# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
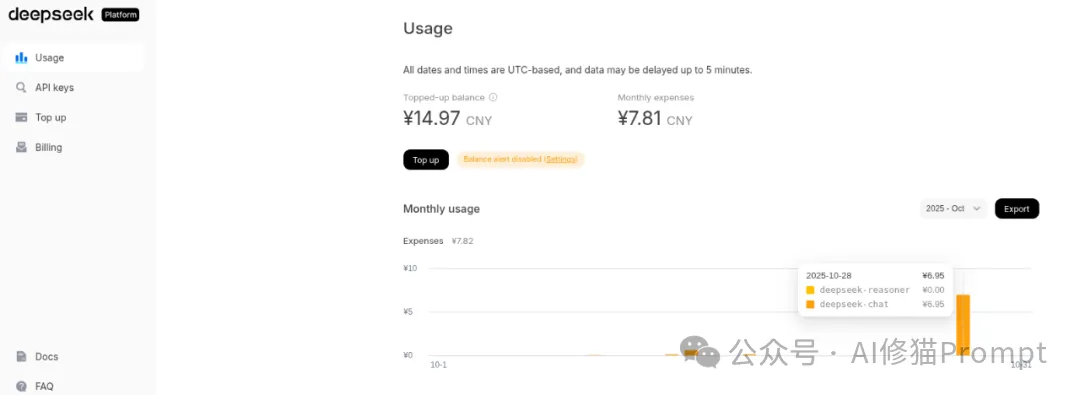
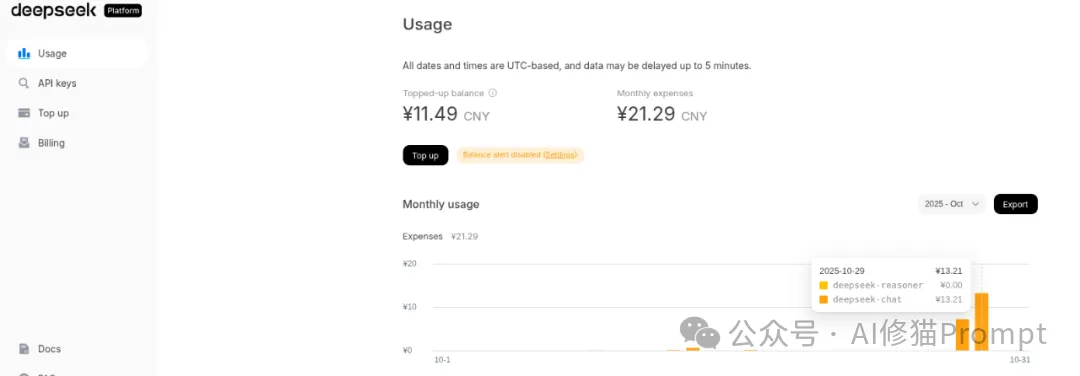
读者,您好!今天想跟您聊一个硬核又极具启发性的项目——HGM(Huxley-Gödel Machine)。我刚刚一起花了几个小时,从环境配置的坑,一路“打怪升级”到让它最终跑完,相信您可能已经从别的公众号上看到了这篇文章。用DeepSeek-chat跑了21块钱的Token,我想结合在这3轮经历和我对论文的理解,为您深入剖析一下,这个能“自我进化”的编码智能体,到底是怎么回事,以及如果您想在自己的项目里借鉴它的思想,需要注意些什么。先说下结论:本次运行完整复现了 HGM 算法的一次核心迭代(大概消耗300多万Token,7.2元左右):通过 Expand 阶段创造出新的、更强的代理,再通过 Sample 阶段验证了有效性。这应该是一套可用的AI自指进化程序。

论文标题:Huxley-Gödel Machine: Human-Level Coding Agent Development by an Approximation of the Optimal Self-Improving Machine
论文链接:https://arxiv.org/abs/2510.21614 [1]
Github 链接:https://github.com/metauto-ai/HGM [2]

在深入HGM之前,我们得先聊聊它想解决的那个核心问题。研究者在Abstract中是这么说的,他们发现代理的自我改进潜力(元生产力)与其编码基准性能之间存在不匹配,即元生产力-性能不匹配。受赫胥黎进化概念的启发,于是提出了一个指标( CMP ),该指标汇总了代理后代的基准性能,作为其自我改进潜力的指标。研究者引入了赫胥黎-哥德尔机(HGM),它通过估计 CMP 并以此为指导来搜索自我修改树。最后,同样重要的是,HGM 展现出对其他编码数据集和大型语言模型的强大迁移能力。在 SWE-bench Verified 上使用 GPT-5-mini 进行 HGM 优化,并在 SWE-bench Lite 上使用 GPT-5 进行评估的代理达到了人类水平的性能,与官方测试的人工工程编码代理的最佳结果相当。基于此,我决定用DeepSeek的模型试一试。
研究者将其定义为“元生产力-性能不匹配”(Metaproductivity-Performance Mismatch),这个词听起来很学术,但说白了就是一件事:一个在当前测试里得分最高的“学霸”Agent,不一定能培养出更牛的“后代”。
您看,这其实很反直觉,我们通常会认为,强者恒强,选择当前最好的那个,让它去创造下一代,结果肯定不会差,对吧?
