
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!
大模型强化学习新突破——SPO新范式助力大模型推理能力提升!当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。
来自主题: AI技术研报
8544 点击 2025-06-09 11:02
 搜索
搜索
当前,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。DeepSeek R1、Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。

如果细究DeepSeek开源席卷的行业巨变,云厂商无疑是最适合讲述AI故事的主角。几个月过去,分析师们迫切地想检验这场新变革的成果,纷纷在5月各家大厂召开的财报电话会议上追问进展。

苹果最新大模型论文,在AI圈炸开了锅。 有人总结到:苹果刚刚当了一回马库斯,否定了所有大模型的推理能力。
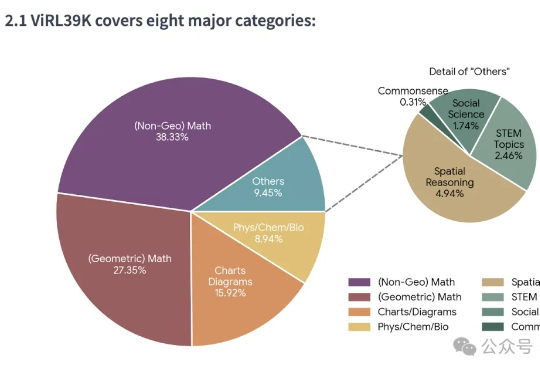
在文本推理领域,以GPT-o1、DeepSeek-R1为代表的 “慢思考” 模型凭借显式反思机制,在数学和科学任务上展现出远超 “快思考” 模型(如 GPT-4o)的优势。
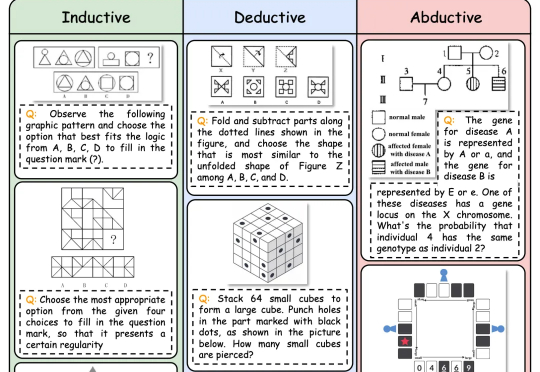
逻辑推理是人类智能的核心能力,也是多模态大语言模型 (MLLMs) 的关键能力。随着DeepSeek-R1等具备强大推理能力的LLM的出现,研究人员开始探索如何将推理能力引入多模态大模型(MLLMs)
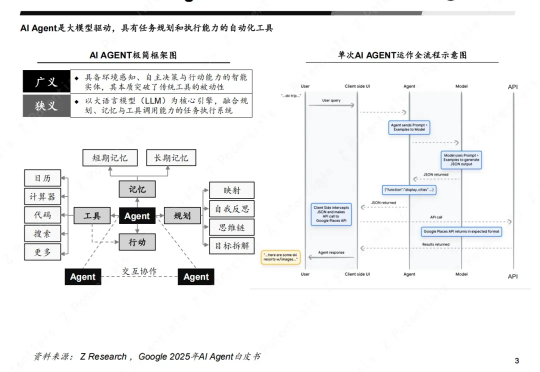
我们拆解AI Agent的运作流程,包括感知层、决策层和执行层。
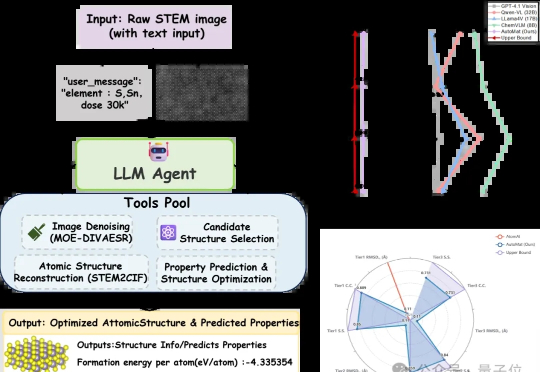
AI Agent又解锁了一个领域!清华大学牵头,与西北工业大学以及上海AI lab等机构推出了电镜领域的AI agent——AutoMat。

如果要问近期最火热的AI硬件品类是什么,AI眼镜一定榜上有名。

如今的新浪,已经被DeepSeek全面重塑了!新浪新闻推出AI辅助工具「智慧小浪」帮我们看新闻,更高效、更深度。同时,微博的「评论罗伯特」的人味也是噌噌up,爆梗频出、妙语连珠。
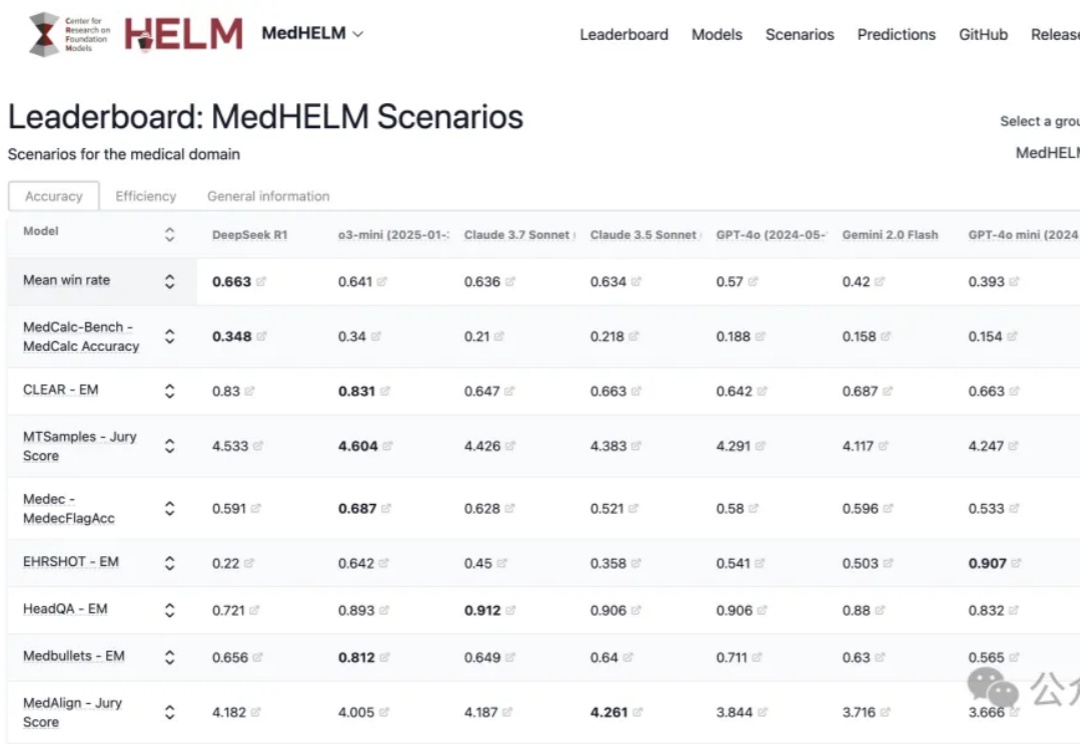
斯坦福最新大模型医疗任务全面评测,DeepSeek R1以66%胜率拿下第一!