
DeepSeek V4-Flash登顶OpenRouter全球调用榜
DeepSeek V4-Flash登顶OpenRouter全球调用榜最近,DeepSeek又刷屏了!
来自主题: AI资讯
6685 点击 2026-05-27 09:14
 搜索
搜索
最近,DeepSeek又刷屏了!

4个月烧光全年AI预算,天价Token账单正在屠杀硅谷!今天,高性能Agent模型SkyClaw-v1.0出世,性能直逼Opus 4.6、DeepSeek V4 Pro,百万上下文性价比拉满。
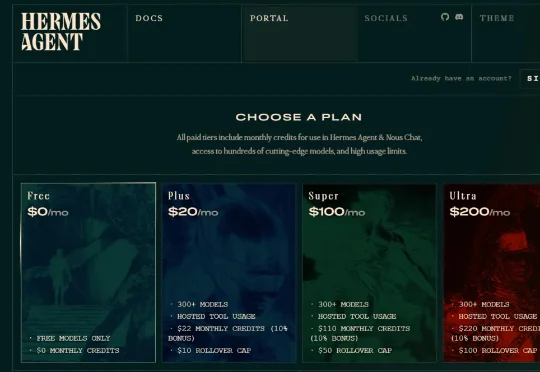
DeepSeek这半年生态铺得很快。现在好几个渠道可以免费或极低成本用上DeepSeek模型,从V4 Flash到V4 Pro都有。整理一下最实用的三条路。

DeepSeek 之于大模型,就像蜜雪冰城之于奶茶。你不必纠结性价比,因为它的本事你挑不出毛病,你的钱包它也从不为难。

最近人人都在聊 DeepSeek 的融资,这个等最终落定后我们再说。今天先说 Kimi 。

今年以来,在线策略蒸馏 OPD(On-Policy Distillation)已经逐渐成为大厂 LLM 后训练中的重要组件,例如 DeepSeek-V4,GLM5 就使用了多教师 OPD 来整合不同领域专家模型的能力,相比混合奖励强化学习收敛更快、效果更好。

前两天,AI 圈子里出了个瓜,关于 DeepSeek TUI 创始人的,各个社媒群里几乎都刷屏了。但我发现一个问题 ——大家都只盯着一张微信群聊的截图在讨论,几乎没人把整件事的来龙去脉理一遍。
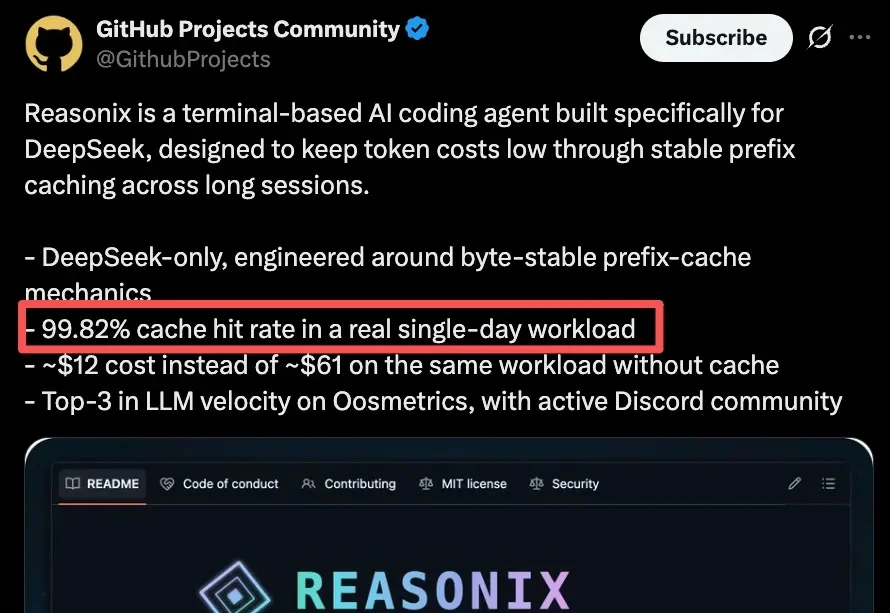
我悟了,DeepSeek V4系列发布1个月,价格屠夫的本色这才刚刚发力啊!

DeepSeek正用开源、降价和底层架构创新,重画AI硬件生态的成本曲线,把目标指向十万亿美元产业与AGI的星辰大海。
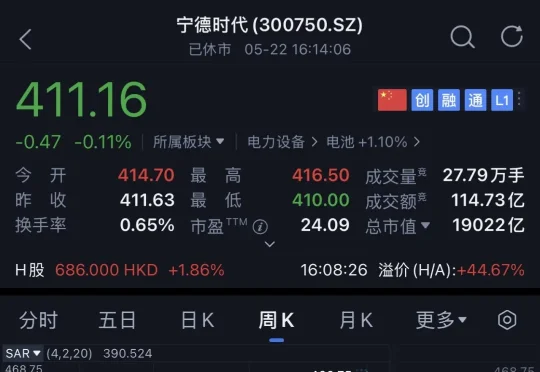
据The Information昨晚报道,全球动力电池市场龙头宁德时代拟入局DeepSeek首轮融资。这是宁德时代在AI领域被曝出的最新布局。就在刚刚过去的一个半月内,宁德时代官宣斥资105亿元加码AI算电协同赛道,电力、算力、储能、AI一体化全产业链布局全面落地。