但研究者发现,现实并非如此。一个Agent可能只是因为它的代码结构恰好“过拟合”了当前的测试任务,拿到了高分,但它的结构可能已经非常僵化,失去了进一步优化的空间,就像一个只会刷题的考试机器,你让他去做开创性的研究,他就懵了。相反,另一个Agent可能当前分数平平,但它的代码设计得非常优雅、有扩展性,蕴含着巨大的“进化潜力”,经过几轮迭代,它的后代可能会产生惊人的突破。只看眼前分数的“贪心”策略,很容易就会错过这种真正有潜力的“潜力股”,最终整个进化过程会提前陷入停滞。
那么,HGM是怎么解决这个问题的呢?我觉得它的思路真的挺巧妙的,它引入了一个生物学概念——“分支”(Clade),也就是我们常说的“家族谱系”。HGM的核心思想是,不要只盯着单个Agent的个人分数,而是要考察它整个“家族”(它和它所有的后代)的整体表现。
HGM引入了一个全新的度量标准,叫做“谱系元生产力”(Clade Metaproductivity, CMP)。这个标准不再孤立地评估某个AI智能体a的表现,而是考察由它衍生出的所有后代(它的“孩子”、“孙子”……)的整体性能。换句话说,它评估的是一个“家族”的整体兴旺程度,一个祖先节点(agent)的价值,体现在它能否孕育出一代代更强的后代。一个祖先自己可能不是最强的,但如果它的“设计哲学”(比如它的代码结构、它生成的提示模板)能够启发后代不断突破,那么它就具有极高的CMP。
您也可以把这个过程想象成一个育种专家。他手里有好几个品系的赛马,他不会只因为一匹马这次比赛跑了第一,就认定它是最好的“种马”。他会观察这匹马的所有后代,看看它的孩子们是不是普遍都跑得很快。如果答案是肯定的,哪怕这匹“种马”自己偶尔失手,专家也知道它的“基因”是优秀的,值得继续投入资源。HGM做的就是类似的事情,它通过统计整个“家族”在无数次测试中的成功与失败,来估算出一个更接近长期潜力的CMP值。
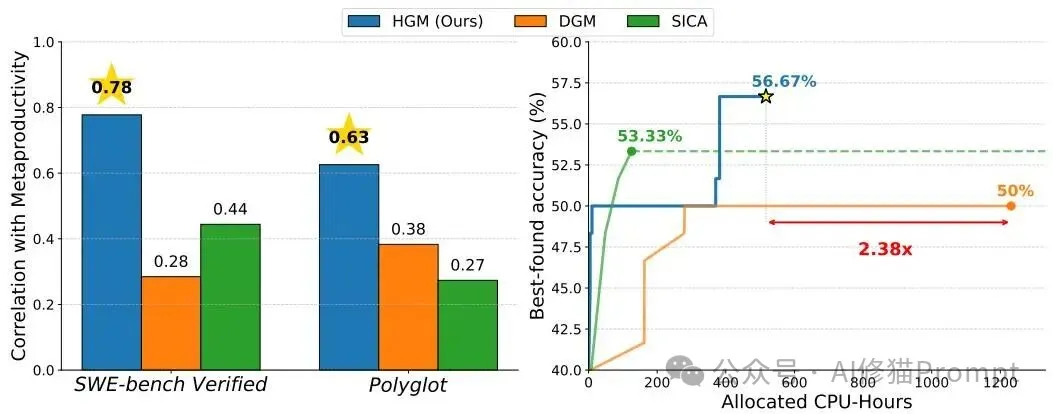
论文中的核心图(Figure 1):左图显示了其他方法的指标(横轴)与长期潜力(纵轴)的弱相关性,而HGM的CMP指标(最右侧)与长期潜力的相关性要强得多。右图则直观展示了在SWE-bench上,HGM(蓝色)用更少的时间达到了比DGM(橙色)高得多的性能。
