
DeepSeek第五天开源猛料,3FS并行文件系统榨干SSD!6.6 TiB/s吞吐量堪比光速
DeepSeek第五天开源猛料,3FS并行文件系统榨干SSD!6.6 TiB/s吞吐量堪比光速DeepSeek最后一天,送上了3FS文件并行系统,以及数据处理框架Smallpond。五天开源连更,终于画上了完美的句号。
来自主题: AI技术研报
5118 点击 2025-02-28 15:16
 搜索
搜索
DeepSeek最后一天,送上了3FS文件并行系统,以及数据处理框架Smallpond。五天开源连更,终于画上了完美的句号。

DeepSeek开源周的最后一天,迎来的是支撑其V3/R1模型全生命周期数据访问需求的核心基础设施 — Fire-Flyer File System(3FS) 和构建于其上的Smallpond数据处理框架。

DeepSeek开源周,今日正式收官!内容依旧惊喜且重磅,直接公开了V3和R1训练推理过程中用到的文件系统。Fire-Flyer文件系统(简称3FS,第三个F代表File),一种利用现代SSD和RDMA网络的全部带宽的并行文件系统;
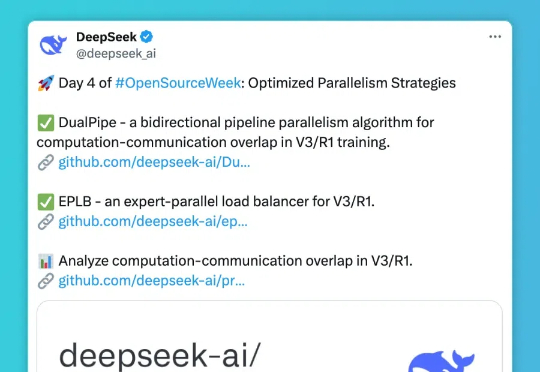
第四天,DeepSee发布包括三个主要项目: DualPipe- 一种用于 V3/R1 训练的双向流水线并行算法,实现计算和通信完全重叠; EPLB(Expert Parallelism Load Balancer) - 专为 V3/R1 设计的专家并行负载均衡器; Profile-data- 分析 V3/R1 中计算与通信重叠的性能数据集。

按时整活!DeepSeek开源周第四天,直接痛快「1日3连发」,且全都围绕一个主题:优化并行策略。
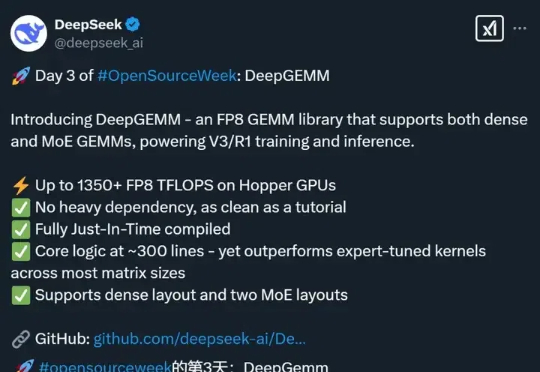
DeepSeek 的开源周已经进行到了第三天(前两天报道见文末「相关阅读」)。今天开源的项目名叫 DeepGEMM,是一款支持密集型和专家混合(MoE)GEMM 的 FP8 GEMM 库,为 V3/R1 的训练和推理提供了支持,在 Hopper GPU 上可以达到 1350+ FP8 TFLOPS 的计算性能。
AI开源潮涌现,推理模型成主流。
DeepSeek开源第二弹如期而至。这一次,他们把MoE模型内核库开源了,支持FP8专为Hopper GPU设计,低延迟超高速训练推理。

DeepSeek开源第二弹如期而至。这一次,他们把MoE训推EP通信库DeepEP开源了,支持FP8专为Hopper GPU设计,低延迟超高速训练推理。
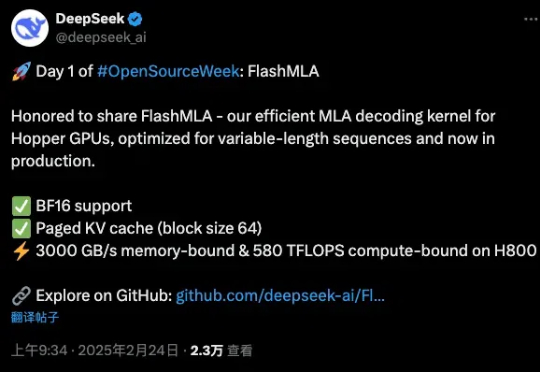
刚刚,万众瞩目的DeepSeek,开源了他们第一天的项目。FlashMLA是一款面向Hopper GPU的高效MLA解码内核,并针对可变长度序列的服务场景进行了优化。