
体验完字节送的迷你AI硬件,后劲有点大...
体验完字节送的迷你AI硬件,后劲有点大...最近也是好起来了,上周四去杭州参加了字节火山的线下meetup开发者大会。在会议现场亲自体验了他们这次新发布的大模型和产品,整个过程还挺有意思的。视觉模型Doubao-1.5-vision-pro也非常nice
来自主题: AI资讯
11002 点击 2025-04-21 17:40
 搜索
搜索
最近也是好起来了,上周四去杭州参加了字节火山的线下meetup开发者大会。在会议现场亲自体验了他们这次新发布的大模型和产品,整个过程还挺有意思的。视觉模型Doubao-1.5-vision-pro也非常nice
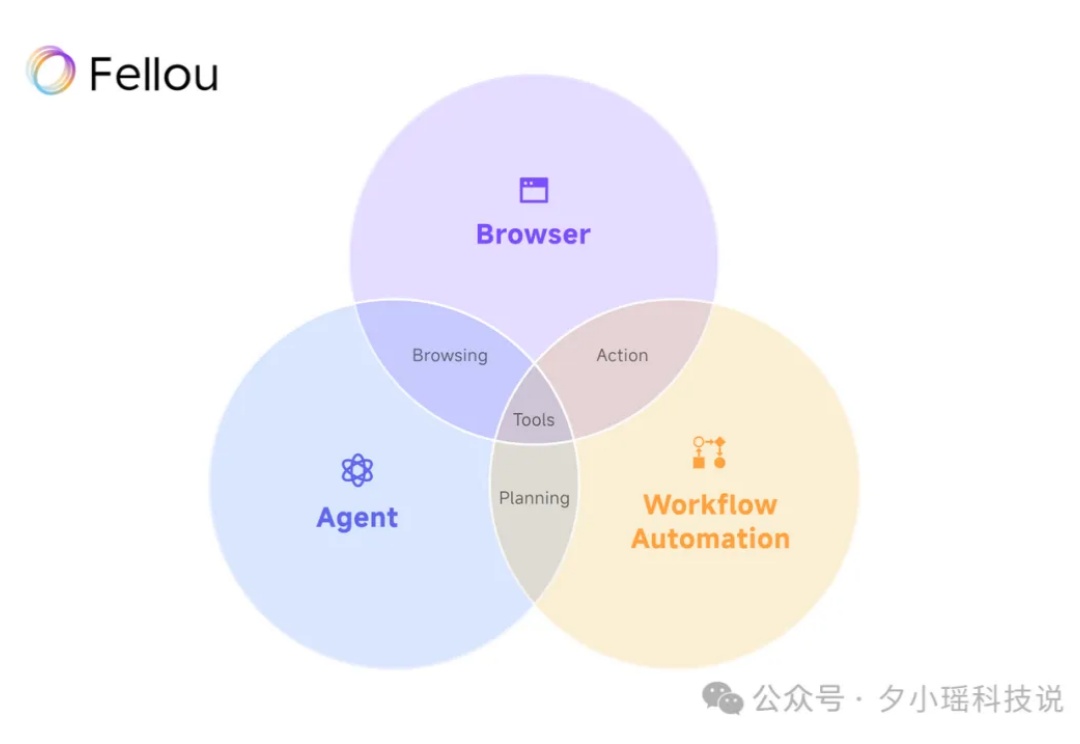
Fellou: 世界首个 Agentic Browser —— 超越浏览,直达行动 Beyond Browsing, Into Action