更有意思的是,项目作者在理论上证明了,如果你能拥有一个完美的“CMP预言机”,知道每个改动的真实长期潜力,那你就能实现理论上最优的自我改进机器——也就是Jürgen Schmidhuber教授多年前提出的那个著名的“哥德尔机”。所以,HGM本质上就是用“家族表现统计”这个务实的工程方法,来近似模拟那个遥不可及的理论最优,让“代码自己改自己”自指这件事,从一个哲学思辨变成了可以实际运行的系统。

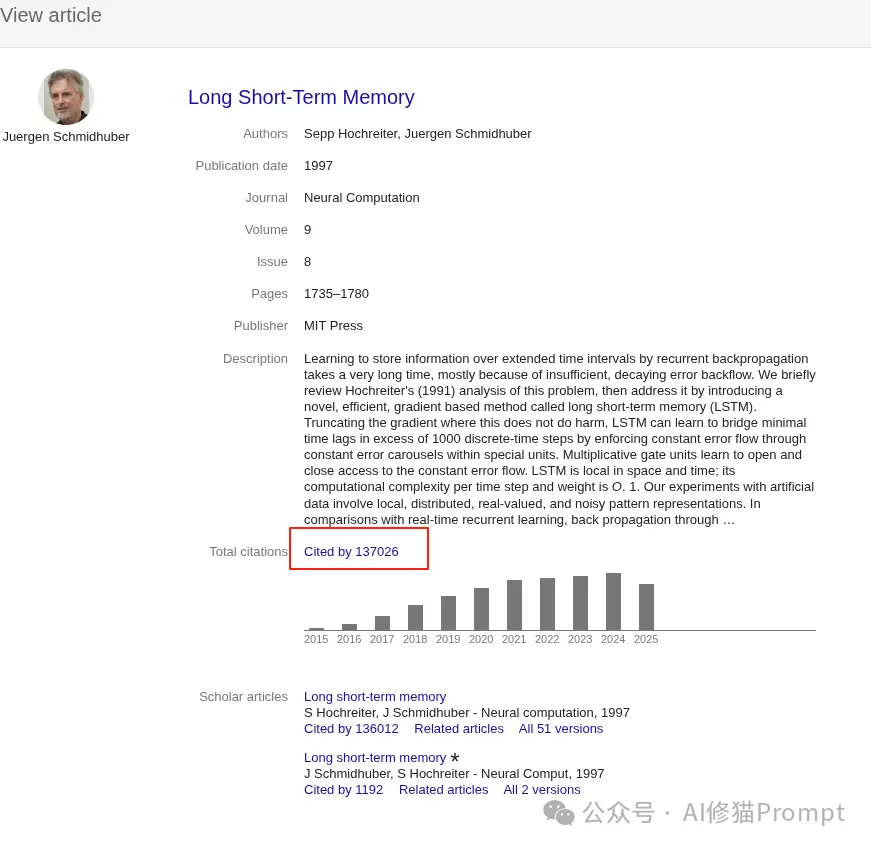
说到哥德尔机,就不能不提它的提出者——Jürgen Schmidhuber教授(上图),这在AI领域可是一位“扫地僧”级别的人物。您可能不一定熟悉他的名字,但您一定知道甚至用过他的成果(引用13万):他正是大名鼎鼎的LSTM(长短期记忆网络)的核心发明人,可以说,没有LSTM,就没有后来深度学习在自然语言处理领域的狂飙突进。一位在工程实践上做出如此巨大贡献的科学家,同时又在思考像哥德尔机这样极具哲学思辨色彩的理论问题,这本身就说明了这个科学哲学理论方向的深远价值。
当然,一个好的理论最终还是要靠数据说话。HGM的“家族评估”思想听起来很美,但它真的比那些“贪心”的短视方法更好吗?论文中的实验结果给出了相当有冲击力的答案。
项目作者将HGM与另外两种主流的自我改进方法(DGM和SICA)进行了正面比较。例如,在Polyglot编程任务上,从同一个初始Agent出发,HGM最终培育出的“最佳后代”准确率达到了30.5%,比初始Agent提升了10.2个百分点。相比之下,DGM只提升了6.8个百分点,更重要的是,HGM达到这个成果只花费了347个CPU小时,而DGM则花费了惊人的2385个小时,效率高下立判。
更令人瞩目的是,当项目作者将在SWE-bench(一个更复杂的真实世界软件问题修复平台)上用GPT-5-mini优化出的最佳Agent,拿去评估更强的GPT-5模型时,它的性能达到了57%。这是什么概念呢?这意味着由机器自己进化出的Agent,在解决真实世界软件问题的能力上,已经可以和顶尖人类工程师精心设计的、在排行榜上名列前茅的Agent相媲美了。这充分证明了HGM发现的设计原则具有很强的通用性和扩展性,而不是简单地过拟合到某个特定的模型或数据集上。关于歌德尔机方向之前我也介绍过:

!离AGI更近了!!0.31元运行谷歌的AlphaEvolve和UBC的DGM「达尔文-哥德尔机」?
