10:41
 搜索
搜索
仅需一个强化学习(RL)框架,就能实现视觉任务大统一?
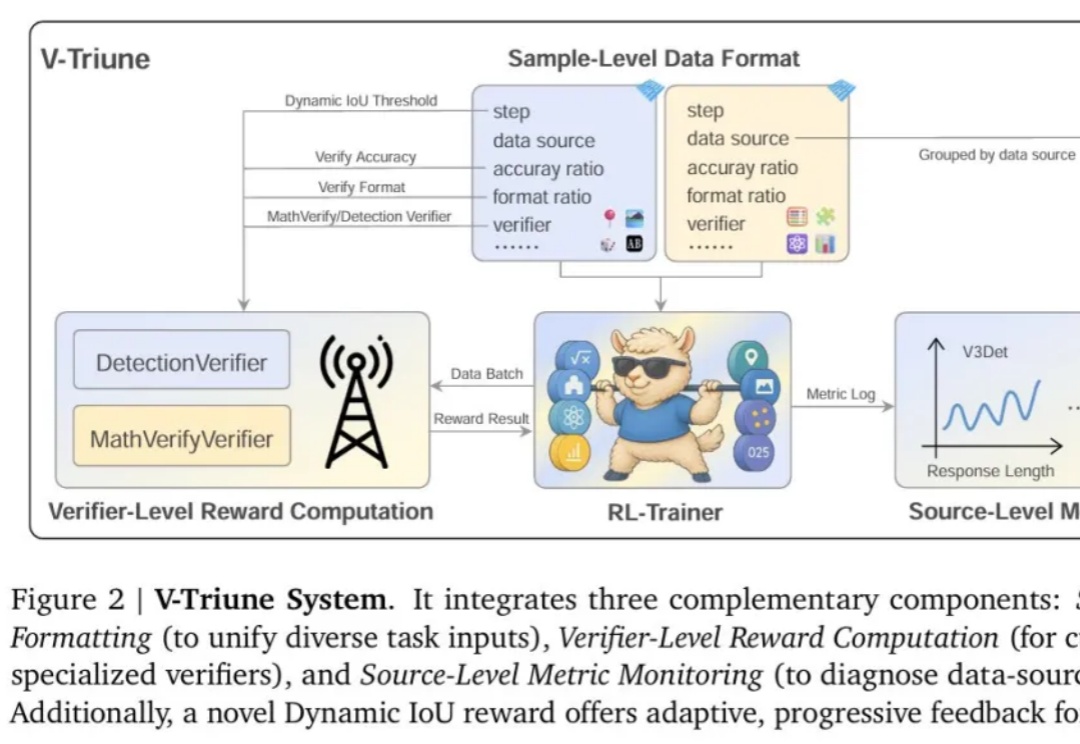
强化学习 (RL) 显著提升了视觉-语言模型 (VLM) 的推理能力。然而,RL 在推理任务之外的应用,尤其是在目标检测 和目标定位等感知密集型任务中的应用,仍有待深入探索。