我们体验了 11 款 AI 游戏后,发现不少开发者在玩法设计上进行了有趣的突破。比如一些游戏通过让 AI 与玩家一起玩“你画我猜”,但与常理不同的是AI猜玩家画,让原本简单的游戏变得充满意外和笑点;也有像《萌爪派对》这样的游戏,把 AI 角色当作宠物一样培养,玩家和 AI 互动时,能看到角色“成长”,甚至随着时间的推移产生不同的变化。
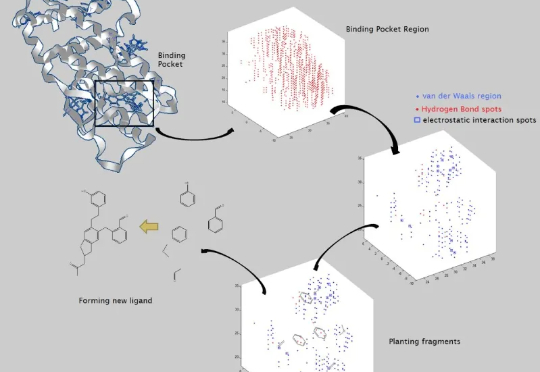
当前,人们对人工智能驱动的药物发现公司(以下简称 AIDD)这一新兴公司确发有效的界定。2025年开年,DeepSeek的爆火为AI医疗和AI制药领域带来了多维度变革。近日,BioPharma Trend发表了一份AI制药研究报告,报告力图从各个维度回答AI对生物医药的关键价值。
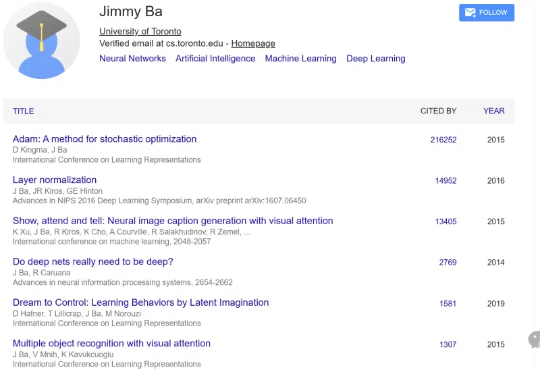
ICLR 2025时间检验奖重磅揭晓!Yoshua Bengio与华人科学家Jimmy Ba分别领衔的两篇十年前论文摘得冠军与亚军。一个是Adam优化器,另一个注意力机制,彻底重塑深度学习的未来。

就在刚刚,智谱一口气上线并开源了三大类最新的GLM模型:沉思模型GLM-Z1-Rumination 推理模型GLM-Z1-Air 基座模型GLM-4-Air-0414

本文作者刘圳是香港中文大学(深圳)数据科学学院的助理教授,肖镇中是德国马克思普朗克-智能系统研究所和图宾根大学的博士生,刘威杨是德国马克思普朗克-智能系统研究所的研究员,Yoshua Bengio 是蒙特利尔大学和加拿大 Mila 研究所的教授,张鼎怀是微软研究院的研究员。此论文已收录于 ICLR 2025。

GitHub 在其 Copilot 功能中引入了一项基于 AI 的密码扫描功能,该功能已经整合到 GitHub Secret Protection 中。
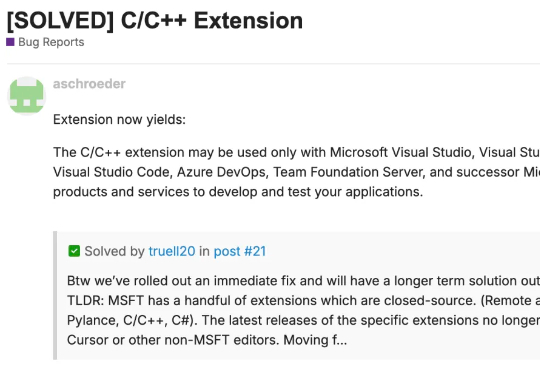
微软某个 VSCode 语言服务扩展中,位于 nativeStrings.json 文件第 485 行的一行代码,打破了它与 Cursor 的兼容性。该条款规定:“C/C++ 扩展仅可与 Microsoft Visual Studio、Visual Studio for Mac、Visual Studio Code、Azure DevOps、Team Foundation Server
由 Founders Fund 支持的旧金山初创公司 Cognition AI 于 2024 年初发布 Devin。