在我们刚才的探索中,已经接触了项目的几个关键部分。现在我们把它们串起来看,就能形成一幅完整的地图:
hgm.py:这是整个项目的中枢神经系统。它里面包含了那个核心的进化循环逻辑:是该“扩张”还是该“评估”?选哪个Agent去扩张?选哪个Agent去评估?所有的决策都在这里发生。我们之前遇到的argmax错误,就是因为这个大脑在决策时,发现手头一个能打的“候选人”都没有。
llm.py:这是系统的“嘴巴”和“耳朵”。它负责与外部的大语言模型(比如我们用的DeepSeek)进行通信。当hgm.py决定要进行一次“自我修改”时,它会通过llm.py把需求(比如“请优化这段代码的效率”)发给LLM,并接收LLM返回的新代码。
polyglot/ 和 swe_bench/:这两个目录可以看作是Agent们的“健身房”和“考场”。里面包含了大量的编程练习题和真实的软件工程问题。HGM通过让Agent在这些环境中解决实际问题,来评估它们的能力,并为它们的“家族”积累CMP统计数据。
run.sh:这个脚本,说实话,有点“误导性”。它看起来是官方推荐的运行方式,但实际上它只是简单地激活一个名为agent的conda环境,然后就直接运行hgm.py了。在之前的调试中,踩了不少坑,它不仅环境名写死了,而且掩盖了hgm.py背后丰富的可配置参数,导致我们一开始无法清晰地观察系统的单次运行。
好了,理论和结构都聊完了,现在我们回到实践。结合这次“浴血奋战”的经历,我为您总结了一套清晰、可复现的单次运行流程,并指出了那些我们一起踩过的“坑”。
环境搭建:这一步我们已经完成了。关键就是用conda create -n hgm python=3.11创建一个包含Python解释器的环境,然后用pip install -r requirements.txt安装依赖。我之前遇到的externally-managed-environment错误,就是因为一开始创建的conda环境是空的,我系统里装的是3.13,论文github上conda并没有指出用哪个版本的python,导致pip错用了系统环境。
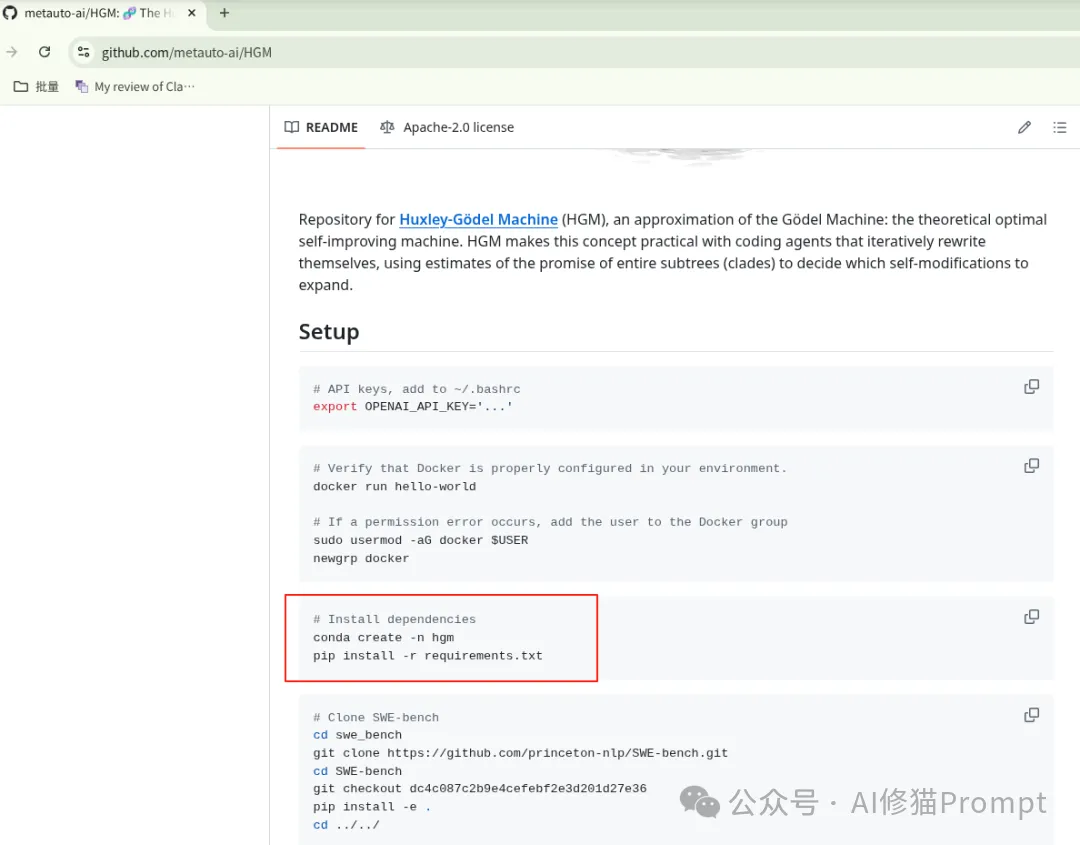
