Mythos阴影里谷歌悄悄发模型DiffusionGemma,速度暴涨4倍
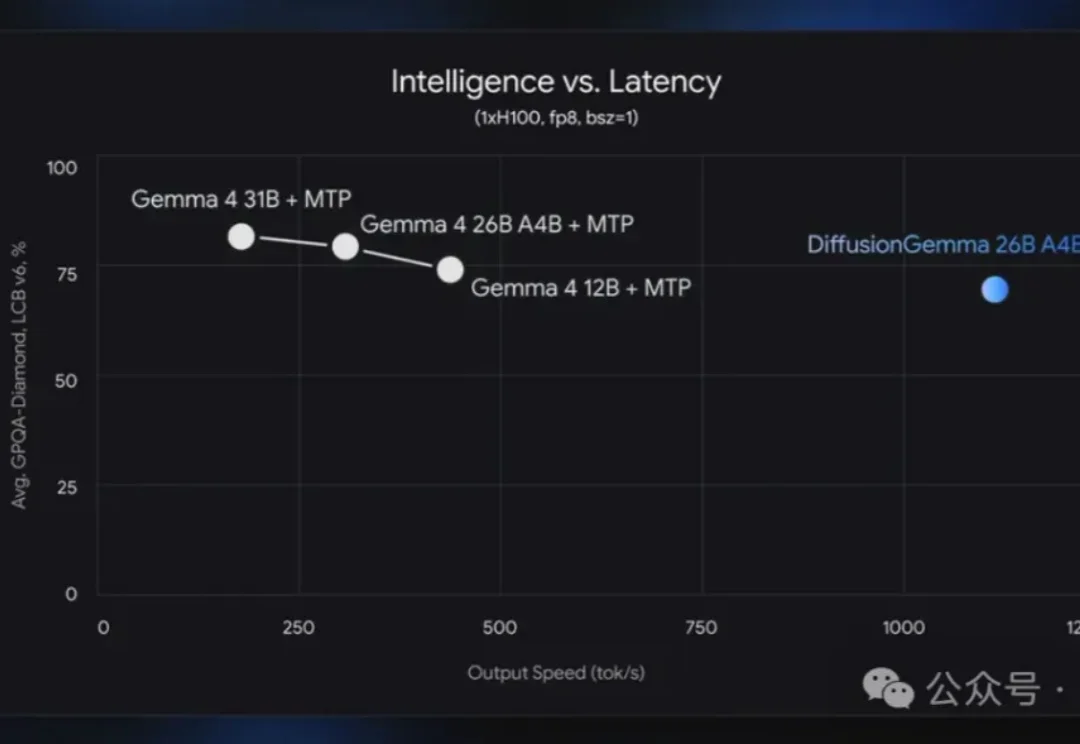
Mythos阴影里谷歌悄悄发模型DiffusionGemma,速度暴涨4倍就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——
来自主题: AI资讯
9537 点击 2026-06-11 15:27
 搜索
搜索
就在刚刚,谷歌闷头干了件大事:把生成图片的扩散模型,拿来写文字了,而且一出手就是4倍加速。 新模型名为DiffusionGemma,它直接抛弃了传统自回归那套“逐Token生成”的打字机模式,而是像“印刷机”一样工作——

Dario Amodei 又写长文了。
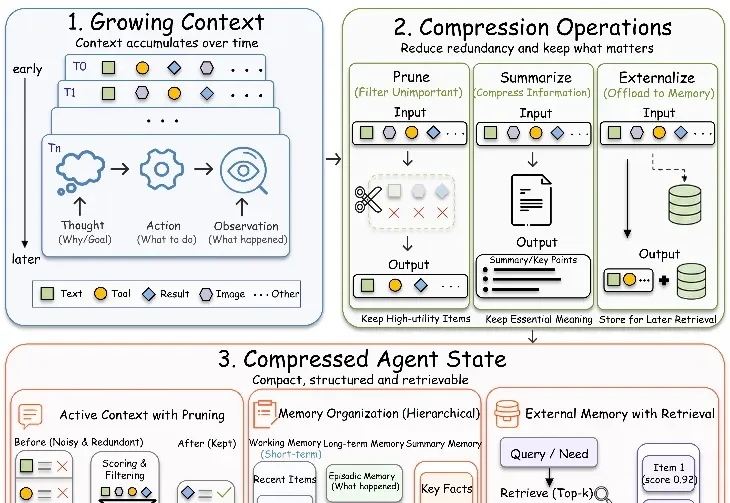
LLM Agent 做长任务时,真正让人头疼的往往不是模型不会推理,而是上下文开始失控:前几步还很清楚,后面就忘约束、丢状态、重复试错,最后把任务跑成事故现场。

今天一早,谷歌又发新模型了!

