
云计算一哥,让小鹏、Kimi和猎豹都爽了一把
云计算一哥,让小鹏、Kimi和猎豹都爽了一把有这么一组数据,是真真儿地戳到了用Agent这件事的爽点。
来自主题: AI资讯
7078 点击 2026-06-24 16:04
 搜索
搜索
有这么一组数据,是真真儿地戳到了用Agent这件事的爽点。
自从上次介绍过 Kimi Work 外加 Fable 无情下线之后,我发现我还真越来越频繁地在使用这个桌面端 APP 了。当然模型能力只是一方面,关键桌面 APP 比起网页来说,在使用上还是要方便得太多了……而且也不用关心网络切来切去啥的。
近日,有消息称,曾一手搭建米哈游全球发行体系的金雯怡于两周前已正式加入月之暗面(Moonshot AI),执掌 Kimi 相关业务。早在她 4 月底官宣从米哈游离职时,业内便有不少声音猜测,这位深耕游戏全球化近十年的高管,最终会奔赴 AI 赛道。

最近几天,一个 3B 的小模型在 X 上火了,因为在一些难度可验证的推理任务上(比如编程),它进入了 Gemini 3 Pro、GPT-5 high、Claude Opus 4.5、GLM-5、Kimi K2.5 等前沿模型的性能区间,而它的体积远小于这些模型。