关键的第一次运行(巨坑预警!):这是最关键,也是我们耗时最长的一步,请务必记住:这个过程会非常、非常、非常长! 任何中断之后再次运行,都可能会污染数据,再次运行之前,应该先清理环境。
default_agent镜像,也就是初始智能体的运行环境,我看到它花了10分钟;第二个是pb.base.x86_64:latest镜像,是Polyglot测试平台的基础环境。第二个镜像的构建过程日志很少,看起来就像“卡住”了一样,但它其实在后台静默工作20分钟左右。这个时候千万别以为它死了,什么都别动,默默等待~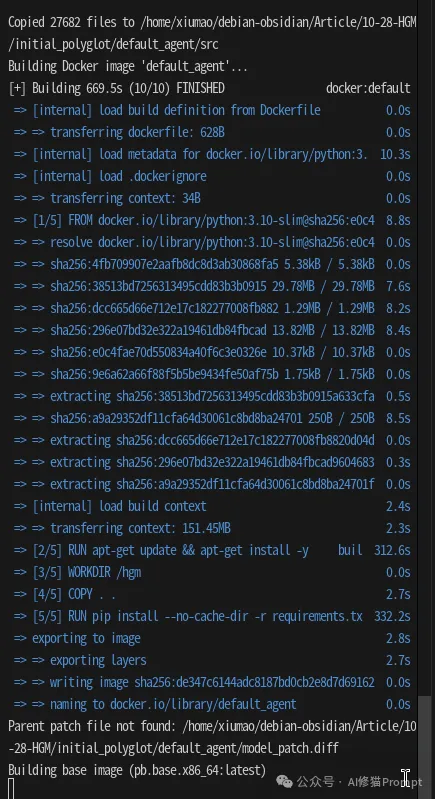
Parent patch file not found或者长时间没有新日志输出时就手动停止它!我们反复遇到的argmax空序列错误,就是因为这个初始化过程被中断,导致初始Agent的评估结果为空,系统找不到可用于进化的“种子”。唯一的办法就是,清理掉不完整的缓存(rm -rf initial_polyglot/default_agent和rm -rf ./hgm_run_test以及docker system prune -af),甚至是清理掉所有未使用的/悬空的Docker镜像(确保Docker处于干净状态),然后重新运行,并耐心等待它自然结束。一个最小化的运行命令:我们最终确定的这个命令,可以作为一个观察HGM行为的“最小化可行进化系统”。它只评估1个任务,我已经改为指定的DeepSeek模型,并将所有结果清晰地输出到./hgm_run_test目录,非常适合用于学习和调试。
python hgm.py \
--polyglot \
--self_improve_llm deepseek-chat \
--downstream_llm deepseek-chat \
--max_task_evals 1 \
--output_dir ./hgm_run_test
如何解读结果
当命令成功结束后,去./hgm_run_test目录寻宝吧。重点关注hgm_outer.log,它记录了整个进化决策的过程。同时,你会看到一个initial目录(初始Agent)和一个或多个用git commit hash命名的目录(进化后的新Agent),通过对比它们内部代码的差异,您就能亲眼见证“代码自己改自己”这个神奇的过程。
