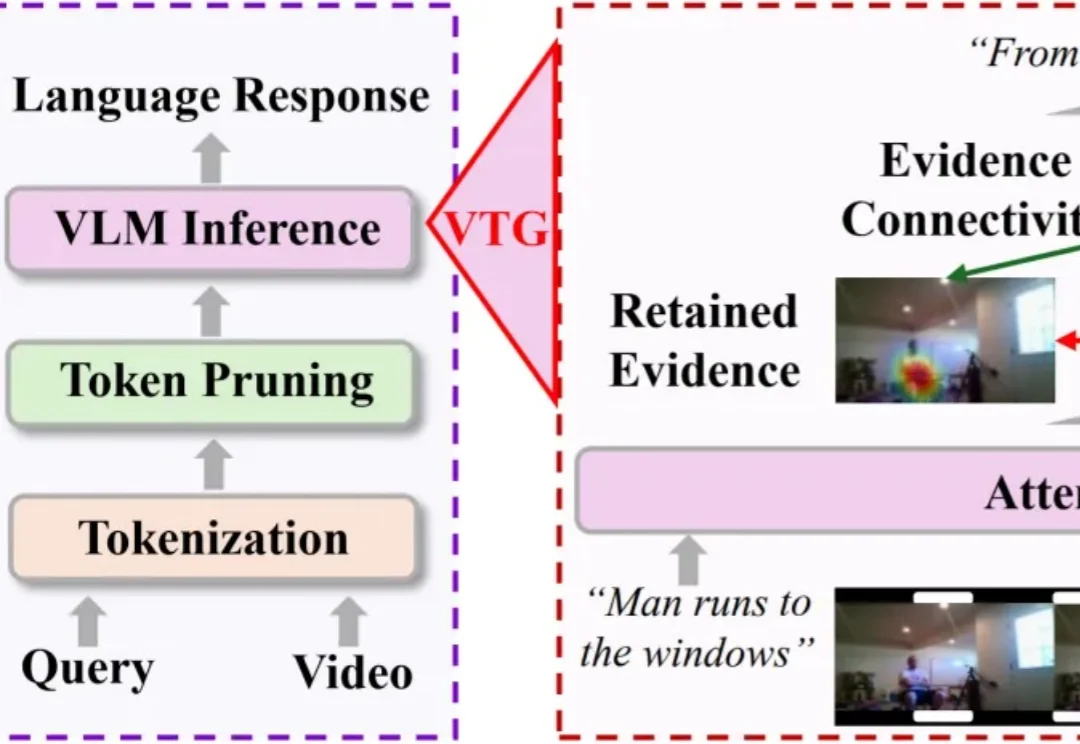
三类视觉Token分配,能直接解决高压缩时序碎片化 | ECCV‘26
三类视觉Token分配,能直接解决高压缩时序碎片化 | ECCV‘26长视频理解,正在成为多模态大模型的重要能力。
来自主题: AI技术研报
6616 点击 2026-07-30 15:57
 搜索
搜索
长视频理解,正在成为多模态大模型的重要能力。

Z Potentials 独家获悉,新加坡国立大学博士,牛津大学博士后研究员林庆泓(Kevin)近期以首席研究员(Principal Researcher)身份加入世界模型公司 Video Rebirth,负责多模态智能体与世界模型相关研究。

2026 年,世界模型已成为人工智能领域最受关注的方向之一。从空间智能到表征预测,从可交互环境到具身智能,越来越多研究与产业团队将下一阶段目标指向「理解世界」。行业竞争的焦点,也已从「是否进入世界模型」,转向「以何种技术路径实现世界模型」。

