
开源一个 Skill,让 AI 接管你屏幕边那张便签纸
开源一个 Skill,让 AI 接管你屏幕边那张便签纸上个月我做了 M5 Paper Buddy,把一块墨水屏接到 Claude Code 上,监控 AI 在干什么、需要审批什么。当时挺兴奋的,物理按键审批操作那个仪式感很好。但用了几周之后我发现,它放在桌上的时间,远比我看它的时间长。
来自主题: AI资讯
10147 点击 2026-05-23 13:48
 搜索
搜索
上个月我做了 M5 Paper Buddy,把一块墨水屏接到 Claude Code 上,监控 AI 在干什么、需要审批什么。当时挺兴奋的,物理按键审批操作那个仪式感很好。但用了几周之后我发现,它放在桌上的时间,远比我看它的时间长。

他身前是13英寸笔记本,眼前铺开的则是174英寸的超宽屏幕。这块屏幕来自这幅XR智能眼镜,屏幕上同时铺着三个窗口:左边是Claude Code,代码正一行行往外吐;中间是编辑器,光标在等他的下一次指令;右边是飞书,同事刚发来一条消息。而这并非幻想画面。实际上,这是使用VITURE眼镜进行vibe coding的新潮流。

Claude 100%编码Claude,这在圈内早已不是秘密。但Claude「自我造物」全过程,始终是Anthropic严防死守的核心机密。就在今天,Anthropic产品负责人Alex Albert在一场35分钟的访谈中,首次毫无保留地曝光了全细节!
微软工程师们,天塌了!昨天, 微软工程师们还在用Anthropic的Claude Code狂飙代码、改代码库、跑代理,今天就被一纸通知:6月底前必须全部下线,强制转向自家GitHub Copilot CLI!这不是小打小闹,是微软多个部门集体断供Claude Code。

AI办公彻底变天了!阿里QoderWork重磅发布全球首个AI Native自定义工作台,推出设计、PPT、写作三大领域模式。AI办公正式从「对话驱动」走向「领域驱动」。

DeepSeek Code要来了。

教宗利奥十四世将于 5 月 26 日发布任期首份通谕,主题直指 AI,Anthropic 联合创始人、Claude 缔造者 Chris Olah 受邀同台。梵蒂冈同步成立 AI 委员会。一个两千年的古老机构,正试图用道德权威填补 AI 治理的真空——它覆盖的人口,比任何一部 AI 法案的管辖范围都大。
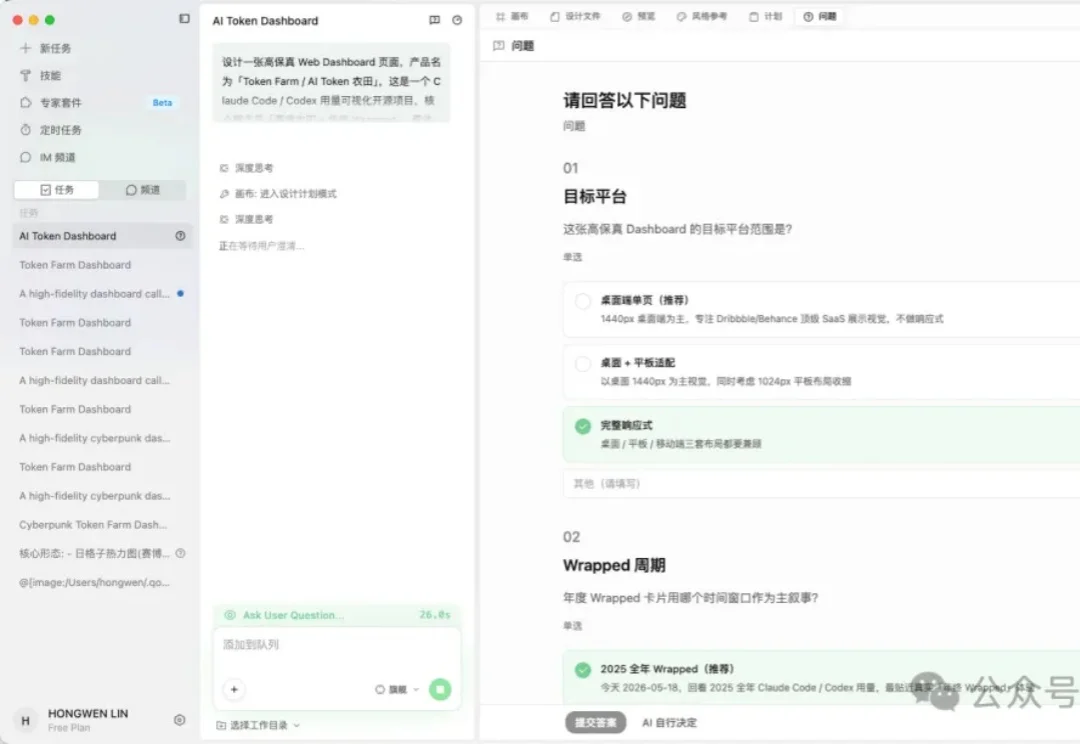
阿里的 QoderWork 最新上线了一个设计工作台(Design Desk),定位是用自然语言做出可交付的专业设计,从想法到工程级产物,中间不需要 Figma。
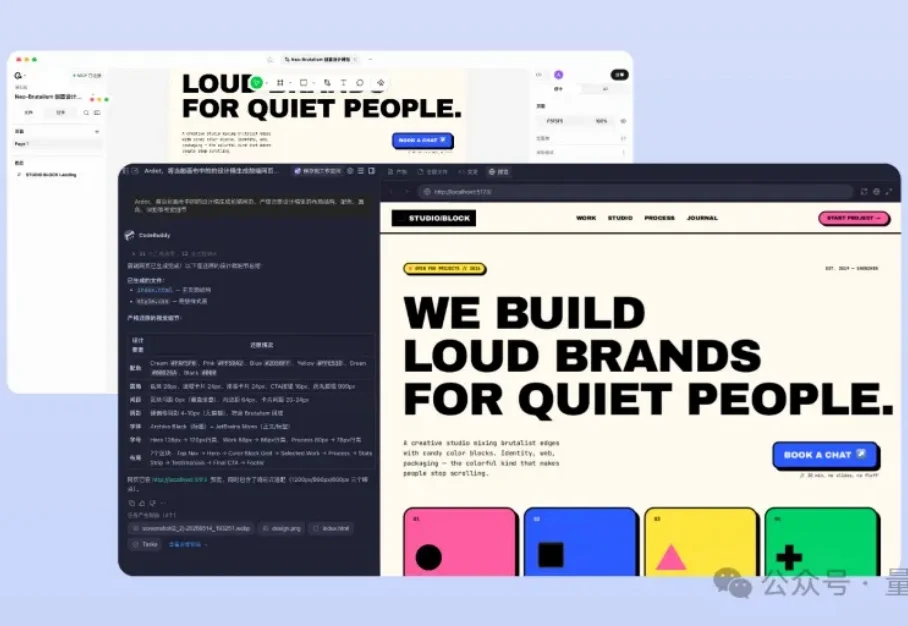
Claude Design前脚刚把设计圈炸完,腾讯又公测了一个Ardot—— AI设计智能体平台,一句话生成可编辑UI设计稿、Figma文件零成本导入、一键转代码直通IDE、多人在线评审……

游戏规则要被改写了!Hermes Agent一键把模型订阅变成标准API,零成本驱动全套工具链。Grok同步杀入Agent生态。