本次系列实验的核心目标是完整地运行一次 HGM (Huxley-Gödel Machine) 流程。该流程旨在通过自我演进,不断优化一个基础的“编码代理”(Coding Agent)。整个过程主要包括以下几个阶段:
initial agent)进行性能评估,以建立一个性能基线。deepseek-chat)对“初始代理”的代码进行修改,从而生成一个或多个新的、有望更强的“子代理”。经过多次调试和修复,我最终成功地打通了整个闭环,并完成了一次成功的演进。
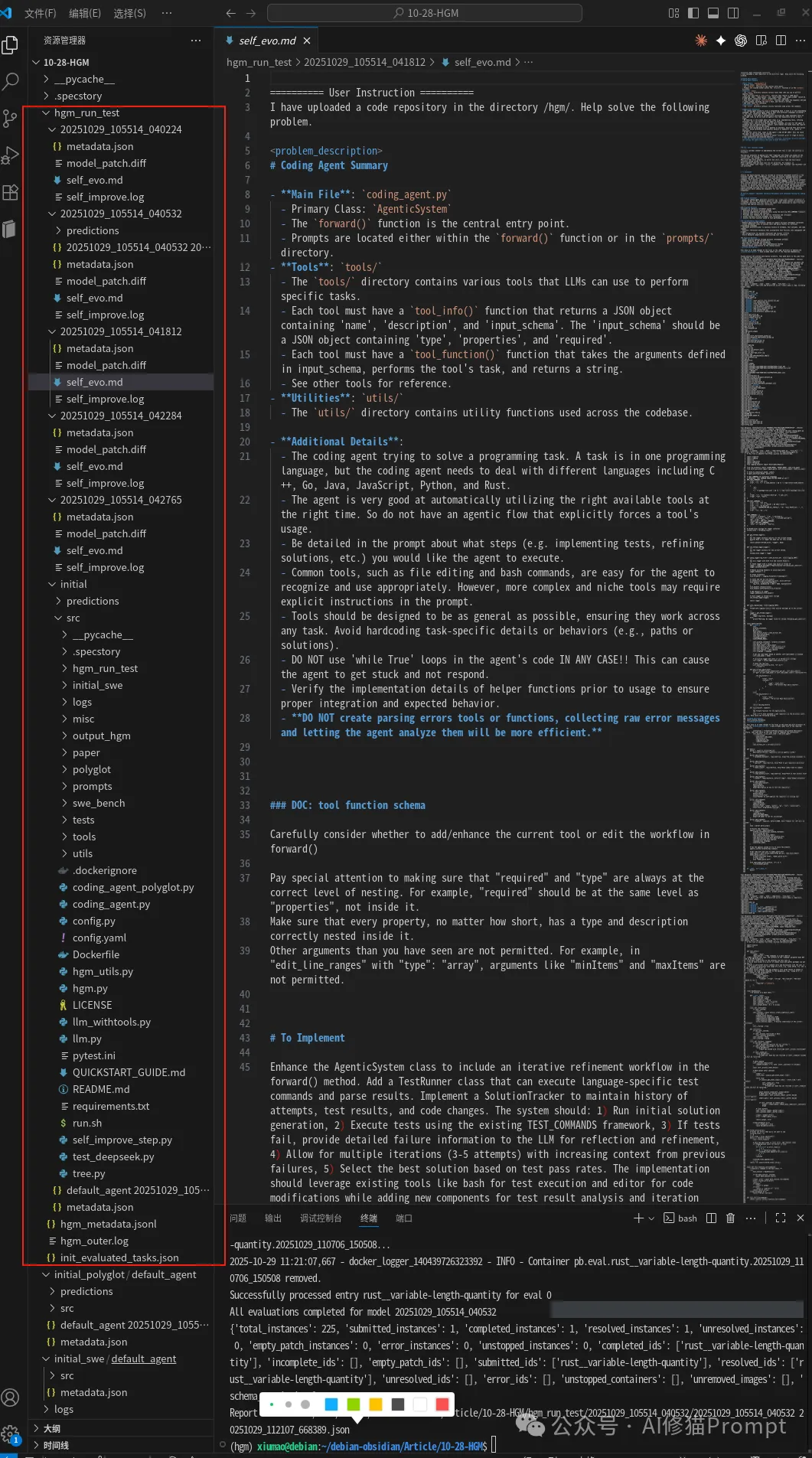
default_agent)的性能。该结果记录在 hgm_run_test/initial/metadata.json 中,是后续所有改进的性能基准。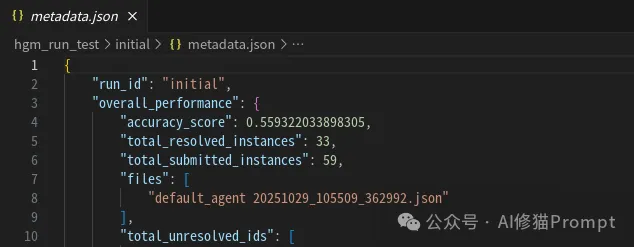
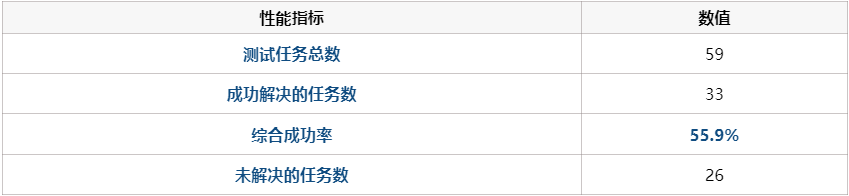
这表明初始代理虽有一定能力,但远未达到理想状态。仍有巨大的优化空间。
本次成功运行完整地执行了一次 HGM 的核心循环,创造并评估了一个新的代理版本。
此阶段的目标是创造一个更强的代理。
java__go-counting 任务作为“灵感”,并接收到了一个高级指令:“增强 bash 工具,增加自动化测试能力”。self_evo.md 文件记录了 deepseek-chat 模型的完整思考链。它通过一系列工具调用,逐步完成了任务:/hgm/ 和 /hgm/tools/ 的目录结构。tools/__init__.py 文件,理解了新工具是如何被自动加载的。/hgm/tools/test_runner.py。生成的精华代码 (/hgm/tools/test_runner.py 的 tool_info 部分):
def tool_info():
return {
"name": "test_runner",
"description": """Automated test discovery and execution framework that:
