
你忽悠 AI 的样子,颇有你老板忽悠你时的风采
你忽悠 AI 的样子,颇有你老板忽悠你时的风采一开始,忽悠 AI 挺简单。
来自主题: AI资讯
9329 点击 2026-06-17 09:53
 搜索
搜索
一开始,忽悠 AI 挺简单。

刚刚,据外媒The Information援引两名知情人士报道,DeepSeek近期已完成成立以来的首轮外部融资,募资总额超500亿元人民币(折合74亿美元),本轮融资采用特殊交易架构。这是中国AI行业迄今规模最大的单轮融资。

Agent + 无限画布带来的想象力。

前阿里 Qwen 技术负责人林俊旸的创业公司,有了新消息。据外媒 The Information 援引知情人士的消息,在林俊旸完成的首轮融资中,腾讯投资了 2000 万美元。本轮融资总额达数亿美元,投后估值约 20 亿美元。

我们在上周五开源了 MiniMax M3 模型权重,同步发布了 MSA(MiniMax Sparse Attention)技术论文。MSA 的架构设计让 M3 在长上下文下的计算成本大幅降低,论文中完整披露了架构与工程实现细节。

Fable 5被禁用,美国政府指Anthropic态度敷衍,Anthropic坚称是孤立事件。Dario把技术比作核弹,如今却因不愿关闭系统而陷入绝境,把美国整个AI行业拉下水。

就在昨天,外媒The Information爆料——前阿里巴巴千问大模型负责人林俊旸创办的AI实验室已经完成首轮融资,融资总额达数亿美元,投后估值达20亿美元!其中,红杉中国、高榕资本各投1亿美元领投,互联网巨头腾讯狂掷2000万美元跟投。
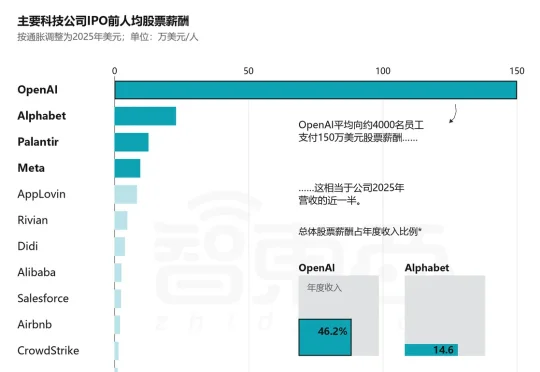
据外媒The Information昨日报道,过去5年间,OpenAI和Anthropic的早期员工及投资者已通过私下股份出售合计套现约140亿美元(约合人民币950亿元)。这一轮员工造富潮正值AI行业IPO竞赛全面升温。6月12日,SpaceX以1.75万亿美元估值登陆纳斯达克,成为这波超级IPO潮中第一个落地的案例。而在此之前,SpaceX至少已连续5年安排员工减持。
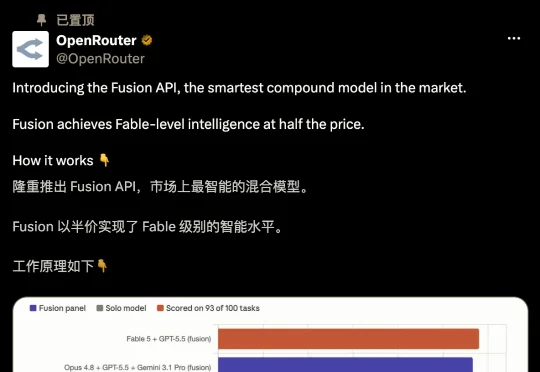
OpenRouter 上线了一个叫 Fusion 的新功能,把同一道题丢给一组模型,再让一个裁判模型把答案揉成一份。结果是,几个便宜的开源模型组起团来,能直接打平 Fable 5,价格只有其一半。

昨天,AI 圈大都被这一新闻「刷屏」:巴西里约热内卢市政府旗下的一家 IT 公司,平地一声雷地推出一款名为「Rio 3.5」397B 的开源模型,甚至还一路逆袭杀进了全球第一梯队,超越 Qwen 3.7 Plus 等开源模型,在多项基准测试中斩获 SOTA 性能。