医学版“谷歌”来了!狂揽全美40%医生,哈佛天才再创业,AI医疗估值超250亿!
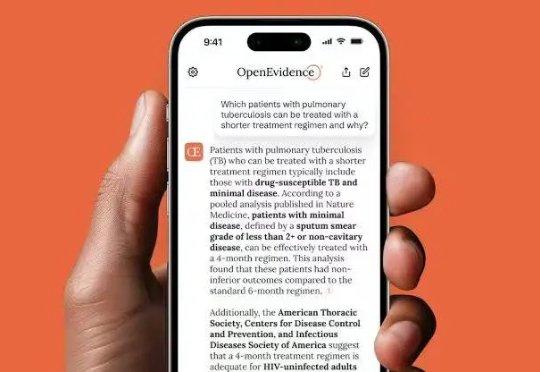
医学版“谷歌”来了!狂揽全美40%医生,哈佛天才再创业,AI医疗估值超250亿!AI医疗的造富神话,又一次上演。近日,AI医疗公司OpenEvidence获得了2.1亿美元的B轮融资,估值飙升至35亿美元(约合人民币251亿元)。
来自主题: AI资讯
9047 点击 2025-07-18 12:53
 搜索
搜索
AI医疗的造富神话,又一次上演。近日,AI医疗公司OpenEvidence获得了2.1亿美元的B轮融资,估值飙升至35亿美元(约合人民币251亿元)。
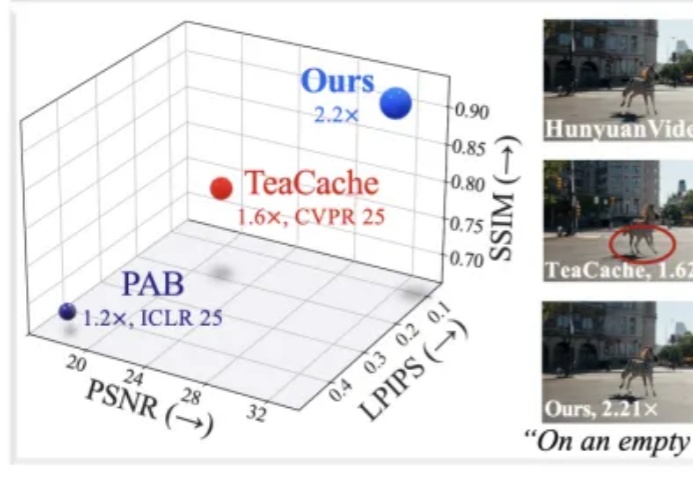
近年来,随着扩散模型(Diffusion Models)和扩散 Transformer(DiT)在视频生成领域的广泛应用,AI 合成视频的质量和连贯性有了飞跃式提升。像 OpenAI Sora、HunyuanVideo、Wan2.1 等大模型,已经能够生成结构清晰、细节丰富且高度连贯的长视频内容,为数字内容创作、虚拟世界和多媒体娱乐带来了巨大变革。
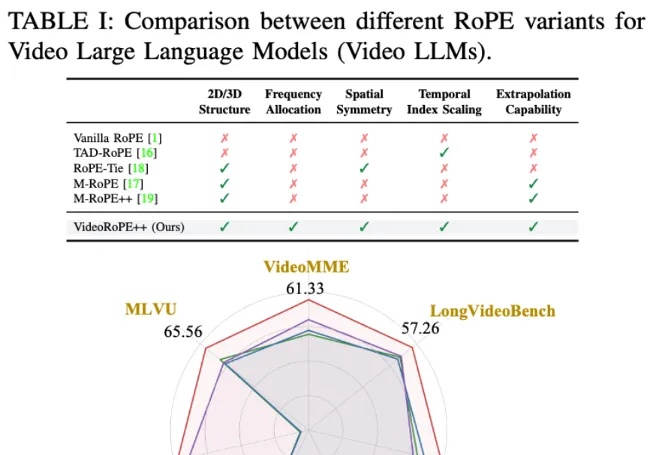
虽然旋转位置编码(RoPE)及其变体因其长上下文处理能力而被广泛采用,但将一维 RoPE 扩展到具有复杂时空结构的视频领域仍然是一个悬而未决的挑战。
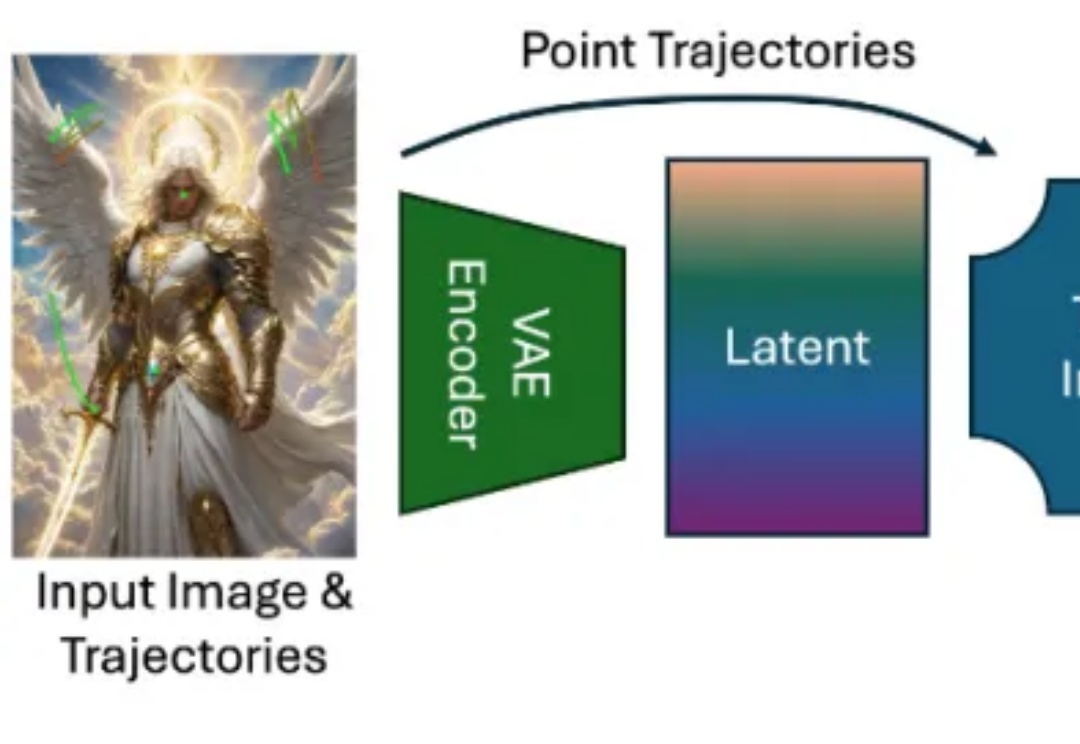
近年来,随着扩散模型(Diffusion Models)、Transformer 架构与高性能视觉理解模型的蓬勃发展,视频生成任务取得了令人瞩目的进展。从静态图像生成视频的任务(Image-to-Video generation)尤其受到关注,其关键优势在于:能够以最小的信息输入生成具有丰富时间连续性与空间一致性的动态内容。