1. Automatically detects build systems (Gradle, Maven, NPM, etc.) and testing frameworks
2. Identifies test directories and files within the project structure
3. Executes appropriate test commands based on the detected setup
4. Captures and formats test results for easy analysis
5. Handles compilation errors and test failures gracefully
...
""",
"input_schema": {
"type": "object",
"properties": {
"directory": {
"type": "string",
"description": "The directory to analyze and run tests in. Defaults to current directory."
},
"test_type": {
"type": "string",
"enum": ["all", "unit", "integration", "specific"],
"description": "Type of test to run."
},
...
},
"required": ["directory", "test_type"]
},
}
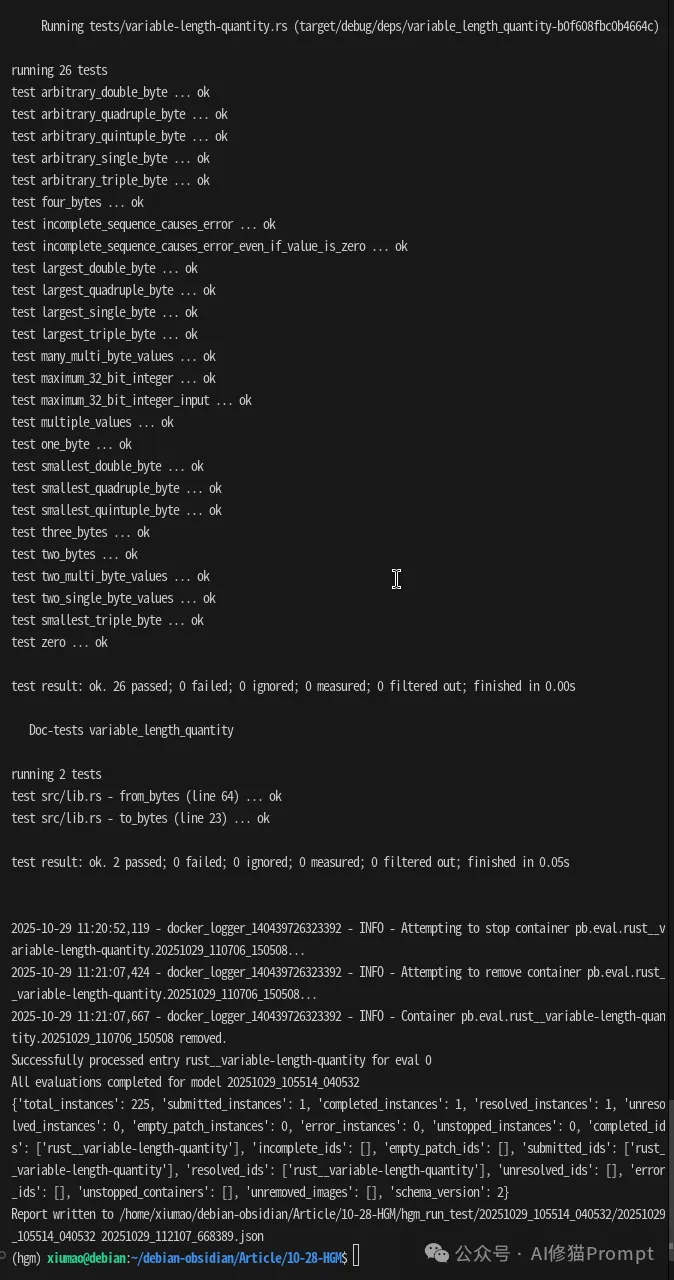
20251029_105514_040532。此阶段的目标是检验新代理的实战能力,这是一个用 Java 任务改进,却在 Rust 任务上测试成功的sample。反映了HGM具有一定的泛化能力。
20251029_105514_040532。rust__variable-length-quantity 任务来对新代理进行测试。20251029_105514_040532/metadata.json 文件记录了完美的评估结果。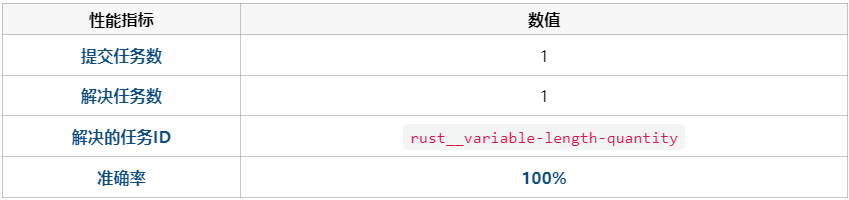