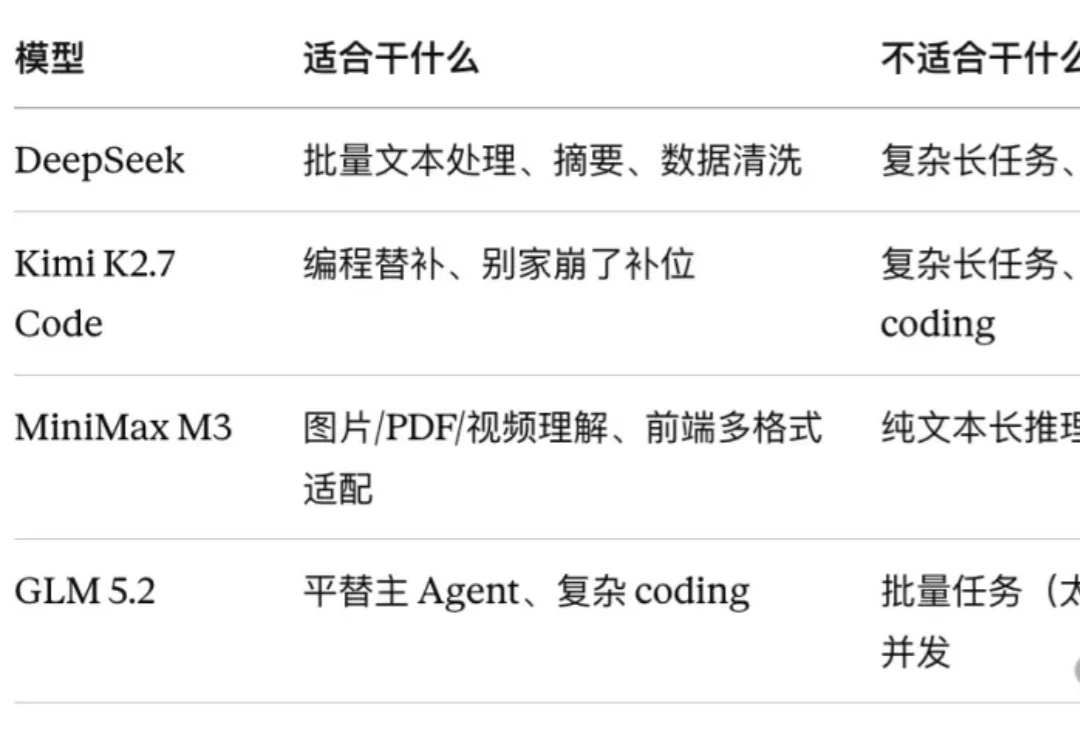
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。
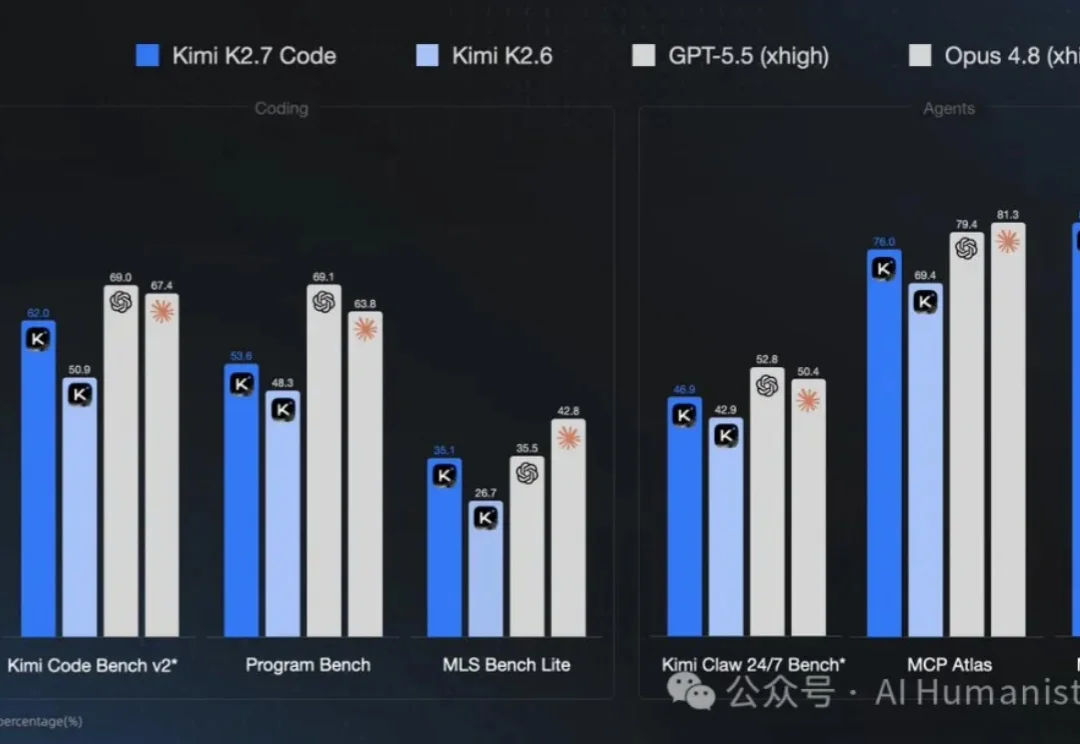
昨天 Kimi K2.7 Code 高速版 上线了,我上手试了下,最大的感受就一个字:快。

朋友们,Kimi 又更新了。
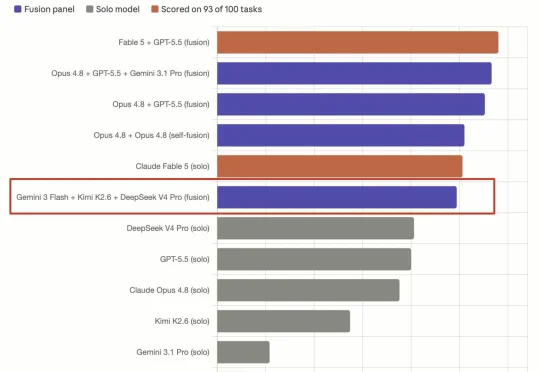
最新测试显示,模型抱团后实力明显升级:Opus 4.8+GPT-5.5>Fable 5;Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash=Fable 5。能力追上了,开销还减半。根据官方定价,相比Fable 5,Kimi K2.6+ DeepSeek V4 Pro+Gemini 3 Flash这套平价阵容,成本降幅接近80%。
今天,月之暗面发布并开源Kimi K2.7 Code编程模型,参数量达1.1万亿,提供256K上下文窗口。这一模型重点提升了长上下文编程场景的指令遵循能力、长程编程任务的性能表现,并且大幅改善了在长程任务中的过度思考倾向,平均token消耗减少30%。