靠盘活4600个节点,做到“中国第一”。
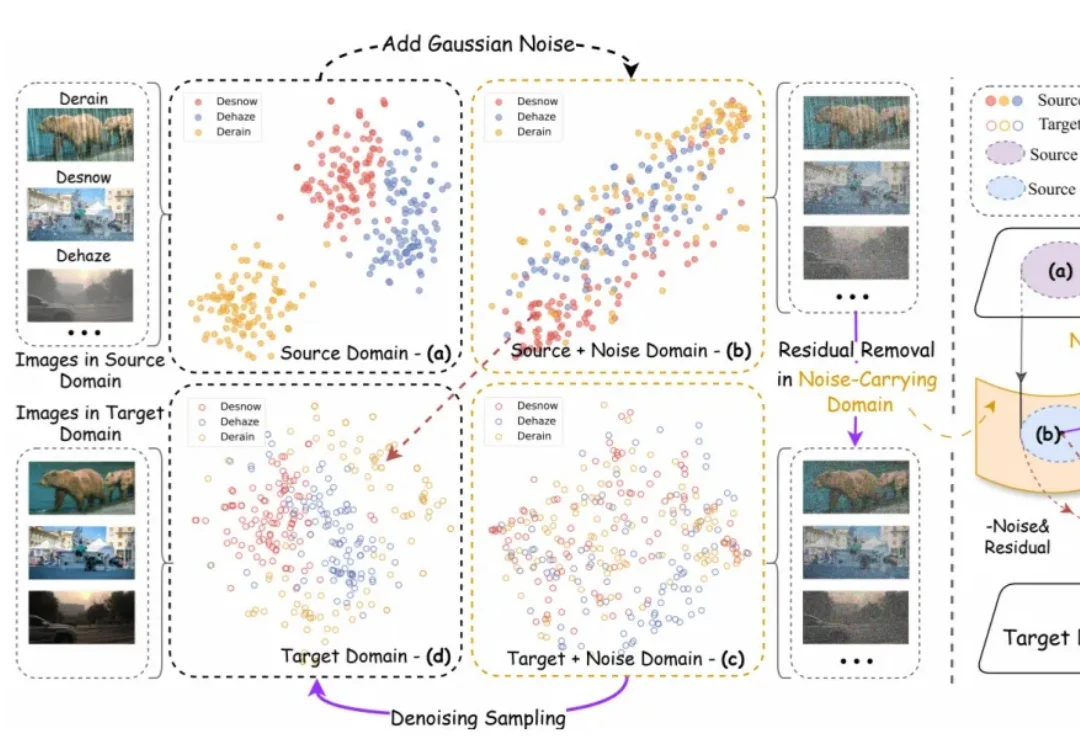
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。

顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。
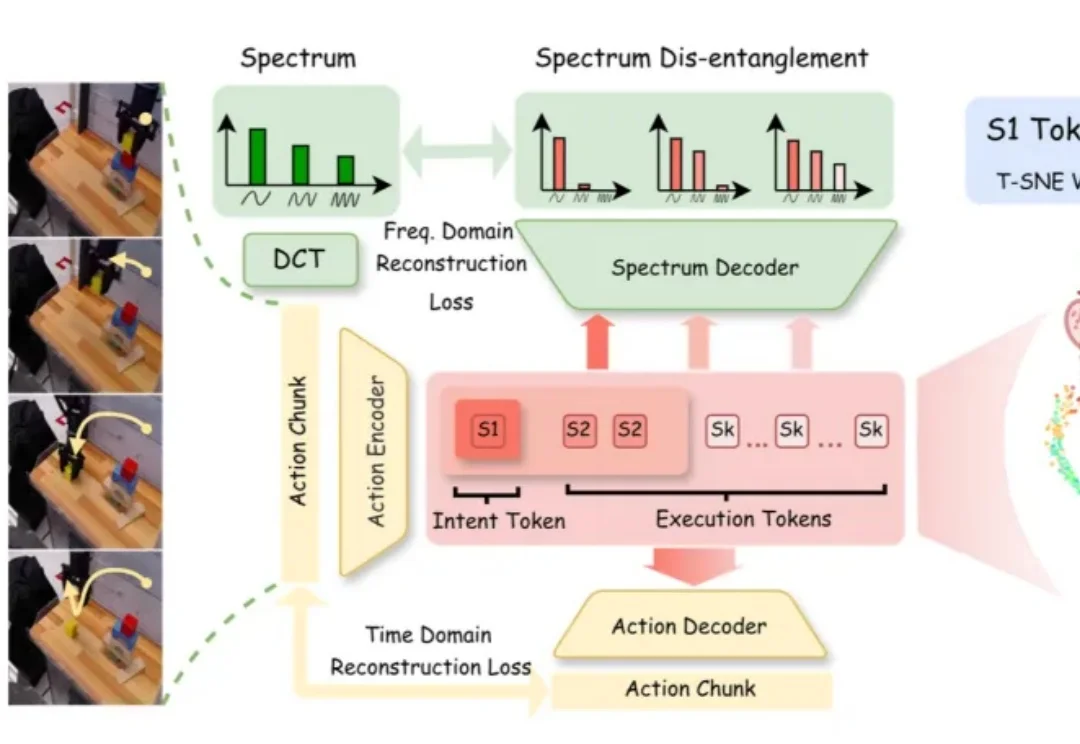
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。
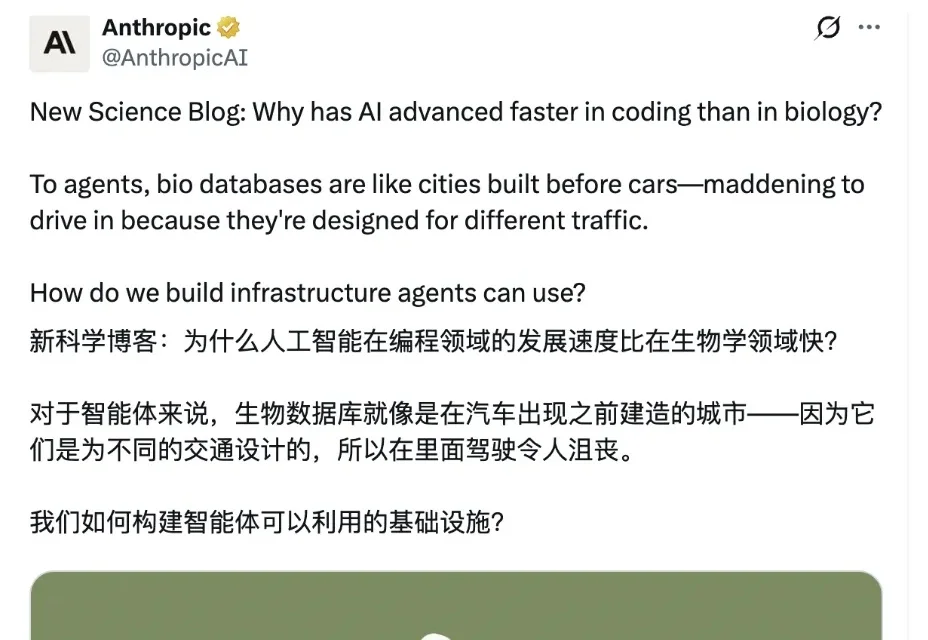
当前,Coding Agents 在软件工程领域一路高歌猛进,科学家们看到此场景,也不禁寄予厚望:AI 智能体何时能以同样的速度,帮人类攻克药物设计、病毒监控与生物学建模的重重难关?

几经波折之后,我们终于将手里的几台 iPhone 都更新到了 iOS 27,体验到了五年以来最重大的一次 Siri 更新。