hgm_metadata.jsonl 文件也同步更新,记录了该新代理节点的 mean_utility (平均效用) 为 1.0,这在算法中是一个高分。
本次系列实验最终取得了圆满成功,其核心价值体现在以下几点:
deepseek-chat 模型具备强大的代码理解和生成能力。它不仅能解决具体的编程问题,还能通过工具使用来完成对项目架构的修改和功能扩展(例如增加一个全新的自动化测试工具),这体现了高水平的 Agentic 能力。HGM项目带给我们的,不仅仅是一个能写代码的Agent。它更是一种在复杂系统中进行“优化”和“探索”的思维方式。对于我们这些开发AI产品的工程师来说,它的思想或许能用在很多地方。
您可以复用其中的核心“编码代理”来解决新的、具体的编程任务,而无需再运行整个耗时较长的演进实验。执行单个任务的核心脚本是 polyglot/run_evaluation.py。这个脚本专门用于评估一个指定的代理在一个或多个指定任务上的表现。通过这种方式,您可以跳过 HGM 的演进和搜索过程,直接利用已有的、最强大的代理来解决您关心的具体问题。
比如,我们在设计一个复杂的Agent或者RAG流程时,是不是也经常陷入“局部最优”?我们可能会满足于当前效果最好的一个版本,而不敢轻易改动,但也许某个不起眼的、效果平平的改动,却能为后续的优化打开一个全新的空间。HGM的“家族评估”思想告诉我们,或许我们应该建立一个评估体系,去追踪一系列连续改动(一个“分支”)的长期效果,而不是仅仅基于单次的A/B测试结果来做决策。当然,这只是比如~
说到底,无论是代码进化,还是产品迭代,或许真正的突破,都来自于那些敢于探索“非最优”路径,并着眼于长期潜力的“育种”智慧。欢迎你来讨论~
[1]: https://arxiv.org/abs/2510.21614
[2]: https://github.com/metauto-ai/HGM
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
