
超全推理语言模型蓝图来了!揭开o1、o3、DeepSeek-V3神秘面纱
超全推理语言模型蓝图来了!揭开o1、o3、DeepSeek-V3神秘面纱ETH Zurich等机构提出了推理语言模型(RLM)蓝图,超越LLM局限,更接近AGI,有望人人可用o3这类强推理模型。
来自主题: AI技术研报
8472 点击 2025-01-28 12:20
 搜索
搜索
ETH Zurich等机构提出了推理语言模型(RLM)蓝图,超越LLM局限,更接近AGI,有望人人可用o3这类强推理模型。
科技媒体 testingcatalog 今天(1 月 27 日)发布博文,报道称 xAI 官方虽然尚未公布,但 Grok-3 已短暂现身独立平台和 X 平台,开启内部测试,有望下周正式发布。
视觉版o1的初步探索,阶跃星辰&北航团队推出“慢感知”。研究人员认为:1)目前多模领域o1-like的模型,主要关注文本推理,对视觉感知的关注不够。2)精细/深度感知是一个复杂任务,且是未来做视觉推理的重要基础。

OpenAI的新Scaling Law,含金量又提高了。

赶在放假前,支棱起来的国产 AI 大模型厂商井喷式发布了一大堆春节礼物。前脚 DeepSeek-R1 正式发布,号称性能对标 OpenAI o1 正式版,后脚 k1.5 新模型也正式登场,表示性能做到满血版多模态 o1 水平。

人大清华团队提出Search-o1框架,大幅提升推理模型可靠性。尤其是「文档内推理」模块有效融合了知识学习与推理过程,在「搜索+学习」范式基础上,使得模型的推理表现与可靠性都更上一层楼。
早上MiniMax上线TTS,字节上线AI编程Trae;下午字节全量上线豆包实时语音;晚上DeepSeek开源R1性能直接对标OpenAI o1,然后Kimi的k1.5直接正面硬刚。昨天的余温还没过,今天下午,腾讯混元又悄悄开了个闭门发布会,作为混元的老基友,我自然是受邀参加期期不落。
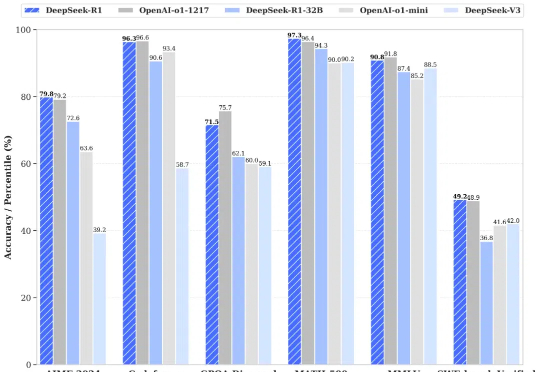
昨天晚上,DeepSeek 又开源了 DeepSeek-R1 模型(后简称 R1),再次炸翻了中美互联网: R1 遵循 MIT License,允许用户通过蒸馏技术借助 R1 训练其他模型。 R1 上线 API,对用户开放思维链输出 R1 在数学、代码、自然语言推理等任务上,性能比肩 OpenAI o1 正式版,小模型则超越 OpenAI o1-mini
中国版o1刷屏全网。DeepSeek R1成为世界首个能与o1比肩的开源模型,成功秘诀竟是强化学习,不用监督微调。AI大佬们一致认为,这就是AlphaGo时刻。
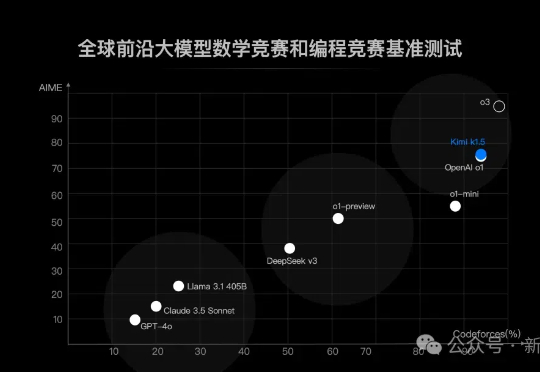
来了来了,月之暗面首个「满血版o1」来了!这是除OpenAI之外,首次有多模态模型在数学和代码能力上达到了满血版o1的水平。