视频是描述物理世界的重要数据形态,更是人类与物理世界交互的重要载体,视频理解大模型是让 AI 从数字世界走向物理世界最基础、最原生的组成部分。

在今天上午结束的「AI 进入物理世界」京东分论坛上,其对外集中展示了这套布局。除了首次集体亮相的 JoyAI 全系列大模型矩阵,具身数据采集体系、JoyInside 智能硬件和京东云 AI 基础设施也一同亮相,它们连同全链路业务场景组成了京东的物理 AI 闭环。
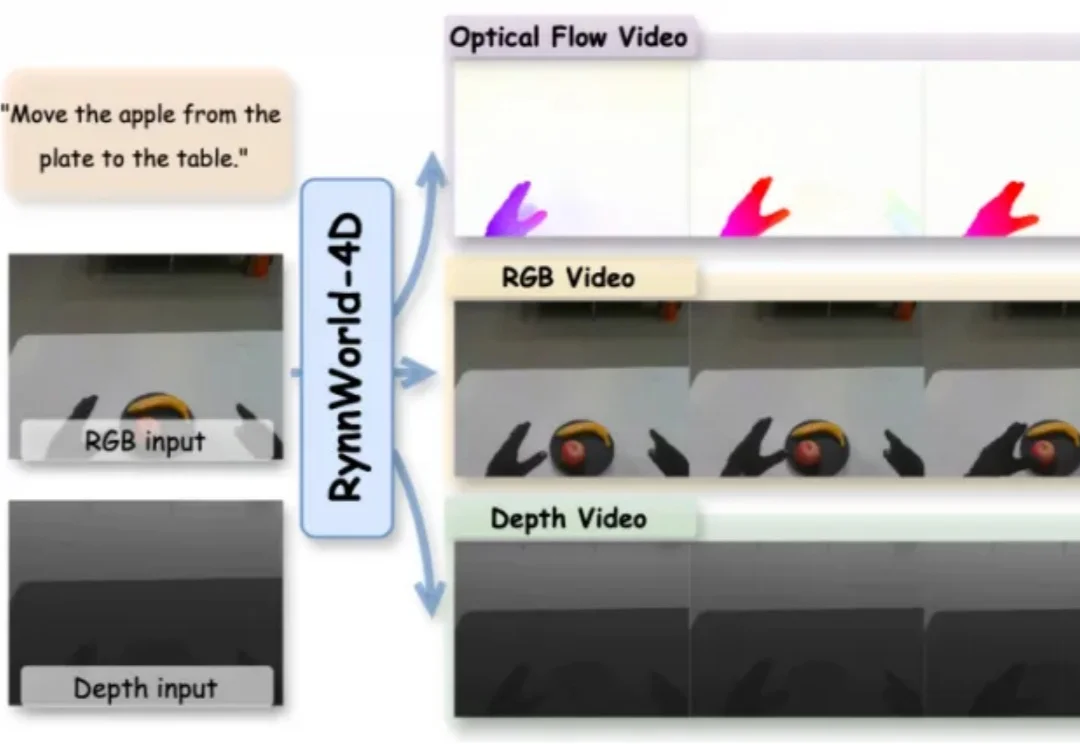
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。

蚂蚁灵波选择了后一条路:开源 LingBot-Video。这是一个面向具身智能的视频生成基座模型,也是一套专为机器人场景设计的 DiT 视频预训练范式。通用视频模型更多学习画面变化、镜头运动和视觉风格;LingBot-Video 则把重点放在动作、任务、交互和物理环境变化上,面向世界预测、动作理解和机器人训练构建视频生成基座。

Meta超级智能实验室(MSL)扔出了首个图像生成模型Muse Image,代号「芒果」(Mango)。这是我们迄今为止最先进的图像生成模型。与Muse Image一同亮相的,还有视频模型Muse Video,目前仍是预览版。

Meta 旗下的超智能实验室 Meta Superintelligence Labs 推出了图像生成模型 Muse Image,并同步预览了 Muse Video。目前,Muse Image 已经接入 Meta AI 应用、网页端以及部分地区的社交平台,Muse Video 也即将向创作者开放。
被CVPR 2026收录!