
Claude「永久大脑」,真的来了!
Claude「永久大脑」,真的来了!刚刚,Claude「双记忆系统」首次爆出!全新「文件记忆」让AI一边聊天,一边自动做笔记。还有杀手级Conway Agent浮出水面,7x24小时永不下线。
来自主题: AI技术研报
7656 点击 2026-05-25 15:13
 搜索
搜索
刚刚,Claude「双记忆系统」首次爆出!全新「文件记忆」让AI一边聊天,一边自动做笔记。还有杀手级Conway Agent浮出水面,7x24小时永不下线。

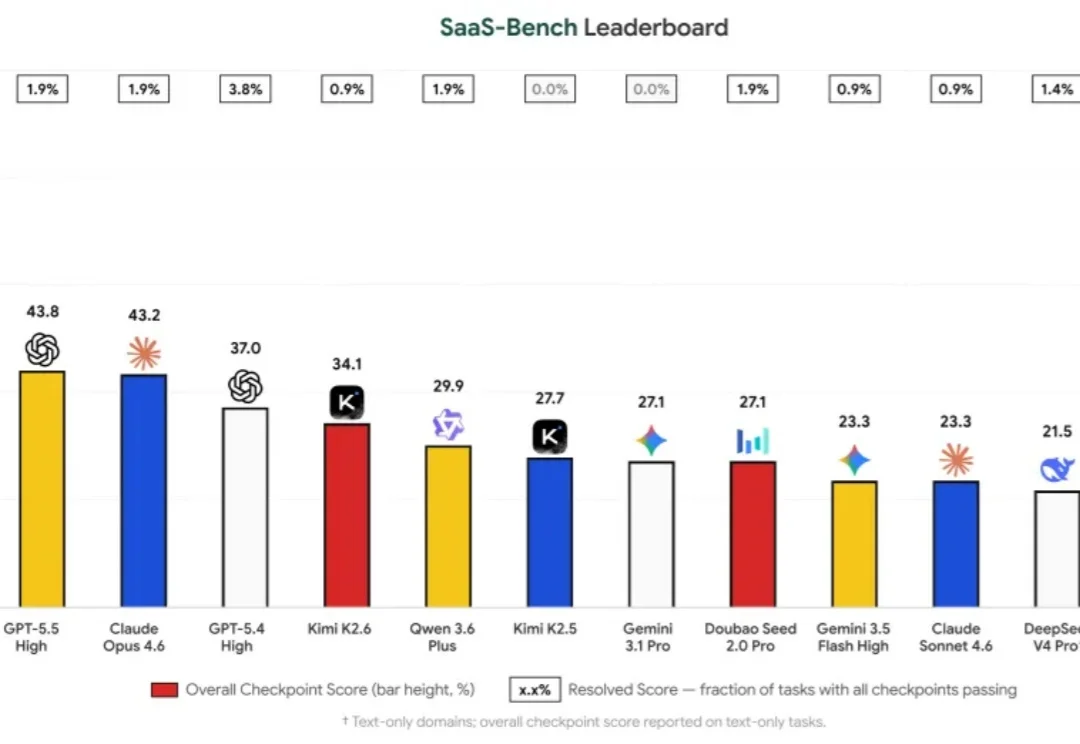
没有信息泄漏的专业术数题库面前,Claude、GPT等主流模型集体「翻车」。但一个叫Tianfu Agent的系统,却一举将准确率提升至50%,逼近本届术数大赛人类Top20选手的53.5%平均水平。
想象一个真实的工作日:项目经理要更新项目状态,财务人员要整理客户账单,医疗管理员要核对预约和保险信息。

Claude Code 的 settings.json 里有 125 个配置键。官方文档只讲了大约 40 个。

旧金山开发者Affaan Mustafa把Claude Code打磨成38个专业智能体、156项技能的超级系统,开源后短短时间冲上GitHub 15万星!

“Claude 可能比你更擅长从你这里提取出你想要和需要的东西,而不是由你向 Claude 详细指定。”

几乎同一天,Anthropic三大超级AI提前曝光!Claude Opus 4.8突袭谷歌后台,Sonnet 4.8跳级4.7。曾经叫嚣着「太危险不公开」的Mythos 1,也现身了。

Anthropic实锤:Claude裸跑模型,9美元全废;但是套上Harness花200美元效果直接起飞。AI效果不好?别再纠结换模型了!OpenAI和Anthropic都在用的Harness工程,一文讲透。
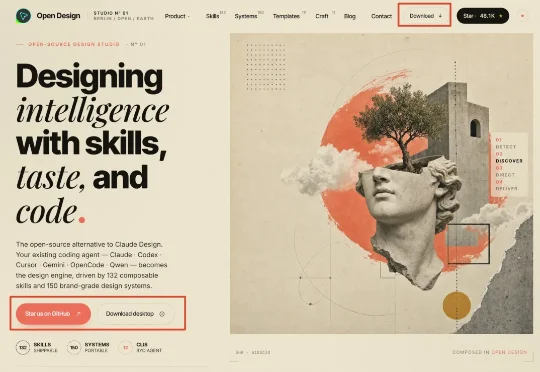
最近有一个工具让我有点上头,而且越用越停不下来,越用越觉得这个工具太牛逼了,必须写一篇详细教程安利给大家。 它叫 Open Design。 如果你用过 Claude Design,你大概知道我在说什么。
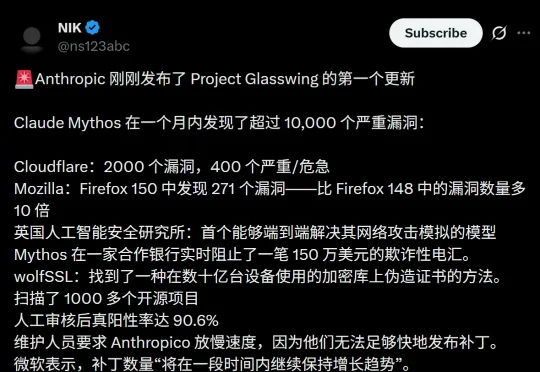
A厂的玻璃翼计划首战告捷,Mythos 30天内就挖出1万个致命漏洞,甚至拦截了150万美元电诈!面对雪片式的报告,人类程序员也崩溃求饶了:「求别挖了,根本修不完啊!」