为什么AI生成的视频总是模糊卡顿?为什么细节纹理经不起放大?为什么动作描述总与画面错位?
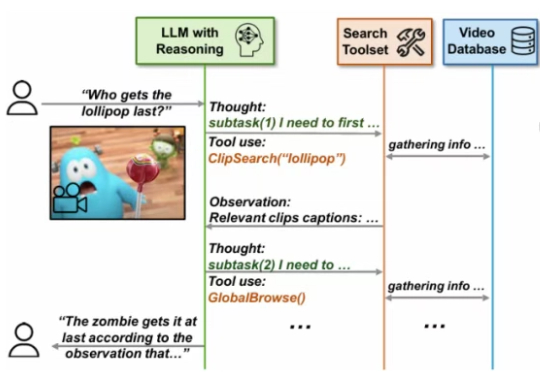
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,但它们在处理信息密集的数小时长视频时仍显示出局限性。

扩散模型在视频合成任务中取得了显著成果,但其依赖迭代去噪过程,带来了巨大的计算开销。尽管一致性模型(Consistency Models)在加速扩散模型方面取得了重要进展,直接将其应用于视频扩散模型却常常导致时序一致性和外观细节的明显退化。

视频生成技术正以前所未有的速度革新着当前的视觉内容创作方式,从电影制作到广告设计,从虚拟现实到社交媒体,高质量且符合人类期望的视频生成模型正变得越来越重要。

就在刚刚,Meta 又有新的动作,推出基于视频训练的世界模型 V-JEPA 2(全称 Video Joint Embedding Predictive Architecture 2)。其能够实现最先进的环境理解与预测能力,并在新环境中完成零样本规划与机器人控制。
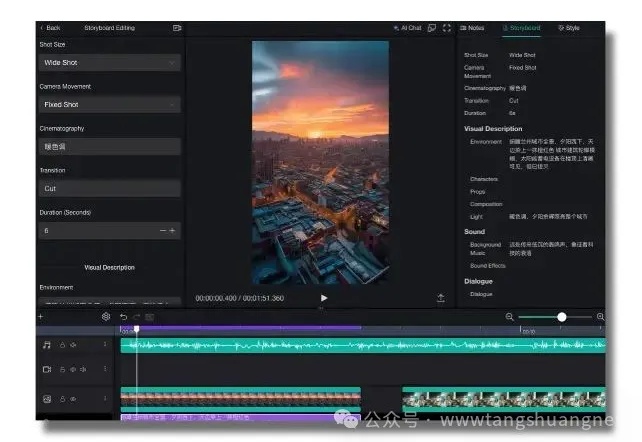
大家好,这两个月我完成了一款产品——Videa。虽然过去一年,我做了很多东西,但是部分是套壳,部分是把别人的想法做出来,真正我一直想做的,其实是一款借助AI创作短视频的产品。现在,我把它做出来了。