DeepSeek陈德里AI论文第二弹:从6分到8分,DeliAutoResearch SKILL又进化了
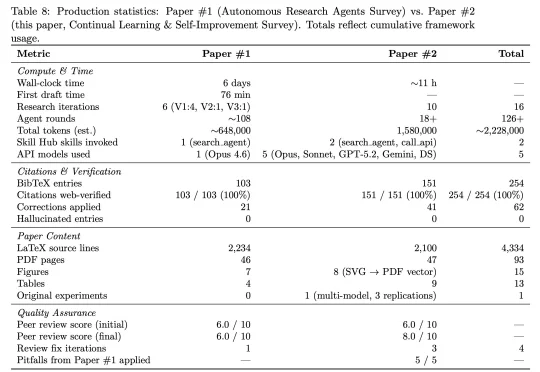
DeepSeek陈德里AI论文第二弹:从6分到8分,DeliAutoResearch SKILL又进化了DeepSeek 研究员陈德里(Deli Chen)和 AI 合作的第二篇论文来了!论文地址:https://victorchen96.github.io/continual_learning_survey.pdf这篇论文聚焦 continual learning(持续学习) 与 self-iteration(自我迭代)。在陈德里看来,这是 AI 迈向 AGI 过程中极为关键的一步。
来自主题: AI技术研报
10188 点击 2026-05-30 22:40